Praten over wat er in onze tijd is informatie technologieën en de eindeloze groei van de hoeveelheid gegevens die zowel voor een individuele persoon als voor de samenleving beschikbaar is, zijn er veel problemen met het verwerken van informatie en het zoeken ernaar - dit is al godslastering. Wie alleen niet dit onderwerp aan de orde stelt. En om u niet te belasten met subjectieve en deels objectieve oordelen die uit verschillende informatie bronnen met betrekking tot het probleem, zal ik direct naar de oplossing gaan. Laten we het vandaag hebben over zoeken. Dat wil zeggen, over programma's en serieuze informatiesystemen die zoeken naar de documenten en gegevens die we nodig hebben.
Upgrade "direct zoeken"
Nog niet zo lang geleden, toen de bomen groot waren en er niet zoveel informatie was, zelfs niet in het lokale netwerk van de onderneming, werd elke zoekopdracht uitgevoerd door een banale opsomming van een handvol beschikbare bestanden en sequentiële controle van hun namen en inhoud. Zo'n zoekopdracht wordt direct zoeken genoemd en programma's (hulpprogramma's) die gebruikmaken van direct search-technologie zijn traditioneel aanwezig in alle besturingssystemen en toolpakketten. Maar zelfs de kracht van moderne computers is niet genoeg voor een snelle en adequate zoektocht in gigantische hoeveelheden data tijdens direct zoeken. Zoeken in een paar honderd documenten op een schijf en zoeken in een enorme bibliotheek en enkele tientallen mailboxen zijn twee verschillende dingen. Daarom verdwijnen directe zoekprogramma's tegenwoordig duidelijk naar de achtergrond - als we zijn aan het praten over universele middelen.
In het bedrijfsleven is dit type zoekopdracht natuurlijk al lang niet meer in trek. Volumes zijn niet hetzelfde. En daarom voor vele jaren, en in De laatste tijd ondubbelzinnig, technologieën die in staat zijn om snel en exact zoeken documenten van verschillende formaten en van verschillende bronnen zijn meer dan relevant. Nog niet zo lang geleden was "papa" Microsoft Bill Gates, blijkbaar jaloers op het fenomenale succes van internet Google-zoekmachine, op een van de persconferenties, kondigde hij de wens van de software (al en niet alleen) op alle mogelijke manieren aan om de creatie van zoekmachines en technologieën te promoten, ontwikkelen en verdiepen. Maar voordat er een fenomenaal werkend programma van Microsoft of een concurrerende server op internet wordt gemaakt, is het nog te vroeg (MSN schiet nog steeds tekort bij Google). Daarom grijpen we in op bestaande ontwikkelingen. Index, zoekopdracht, relevantie
In de kern moderne technologieën er zijn twee fundamentele processen. De eerste is indexeren. beschikbare informatie en het verwerken van het verzoek en het vervolgens weergeven van de resultaten. Wat het eerste betreft, elk programma (of het nu een desktopzoekmachine, een bedrijfsinformatiesysteem of een internetzoekmachine is) creëert zijn eigen zoekgebied. Dat wil zeggen, het verwerkt documenten en vormt een index van deze documenten (een georganiseerde structuur die informatie bevat over de verwerkte gegevens). In de toekomst is het de aangemaakte index die voor werk wordt gebruikt - snel een lijst met benodigde documenten verkrijgen op basis van het verzoek. Verder, hoewel zeker niet eenvoudig in termen van technologie, maar het is heel begrijpelijk gewone gebruiker. Het programma verwerkt het verzoek trefwoord zin) en geeft een lijst weer met documenten die deze wachtwoordzin bevatten. Omdat de informatie is opgenomen in een gestructureerde index, is de queryverwerking veel (tientallen en honderden keren!) Sneller dan in het geval van direct zoeken (documentselectie wordt niet uitgevoerd door bestanden op te sommen, maar door tekstinformatie in de inhoudsopgave).
Het programma toont de gevonden documenten in de resulterende lijst volgens relevantie - de overeenkomst van het document met de vraagtekst. IN verschillende technologieën, natuurlijk zijn er verschillende methoden om de relevantie van een document te zoeken en te bepalen (het aantal "voorkomen" van een woord en de frequentie van vermelding in het document, de verhouding van deze parameters tot het totale aantal woorden in het document , de afstand tussen de woorden van de zoekterm in de gezochte bestanden, enzovoort). Op basis van deze parameters wordt het "gewicht" van het document bepaald en, afhankelijk daarvan, verschijnt een of ander bestand op een bepaalde positie in de resultatenlijst. In het geval van zoeken op internet is de situatie nog ingewikkelder. Immers, in deze zaak veel andere factoren moeten in aanmerking worden genomen (Google's Page Rank is een voorbeeld). Maar dit is een onderwerp voor een apart artikel, dus we zullen het internet niet aanraken.Overzicht van zoekmachines
Dit artikel bespreekt de mogelijkheden van verschillende populaire zoekprogramma's die zowel fatsoenlijke snelheden als goede functionaliteit bieden. Maar pronken in een flyer is één ding, maar opstaan tegen de blik van een expert is iets anders. En er waren niet veel of weinig experts, een volledig kantoor van liefhebbers om de software op te halen voor zijn bruikbaarheid. Op een testcomputer (Athlon 2,2 MHz, 1 GB RAM, 160 GB IDE hard Seagate-station bij 7200 rpm en Windows XP) is een reeks programma's geïnstalleerd: dtSearch Desktop, Snoop Prof Deluxe, Google Bureaublad zoeken, SearchInform, Copernic Desktop Search, ISYS Desktop. Voor tests werd een tekstbestand van documenten samengesteld in de formaten doc, txt en html algemeen de grootte is niet meer of minder, maar 20 gigabyte. Een groep kameraden, onder leiding van uw nederige dienaar, testte, vergeleek en deelde hun subjectieve indrukken over elke software. Hieronder leest u een samenvatting van de bevindingen. dtSearchDesktop
Een programma dat volgens de ontwikkelaars claimt de snelste, handigste en beste zoekmachine te zijn. Zoals, in het algemeen, en de rest van deze recensie. De interface van dtSearch is vrij eenvoudig, maar sommige vensters of tabbladen zijn enigszins overladen met elementen, wat de indruk wekt moeilijk te gebruiken te zijn. Maar in feite zijn er geen speciale moeilijkheden. Het enige echt onaangename moment is het gebrek aan ondersteuning voor de Russische taalsoftware (ondanks het feit dat het programma naar documenten in verschillende talen kan zoeken, is de interface uitsluitend Engels).
Maar dtSearch is een van de weinige programma's die webpagina's kan indexeren tot een "diepte" gespecificeerd door de gebruiker (echter rekening houdend met de "extra aankoop" in de dtSearch Spider add-on kit). Dit is een aanvulling op het ondersteunen van bestanden op schijf in verschillende tekstformaten en e-mails van post Outlook-inbox. Tegelijkertijd weet het programma niet hoe het moet werken met databases, die zo'n lekker hapje zijn voor zoekmachines vanwege grote volumes informatie die ze bevatten, en wijdverbreide verspreiding in bedrijven, en dus in bedrijfsnetwerken. De indexeringssnelheid van dtSearch-documenten was op peil. Vooruitkijkend zal ik zeggen dat dit programma een bepaalde hoeveelheid informatie op een niveau kon indexeren met een andere deelnemer - iSYS - en de tweede plaats met hem deelde in de lijst van de snelste systemen. Test 20 gigabyte aan informatie dtSearch geïndexeerd in 6 uur en 13 minuten, en creëer een index van 7,9 GB voor de behoeften van latere zoekopdrachten.
Wat betreft de zoekmogelijkheden, ze zijn hier aan het juiste adres. Ten eerste heeft dtSearch een morfologische zoekfunctie (zoek naar een woord in al zijn morfologische vormen). Door deze gelegenheid te gebruiken, bevrijd je jezelf van bijvoorbeeld gedachten als "in welk geval werd een bepaald woord gebruikt in het document dat ik nodig heb?". Het gebruik van morfologisch zoeken is bijna altijd gerechtvaardigd, dus het zou in elke professionele zoekmachine aanwezig moeten zijn.
Geluid zoeken is niet-standaard kans zelfs voor professionele zoekmachines. De essentie ligt in het feit dat het programma zoekt naar woorden die hetzelfde klinken als het woord dat je hebt ingevoerd. En het beste is dat deze functie ook voor de Russische taal werkt! Als u bijvoorbeeld het woord 'oor' in een zoekopdracht typt, krijgt u niet alleen de woorden 'oor', maar ook 'oor'.
Foutcorrigerend zoeken is een zeer belangrijke functie. Het wordt gebruikt om te zoeken naar woorden die syntactische fouten bevatten - dit kunnen typefouten zijn of fouten in documenten die zijn verkregen met bijvoorbeeld tekenherkenningssystemen. Een eenvoudig voorbeeld is dat u op zoek bent naar het woord toetsenbord. Sommige documenten bevatten het woord "toetsenbord", het is duidelijk dat dit woord in feite "toetsenbord" is, gewoon een persoon die typt tijdens het typen. Nu, foutcorrigerend zoeken, dit zal het document met het woord "toetsenbord" in het resultaat detecteren en opnemen. Ook in dtSearch is er een instelling waarmee u de mate van mogelijke foutieve karakters kunt bepalen.
Zoek op synoniemen. Deze functie gebruikt een lijst met synoniemen voor verschillende woorden. Dus door bijvoorbeeld het woord "snel" in te voeren, vindt het programma ook de woorden "high-speed" en andere die synoniemen zijn voor het woord "fast", indien aanwezig, zijn natuurlijk aanwezig in de lijst met synoniemen . Een kant-en-klare lijst met synoniemen wordt niet meegeleverd met het dtSearch-programma, maar het is mogelijk om de lijsten op internet te gebruiken (er is dus een verbinding vereist, wat niet altijd handig is), of u kunt uw eigen lijst met synoniemen.
behalve vermelde kansen, dtSearch kan zoeken met behulp van woordgroepen die bestaan uit woorden die zijn verbonden door logische bewerkingen. Elk woord in de zoekopdracht kan zijn eigen "gewicht" krijgen, dat wil zeggen betekenis. Een handige optie is om een woordenboek te gebruiken dat bestaat uit onbelangrijke woorden om daar geen rekening mee te houden bij het zoeken, maar ook dit woordenboek is leeg en zul je zelf moeten invullen.
Overweeg vervolgens de mogelijkheden van het programma bij het werken op het netwerk. In feite biedt dtSearch geen specifieke netwerkmogelijkheden. Het is echter heel goed mogelijk om het op het netwerk te gebruiken. Als alternatief kunt u een index maken en deze in een openbare (gedeelde) map plaatsen. Het programma zelf kan voor elke gebruiker op een computer worden geïnstalleerd, of het kan ook in een map worden geplaatst die is geopend voor publieke toegang, en maak op een speciale manier snelkoppelingen voor elke gebruiker afzonderlijk, met behulp van opdrachtregelopties, waarvan het doel wordt beschreven in het helpbestand dat bij het programma wordt geleverd. Ook is er een mogelijkheid automatische installatie programma's op het netwerk met behulp van .msi-bestand. Hierbij wordt rekening gehouden met de instellingen voor elke aangesloten gebruiker.
Over het algemeen - een goed programma uit de categorie van professionele zoekmachines. Kan in aanmerking komen voor goed cijfer dtSearch kan echter vanwege een aantal factoren moeilijk zijn om vertrouwen en respect van gebruikers te krijgen (niet alles is soepel met de interface, Russische gebruikers worden beroofd, nee heldere functies om te netwerken). Wat betreft het rechtstreeks zoeken naar documenten, had het programma geen overlays met Russische tekst. Zoals er geen waren met de aangegeven morfologie, of met een vage zoekopdracht. Het systeem redelijk adequaat gevonden vereiste documenten en door een eenvoudig verzoek in één woord en door een paar alinea's van een document als sleutelzin te gebruiken.
Officiële site:
Distributiegrootte: 23 MbSnoop Prof Deluxe
Op basis van de naam kun je raden dat er ondersteuning is voor de Russische taal in dit programma. Het is al leuk. Wat betreft de interface, deze is over het algemeen enigszins ongebruikelijk, maar ziet er erg aantrekkelijk uit. Een ander ding is gemak. Een zeer controversieel criterium, maar toch is een oplossing met meerdere vensters waarschijnlijk niet de beste optie (het verzoek wordt in het ene venster ingevoerd, het resultaat wordt in een ander venster weergegeven, enz.).
De Bloodhound gebruikt nog steeds dezelfde indexen om snel te zoeken, maar indexeren is veel langzamer dan andere programma's. Dit is heel vreemd, vooral gezien het feit dat het vermogen om zoekopdrachten te verwerken erg zwak is, wat betekent dat de indexstructuur niet ingewikkeld is. Hoogstwaarschijnlijk gaat het hier om niet-geoptimaliseerde algoritmen. Dit programma bleek een duidelijke buitenstaander van indexerings- en zoeksnelheden: de tijd die wordt besteed aan het maken van een index is zes keer langer dan die van hetzelfde dtSearch en iSYS. Het indexeren van 20 gigabyte aan teksten voor een bloedhond resulteerde in 38 uur en 46 minuten werk. En het gecreëerde "zoekgebied" besloeg dezelfde grootte op de harde schijf als de originele gegevens met een kleine min - 19 gigabyte.
De Bloodhound kan gepresenteerd worden als alternatief voor de standaard zoekactie in Windows, meer kan hij haast niet. Het feit dat de primaire taak van de Seeker - het eenvoudigst zoeken naar bestanden, niet alleen wordt aangegeven door een klein aantal functies voor het analyseren van de tekst van zoekopdrachten en een geavanceerd zoeken op bestandskenmerken, maar zelfs door een resultatenvenster dat directe links geeft naar de gevonden bestanden, evenals naar mappen die deze bestanden bevatten. Het resultatenvenster is niet erg informatief in die zin dat u het volledige gevonden bestand alleen kunt lezen door het uit te voeren, dat wil zeggen dat het geen ingebouwde bestandsviewer heeft. Maar er wordt een uittreksel uit het bestand gegeven, waar het gezochte woord werd gevonden, in het algemeen doet zo'n weergaveschema sterk denken aan internetzoekmachines.
Sprekend over de specifieke mogelijkheden voor het verwerken van zoekopdrachten, is het vermeldenswaard dat er niet zoiets bestaat als "zoeken naar tekst", het maximale dat kan worden gezocht is een zin, al was het maar omdat er geen tekstinvoerveld met meerdere regels is. Desalniettemin kunt u de ingevoerde zin analyseren, en de Bloedhond biedt ons hier een standaard zoekset: logische bewerkingen, zoeken op masker en zoeken op citaten ... niet veel. Het programma bevat enkele beginselen van morfologisch zoeken, maar waarschijnlijk zo ruw dat het nogal interfereert correcte werking(tijdens de tests veel overlays met misbruik morfologie).
Maar het programma stelt u in staat om tijdens het zoeken bestandskenmerken (documentdatum, bestandsnaam, mapnaam) op te geven en in deze zoekopdrachten kunt u ook dezelfde zoekset gebruiken. U kunt ook naar berichten zoeken door de parameters op te geven (Van, Onderwerp... enz.).
Dus we hebben de zoektocht zelf uitgezocht, wat is er nog meer interessant aan het programma, waarvoor het zoveel prijzen heeft ontvangen, volgens informatie van de officiële website? Het is moeilijk te zeggen wat er zo speciaal aan is, hoogstwaarschijnlijk is de interface van de Bloodhound bevorderlijk voor zichzelf (alleen uiterlijk, om nog maar te zwijgen van de bruikbaarheid).
Bewerkingen met indexen zijn heel standaard, het leuke is de mogelijkheid om indexen volgens een schema bij te werken. Daarnaast kunnen indexen ook online gebruikt worden. Vanaf nu moeten we specifieker zijn.
Ondanks de primitiviteit van zoekopdrachten, kan het programma worden gebruikt om naar bestanden te zoeken, zodat het gebruik ervan in netwerken kan worden gerechtvaardigd. Hoewel met een grote strekking, aangezien in een groot netwerk de prioriteit is om snel naar gegevens te zoeken met behulp van complexe zoekopdrachten vanwege de enorme hoeveelheid informatie - en er zijn duidelijk problemen met de snelheid van het zoeken en het programma. Ik moet zeggen dat het werk met het netwerk bij de Bloodhound is doordacht zoals het hoort. Speciaal hiervoor ontworpen aparte applicatie- Bloedhond-server. Het werkt op dezelfde manier als alleen de Bloodhound (ze hebben één zoekmachine), alleen voor documenten die worden gehost op een centrale server of op gedeelde bronnen op een bedrijfsnetwerk. Bloodhound Server maakt nieuwe indexen op gedeelde bronnen of gebruikt eerder gemaakte indexen. Elke gebruiker op het bedrijfsnetwerk kan verbinding maken met de Bloodhound-server en deze gebruiken om toegang te krijgen tot elk document (dat zich in de huidige index bevindt) met behulp van een internetbrowser. Mee eens, zo'n schema is buitengewoon handig: het blijkt dat de bestanden in eigen netwerk kan op dezelfde manier worden doorzocht als informatie op internet via bijvoorbeeld Google.
Als we alle voor- en nadelen van dit programma evalueren, suggereert de conclusie dat voor bedrijfsnetwerken de mogelijkheden hoogstwaarschijnlijk niet genoeg zullen zijn (ondanks de goede organisatie van netwerken), maar voor een thuiscomputer of zelfs voor een thuisnetwerk is het, in principe zou kunnen passen. Hoewel noch de snelheid van het werk, noch de zoekmogelijkheden optimisme opwekken ...
Officiële website in het Russisch:
Distributiegrootte: 6 MbGoogle Desktop Search + GDS Enterprise 
Natuurlijk konden we zo'n eminente ontwikkelaar niet negeren. Google-naam zegt al veel. Mensen die al jaren de krachtigste internetzoekmachine gebruiken, zullen waarschijnlijk zonder enige twijfel besluiten deze specifieke zoekmachine op hun computer te installeren. Het is alsof je denkt: Google op je thuiscomputer! Laten we echter, zonder te bezwijken voor provocaties met een alom gepromoot merk, proberen nuchter en vooral objectief de mogelijkheden van de "desktop" -zoekmachine van Google te overwegen.
Het eerste dat opvalt, is het ontbreken van een eigen shell voor het programma. Google Desktop Search is nog steeds in het browservenster, respectievelijk de volledige interface van de desktopversie ging naar de software van de oudere internetbroer. Is het goed of slecht - controversieel probleem: iemand houdt van minimalisme in het ontwerp van deze zoekmachine, en iemand wil een volwaardige applicatie zien gevuld met allerlei knoppen en ga zo maar door.
Wat springt direct na het ontwerp in het oog? En het feit dat dezelfde Google Desktop Search alles op de computer begint te indexeren, zonder dat daar vraag naar is! En het meest interessante is dat het onmogelijk is om indexeringspaden te kiezen met Google Desktop Search. Je zult een apart programma (TweakGDS) moeten downloaden, waarmee je iets kunt uitbreiden google instellingen Desktop, inclusief het specificeren van de plaatsen die nodig zijn voor indexering. Hoewel, hoewel u dit allemaal begrijpt, het de standaard harde schijf al indexeert, dus deze instelling is meer nodig bij het werken met grote data-arrays, wat erg belangrijk is bij gebruik in bedrijfsnetwerken ( Enterprise-edities). Het is echter geen feit dat na het downloaden van TweakGDS uw problemen zijn opgelost. Het heeft immers Microsoft .NET Framework en Microsoft Scripting Runtime nodig om te werken. Ja... de installatie, evenals de toegang tot de instellingen, had eenvoudiger kunnen worden gemaakt, hoewel ontwikkelaars waarschijnlijk kunnen begrijpen: waarom iets nieuws schrijven als er al een kant-en-klare zoekmachine is, het naar een lokale computer overzet en laat de gebruiker "genieten" , en een bekende naam zal van "dit" weer een meesterwerk maken. Oké, laten we hier een einde aan maken. lyrische uitweiding en ga verder met zoeken.
Wat betreft de analyse van zoekopdrachten en de uitgifte van resultaten, alles is hier absoluut identiek aan Google op internet: hetzelfde systeem voor het weergeven van resultaten, dezelfde standaardreeks logische bewerkingen voor zoekopdrachten. Over het algemeen is Google Desktop Search, net als het vorige programma, exclusief ontworpen voor het doorzoeken van bestanden - er is natuurlijk geen interne viewer voor deze bestanden. Het aantal bestandsindelingen dat wordt ondersteund door Google Desktop Search is voldoende, en het is ook fijn dat het de bezochte internetpagina's doorzoekt en gegevens uit de cache haalt. Zoek- en indexeringssnelheden zijn redelijk acceptabel. Toegegeven, voor thuisgebruik. Met maar liefst 20 gigabyte aan teksten lukte Google Desktop Search in 8 uur en 17 minuten. Een paar dagen besteden aan het verwerken van informatie uit het bedrijfsnetwerk van een grote onderneming glimlacht bij geen enkele systeembeheerder. Aan de positieve kant: de grootte van de gemaakte index bleek op het niveau (4,5 GB) te liggen met een andere zoekmachine die in deze review werd getest - SearchInform.
Een groot voordeel (of omissie - u bepaalt) van Google Desktop Search is dat het plug-ins ondersteunt die veel ten goede kunnen veranderen. Een ander ding is dat het aansluiten van plug-ins en het configureren ervan het installeren van een zoekmachine zo ingewikkeld maakt dat je je begint af te vragen of dit allemaal nodig is als je een normaal, volwaardig programma kunt installeren waarin alles al aanwezig is. Om elke functie te gebruiken, moet u immers installeren nieuwe plug-in. Zelfs om het programma volledig met archieven te laten werken, is een aparte lotion nodig. Het fascineert en verleidt het gratis van al deze aanvullende modules. Als u echter geen rekening houdt met de desktopversie van de zoekmachine, ligt het vakkundig opzetten van GDS Enterprise misschien niet binnen uw macht - het is niet voor niets dat Google-specialisten hun diensten aanbieden om hun eigen software voor uw netwerk voor slechts $ 10.000.
Als u desondanks de installatie- en installatieprocedure beheerst (of 10.000 dollar betaalt aan het snelle reactieteam van Google), zult u begrijpen dat de complexiteit van de installatie meer dan gecompenseerd wordt door zeer flexibele instellingen bij gebruik in bedrijfsnetwerken. Een belangrijk aspect van het werk van Google Desktop in een bedrijfsnetwerk is het gebruik groepsbeleid, waarmee het mogelijk is om voor elke gebruiker voorkeuren in te stellen.
Samenvattend moet gezegd worden dat het meest redelijke gebruik van dit programma een thuis- of werkcomputer is. Voor een gewone computer is het inderdaad voldoende om het programma te installeren - het doet de rest zelf (het zal u zelfs nergens naar vragen).
Google Desktop Search Enterprise is echter acceptabel in gevallen waarin er dringend behoefte is aan flexibele netwerkbeleidsinstellingen voor het gebruik van de zoekmachine, terwijl de mogelijkheid om zoekopdrachten te verwerken op de tweede plaats komt en de tijd (of geld) besteed aan het opzetten van het programma, komt op de eerste plaats.
Officiële site:
Distributiegrootte met TweakGDS: 1,2 MbCopernic Desktop Search 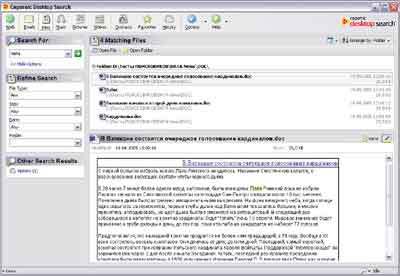
Klik op de foto om te vergroten
De programma-interface roept extreem positieve emoties op - alles gebeurt in overeenstemming met algemeen aanvaarde normen, niets meer, kortom mooi design. Het zal voor een beginner heel gemakkelijk zijn om de interface van Copernic Desktop Search te begrijpen. Hoewel het enigszins gênant is dat de ontwerpers de interface van het programma expliciet hebben gemaakt, rekening houdend met het feit dat het programma zal werken in het standaard Windows XP-thema. Als je hetzelfde klassieke thema gebruikt, ziet het programma er niet zo mooi uit. Maar dit is meer een kwestie van smaak.
Bij de eerste start biedt het programma aan om indexen te maken om te zoeken. Het leek enigszins ongebruikelijk dat na het selecteren van mappen voor indexering, het programma niet aanbiedt om op een knop te drukken, zoals "Start indexering", terwijl indexering niet automatisch start, pas toen werd opgemerkt dat Copernic probeert te indexeren wanneer de computer niet actief is . Je zult een beetje in de programma-opties moeten graven om alles goed in te stellen. Opgemerkt moet worden dat er vrij brede opties zijn voor het instellen van automatische indexcreatie: een ingebouwde planner, de mogelijkheid om te indexeren wanneer de computer inactief is, achtergrond, met lage prioriteit. Indexeren ging niet al te snel - 10 uur 51 minuten - dit is langzamer dan in andere zoekmachines (behalve de Bloodhound, maar Copernic is een orde van grootte sneller dan de ontwikkeling van iSleuthHound Technologies.
Nu over de structuur van de index. Over het algemeen is er niets bijzonders aan. Het is mogelijk om bestandstypen te selecteren, zowel in een algemene vorm als in een gedetailleerde vorm. Dat wil zeggen dat u in eerste instantie kunt kiezen wat u wilt indexeren: documenten, afbeeldingen, video's, muziek. Op het andere tabblad van het optievenster is het mogelijk om specifieke bestandstypen op extensie te selecteren. Bovendien kunt u de index zo configureren dat bijvoorbeeld afbeeldingen kleiner dan 16x16 niet worden geïndexeerd of geluidsbestanden die korter zijn dan 10 seconden niet worden geïndexeerd. Naast het indexeren van bestanden uit mappen, kan Copernic werken met e-mails en contacten van adresboek Microsoft Outlook en Microsoft Outlook Express, indexering van favorieten en geschiedenis vanuit Internet Explorer is mogelijk.
Wat betreft de zoekmogelijkheden, die zijn hier erg zwak. Tijdens de tests bleek zelfs dat het programma niet naar documenten zoekt txt-indelingen en html in het Russisch, zodat u ze alleen op koppen kunt vinden, en zeker niet op inhoud. Het enige dat het programma biedt om de zoekefficiëntie te verbeteren, is het gebruik van een standaardset van logische bewerkingen, en zelfs toen werd deze functie experimenteel ontdekt, omdat deze niet was gedocumenteerd. Trouwens, de hulp van het programma is ook niet in orde - het is alleen beschikbaar via internet, wat, ziet u, erg onhandig is, en er is niet al te veel hulpinformatie op het netwerk. Blijkbaar hebben de ontwikkelaars besloten dat de eenvoudige interface van het programma niet de aanwezigheid van normale hulp impliceert. Voortzetting van het gesprek over de zoekmogelijkheden, moet worden opgemerkt dat, ondanks de slechte analyse van zoekopdrachten, het programma een interessant zoeksysteem biedt - de gebruiker kan het type bestanden selecteren (afbeeldingen, video's, muziek, enz.), Een zoekquery en selecteer attributen die specifiek zijn voor het geselecteerde bestandstype. Voor geluidsbestanden kunnen dit bijvoorbeeld waarden zijn van mp3-tags (artiest, album, datum, enz.), voor afbeeldingen kunt u bijvoorbeeld hun grootte kiezen (op resolutie), in het algemeen heeft elk type zijn eigen instellingen. Na het zoeken naar zeker type bestanden zal het programma een zeer informatieve lijst weergeven in het resultatenvenster, en als uw verzoek bestanden van andere typen bevat, kunt u deze openen door op een specifieke link te klikken.
Afzonderlijk is het de moeite waard om het resultatenvenster te vermelden. De inhoud van deze bestanden wordt weergegeven onder de lijst met gevonden bestanden (een soortgelijk schema wordt vaak gebruikt in e-mailclients). Toegegeven, tekst kan alleen in zijn oorspronkelijke formaat worden bekeken en er is geen weergavemodus voor platte tekst, wat niet altijd handig is, omdat het openen van een document in dit geval meer tijd kost. Maar aangezien Copernic kan zoeken naar afbeeldingen en muziek, is er de mogelijkheid om deze multimediabestanden te bekijken.
De basisprincipes van dit programma zijn beschreven, laten we nu eens kijken wat Copernic Desktop Search ons kan bieden voor het werken met het netwerk ... In principe kun je heel lang kijken, maar het is onwaarschijnlijk dat je iets ziet. Met andere woorden, dit programma was niet bedoeld als een netwerkprogramma. Copernic Desktop Search is uitsluitend een thuiszoekmachine.
Het enige (meest logische) gebruik van dit programma is uiteraard een thuiscomputer. Hier zal het alle eenvoudige zoekopdrachten van gebruikers, bestaande uit een of twee woorden, goed aankunnen, de nodige informatie vinden en de scheiding van zoeken op bestandstype en ondersteuning voor multimediabestanden, samen met achtergrondindexering in de modus met lage prioriteit, in combinatie met een prettige interface, geeft het programma alleen de kracht om vertrouwen te winnen bij onervaren gebruikers.
Officiële site
Distributiegrootte: 2,6 MbISYS Desktop 
Klik op de foto om te vergroten
Heel krachtig programma. Qua uitrustingsniveau met allerlei functies zit het ergens in de buurt van de volgende SearchInform-zoekmachine in de lijst. Tegelijkertijd is de grootte van het installatiebestand meer dan 40Mb! Het is moeilijk te zeggen wat er in dergelijke formaten kan worden gestopt, omdat dezelfde SearchInform, met vergelijkbare functionaliteit, 15 MB in beslag neemt.
Het installatieproces is hier ook niet erg prettig, of liever niet eens het installatieproces. Zelfs voordat u het programma downloadt, wordt u gevraagd om u te registreren, anders niets. Vervolgens de interface. Het is heel mooi gemaakt, niets overbodigs springt in het oog, dit zijn echter de indrukken van een persoon die al enigszins aan hem gewend is. Het zal voor een beginner niet gemakkelijk zijn om erachter te komen waar en wat is, waar te klikken en waar uiteindelijk te zoeken. Het wordt ten zeerste aanbevolen om de help te lezen voordat u aan het werk gaat - bespaar veel zenuwen en tijd. Naast al het andere is het ook volledige afwezigheid Russische taalondersteuning in het programma. Niet goed. Bovendien zijn de ramen hier niet overladen met bedieningselementen, maar dit ging ten koste van multi-module en het gebruik van extra ramen. Zoekopdrachten worden bijvoorbeeld ingevoerd door het ene programma uit te voeren en indexen worden beheerd met een ander programma. Zoekopdrachten worden hier ook in afzonderlijke, verschijnende vakken ingevoerd. Het is moeilijk te zeggen wat beter is - overbelaste interface of alomtegenwoordige multi-window, het is eerder een kwestie van smaak.
Wat het maken van indexen betreft, biedt het programma opties om het proces van het instellen van opties voor een nieuwe index te vereenvoudigen. Deze functies omvatten verschillende kant-en-klare sjablonen om indexen te maken op Mijn documenten, Mail, Mail en documenten, specifieke map, map met geselecteerde bestandstypen, enz. Deze sjablonen maken het gemakkelijk om in de eerste fase indexen te maken. Het hulpprogramma voor het werken met indexen heeft geen erg goede interface, wat enige complexiteit afschrikt (dit is een zeer subjectieve beoordeling, om eerlijk te zijn), maar als je ernaar kijkt, biedt het veel handige opties en in het algemeen veroorzaakt het gebruik ervan niet veel moeilijkheden. ISYS Desktop kan gegevens uit verschillende gegevensbronnen indexeren en biedt ook veel flexibele instellingen voor deze indexering. Extra indexeringsfuncties omvatten ondersteuning voor SQL, FTP, TRIM Context, WORLDOX 2002, scripts. Als u bij het maken van een index de optie "Map met een keuze aan bestandstypen" hebt geselecteerd, hebt u de mogelijkheid om de typen bestanden te selecteren die handmatig (per extensie) moeten worden geïndexeerd. Het moet gezegd dat er gewoon enorm veel ondersteunde bestandstypes zijn, maar het zal niet mogelijk zijn om een eigen type (extensie) toe te voegen aan de bestaande lijst. U kunt ook de aanwezigheid van een indexeringsplanner opmerken. ISYS Desktop had 6 uur en 13 minuten nodig om een index te maken en 20 gigabyte aan informatie te verwerken, wat uiteindelijk de goede tijd en de grootte van het gemaakte bestand liet zien - 7,9 GB.
De zoekmogelijkheden van dit programma zijn niet slecht. Wat in ISYS wordt gebruikt, is veel krachtiger dan de gebruikelijke ondersteuning voor logische bewerkingen. Van de geavanceerde zoekfuncties biedt het programma het gebruik van synoniemen, sorteerfilter (op pad, naam en datum van aanmaak van het bestand). Kit logische operatoren iets breder dan de standaardset. Naast logische bewerkingen kunt u met het programma met veel andere operators werken, die in principe sommige soorten zoekopdrachten kunnen vervangen, bijvoorbeeld zoeken met ontleden het is heel goed mogelijk om het gebruik van speciale operators te vervangen. Ik was zeer verrast dat het programma geen zoekfunctie heeft met behulp van morfologie. Dit is een ernstige omissie, aangezien de zoekefficiëntie aanzienlijk wordt verbeterd bij gebruik van morfologische analyse. Daarnaast is er geen lijst met significante woorden, maar wel een uitgebreide lijst met niet-significante woorden. Dergelijke functies worden ook gedeclareerd bij het zoeken als " zoeken bij benadering en "heuristische analyse".
ISYS biedt een keuze uit verschillende soorten zoekopdrachten, namelijk visuele. Dit is gedaan met behulp van verschillende soorten vensters voor het invoeren van zoekopdrachten, maar in feite kunt u in geen enkel venster andere technologieën gebruiken dan de hierboven genoemde.
De zoekresultaten zijn zeer informatief, weergegeven als een lijst met documenten gesorteerd op relevantie. Hieronder ziet u een voorbeeld van het geselecteerde document. In tegenstelling tot Copernic Desktop Search is het voorbeeld hier alleen beschikbaar in de vorm van platte tekst, het was niet mogelijk om de weergave van documenten in het oorspronkelijke formaat te bereiken, of het nu Word, Html of PDF is, hoewel dit in principe niet al te kritisch is. Met het programma kunt u de gevonden documenten in groepen verdelen volgens bepaalde criteria (standaard zijn ze onderverdeeld op relevantie). U kunt ook reeds gevonden documenten bekijken door afzonderlijke mappen te selecteren (dit is handig wanneer het resultaat een zeer groot aantal documenten oplevert).
Het gebruik van het programma in een bedrijfsnetwerk is ook redelijk gerechtvaardigd, omdat het goede mogelijkheden biedt voor het organiseren van netwerkzoekopdrachten. Het zoeksysteem is gebaseerd op het maken van een openbare index, die geïndexeerde gegevens van openbare netwerkbronnen bevat.
In feite is het programma van ISYS de aandacht waard, in ieder geval om er kennis mee te maken. Dit programma is een volwassen project met een enorm aantal functies (niet altijd en niet iedereen heeft ze natuurlijk nodig, maar toch). De kans dat het programma enkele verbeteringen zal hebben op het gebied van het verwerken van zoekopdrachten is niet bekend, maar dit moment het kan worden aanbevolen voor bijna universeel gebruik. En aangezien het nog steeds te zwaar is voor thuissystemen, zijn de belangrijkste plaatsen voor installatie bedrijfsnetwerken.
Officiële site:
Distributiegrootte: 40 MbSearchInform 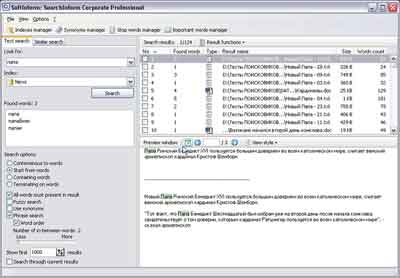
Klik op de foto om te vergroten
Het is waarschijnlijk niet de moeite waard om meteen te beginnen met een beschrijving van de SearchInform-interface. We moeten eerst het installatieproces beschrijven, of liever een van de details ervan: je kunt het programma niet installeren zonder een internetverbinding. Het is een feit dat het programma vóór de eerste lancering gebruikersregistratie (gratis) vereist en alle ingevoerde gegevens naar de server stuurt. Blijkbaar moesten de ontwikkelaars dergelijke maatregelen nemen in de strijd tegen piraterij, maar dit had geen positieve invloed op het installatiegemak.
De programma-interface is gemaakt in overeenstemming met alle algemeen aanvaarde regels, maar is op het eerste gezicht wat omslachtig. Als u het programma voor de eerste keer gebruikt, lijkt het te ingewikkeld, soms is het niet gemakkelijk om te onthouden in welk menu of tabblad de gewenste optie zich bevindt, echter met meer langdurig gebruik, lijkt de interface niet meer zo verschrikkelijk ingewikkeld. Het belangrijkste is om eerst de help te lezen.
Nadat u de interface een beetje hebt behandeld, kunt u beginnen met het maken van een index. Het proces zelf is heel eenvoudig en de indexeringssnelheid, zelfs met het oog, is veel hoger dan bij alle andere zoekmachines uit de recensie. Duidelijke testcijfers laten zien dat SearchInform twee keer zo snel is als dtSearch en iSYS qua indexeringssnelheid! Het programma indexeerde de verstrekte gegevens in een recordtijd van 20 gigabyte - 3 uur en 17 minuten. En de grootte van de gemaakte index bleek de kleinste 4,4 GB - 100 megabyte minder te zijn dan die van Google Desktop Search.
Het programma ondersteunt naast reguliere bestanden en mappen ook het indexeren van e-mails, het koppelen en indexeren van databases (!) en andere externe bronnen (DMS, CRM), direct bij het indexeren kun je een woordenboek specificeren voor morfologisch zoeken, en alle attributen kunnen geïndexeerde bestanden zijn. Nadat u een index hebt gemaakt, kunt u bij het uitvoeren van de eerste testzoekopdracht voor documenten tot enige verwarring komen: "er zijn twee soorten zoekopdrachten, maar welke heb ik nodig?". Zoals eerder vermeld, is het belangrijkste om de help te lezen, dan wordt alles duidelijk. Het programma is in staat om twee soorten zoekopdrachten uit te voeren: zoeken op woordgroepen en zoeken naar documenten die qua inhoud vergelijkbaar zijn met de zoektekst.
De beschrijving van alle hoofdfuncties voor het analyseren van een zoekopdracht werd hierboven gegeven, dus nu zullen we alleen de zoekmogelijkheden vermelden die door dit programma worden geboden. Laten we beginnen met zoeken op woordgroepen: natuurlijk morfologisch zoeken, zoeken naar aanhalingstekens, logische bewerkingen, zoeken op woordparsing (zoeken op het begin van het woord, op het einde, op het middelste deel of een volledige overeenkomst), zoeken met gemengde aanhalingstekens (wanneer alle woorden uit de zoekopdracht moeten in het document voorkomen, maar niet noodzakelijk in de ingevoerde volgorde), zoeken naar foutencorrectie, gebruik van synoniemen, "bijna citaat zoeken" (zoek de ingevoerde zin als een citaat, maar er kunnen andere woorden tussen de ingevoerde woorden), enz. Sommige van de vermelde opties hebben hun eigen specifieke instellingen. Daarnaast is het mogelijk om een woordenboek met onbeduidende woorden te gebruiken, en het programma heeft al een kant-en-klare lijst van deze woorden, je kunt ook een woordenboek met prioriteitswoorden gebruiken om te zoeken (je zult deze natuurlijk wel moeten invullen jezelf).
Hier hebben we in principe kort alle hoofdkenmerken van het zoeken op woordgroepen doorgenomen.
Laten we verder gaan met de overweging van de functies van dit programma - het zoeken naar vergelijkbare documenten. De ontwikkelaars beweren dat dit in geen geval een eenvoudige tekstzoekopdracht is, dit is precies een "zoeken naar soortgelijke" - zo beschrijven ze het overal, maar oké, je kunt het noemen wat je wilt - het belangrijkste is. Een korte zoektocht op internet kan al snel uitwijzen dat de zogenaamde "similar search" een nieuwe ontwikkeling is op het gebied van tekstanalyse. Met dit systeem kunt u teksten vinden die qua semantische inhoud vergelijkbaar zijn. Het leukste was dat na het uitvoeren van testzoekopdrachten, bleek dat de theorie redelijk overeenkomt met de praktijk! Het programma zoekt echt naar documenten die qua inhoud vergelijkbaar zijn en geeft ze weer in een lijst, gesorteerd op overeenkomstpercentage.
Overweeg vervolgens wat SearchInform te bieden heeft (in het bijzonder zijn zakelijke versie SearchInform Corporate) voor het werken in een bedrijfsnetwerk. Er zijn twee soorten toepassingen: serverkant en gebruikerskant. Het servergedeelte verwerkt zelfstandig de opgegeven indexen en gebruikers kunnen ze gebruiken om te zoeken, afhankelijk van de toegangsrechten die eraan zijn toegewezen. Gebruikers kunnen automatisch worden geconfigureerd met behulp van logins. Windows-items(in professionele termen gebruikt SearchInform Windows NTFS-authenticatie) en handmatig (gebruikers moeten apart worden toegevoegd). Elke gebruiker kan de toegang tot bepaalde indexen worden toegestaan of geweigerd, u kunt gebruikers ook combineren in groepen. Over het algemeen lopen de netwerkinstellingen van SearchInform voor op Google wat betreft flexibiliteit en Snoop Server wat betreft gemak en eenvoud.
Officiële site:
Distributiegrootte: 14,7 MbIndexeringssnelheid vergelijking
| Zoeksysteem | Indexeertijd | Indexgrootte |
| Bloodhound Pro Deluxe 4.5 | 38 uur 46 minuten | 19 GB |
| Isys Desktop 7.0 | 6 uur 13 minuten | 7,9 GB |
| DtSearch 7.0 | 6 uur 3 minuten | 8,6 GB |
| Google Desktop Search Enterprise | 8 uur 17 minuten | 4,5 GB |
| Copernic Desktop Zoeken * | 10 uur 51 minuten | 7 GB |
| ZoekenInformeren 1.5.02 | 3 uur 17 minuten | 4,4 GB |
* De meeste .html- en .txt-documenten die Russische tekst bevatten, konden, hoewel ze waren geïndexeerd, alleen op naam worden gevonden.
Alle programma's verdienen aandacht.
Op basis van de tests en het zorgvuldige onderzoek van elk programma dat in de review wordt gepresenteerd, kunnen bepaalde conclusies worden getrokken. Google Desktop Search Copernic Desktop Search is dus heel geschikt voor een onervaren gebruiker als zoeksysteem voor thuisinformatie. Ze doen goed werk met eenvoudige verzoeken, belasten de gebruiker niet veel met instellingen en zijn bovendien volledig gratis. De poging van Google om de markt van zakelijke zoekmachines te betreden is nog niet sterk gerechtvaardigd: voor volwaardig werk moet het programma worden opgehangen extra modules En het is verre van eenvoudig in te stellen. Daarom laten we de namen van Desktop Search, die Copernic, dat Google een niche van 'desktop'-zoekmachines achter zich.
Echte, krachtigere oplossingen - dtSearch, iSYS en SearchInform komen ook niet uit de lucht vallen en bieden gebruikers hun "desktop" -versies. Maar tegen een redelijke prijs, in tegenstelling tot gratis software van Google en Copernic. Natuurlijk moet je betalen voor kracht, snelheid en functionaliteit. Maar de ontwikkelaars van dtSearch, iSYS en SearchInform richten zich natuurlijk vooral op het bedrijfsleven. Netwerken, functionaliteit, indexering en zoeksnelheid - dat is wat deze producten onderscheidt van hun "concurrenten". Volgens de resultaten van de test werd de favoriet bepaald - SearchInform. Het programma biedt de mogelijkheid om soortgelijke documenten te zoeken, heeft top snelheid indexeren en zoeken, heeft een goede reeks functies.
Om de benodigde bestanden op de computer te vinden, hebben we al overwogen: standaardfuncties, die zich aanvankelijk in het Windows-systeem bevinden. Meer over het standaard zoeken in Windows lees je in de artikelen: en.
Het voordeel van standaard zoeken is dat u niets extra hoeft te installeren op uw computer!
Maar er is ook een serieus nadeel - niet alle standaard zoekacties werken of werken niet zoals we zouden willen!
Daarom zullen we in dit artikel een aparte excellent beschouwen gratis programma Alles, waarmee u heel snel, u kunt zelfs direct (on-the-fly) zeggen, de bestanden die u nodig hebt op uw computer kunt vinden!
Met Alles kunt u naar bestanden op uw computer zoeken, niet alleen op de volledige naam van de bestanden, maar zelfs op een deel van het woord! Dit is een geweldige functie voor situaties waarin we de naam van het hele bestand niet meer weten.
We voeren gewoon een woord of een deel van een woord in het zoekveld in en krijgen meteen het resultaat! Tegelijkertijd vertraagt alles, verrassend genoeg, de computer helemaal niet, zoals bij andere programma's wel het geval is.
Everything is een snel, lichtgewicht en handig programma om bestanden en mappen op uw computer te vinden.
Laten we beginnen met een stapsgewijze analyse van het installeren en gebruiken van dit programma.
Hoe alles in het Russisch te downloaden
Laten we zeggen dat ik niet meer weet waar dit boek op mijn computer is opgeslagen.
Om het te vinden met behulp van het programma Alles, ik hoef niet al die lange boektitels te typen. Ik kan maar een woord typen boek en krijg dit resultaat:

In dit geval liet de zoekopdracht me zien dat ik 33 elementen heb waarin het woord voorkomt boek. En Zoekresultaten geeft alle items weer op bestandstype, waarbij het woord wordt gemarkeerd waarnaar ik op zoek was.
En ik kan het bestand dat ik nodig heb al vinden in de weergegeven lijst en er naartoe gaan door er gewoon snel op te dubbelklikken. Als het een bestand is, wordt het onmiddellijk geopend. Als het een map met bestanden is, wordt de map geopend.
Of ik kan de zoekopdracht verfijnen zodat de lijst met bestanden kleiner is. Ik zal bijvoorbeeld het woord schrijven meest. Ik krijg meteen de map die ik nodig heb:

Zoals u kunt zien, is het heel eenvoudig om bestanden en mappen op uw computer te vinden met Alles programma. Ik ben blij dat het gratis is, in het Russisch en zeer snel zoekresultaten geeft!
Extra Alles-instellingen
Programma Alles voor de meeste gebruikers al optimaal geconfigureerd. Echter, daar extra functies die naar behoefte kan worden gebruikt.
Dus bijvoorbeeld via het menu Zoekopdracht u kunt de criteria voor het weergeven van uitvoer specificeren: voor bestanden van bepaalde formaten, voor mappen of allemaal. Dergelijke beperkingen kunnen van pas komen als de naam voorkomt in verschillende bestanden en de lijst met dergelijke bestanden is groot. En dankzij de beperking op bepaalde categorieën, kunt u uw zoekopdracht verfijnen:

Het zou ook handig zijn om alleen naar de functies te kijken die in het menu te vinden zijn Dienst-> Instellingen. Ik herhaal dat standaard alles al is geconfigureerd voor de verzoeken van de meeste gebruikers, maar misschien sommigen aanvullende instellingen U wilt het in- of uitschakelen.
Draagbare versie van het Alles-zoekprogramma
Aan het begin van het artikel hadden we het al over zo'n draagbare versie van dit programma. Gebruik zowel de draagbare versie als de stationaire versie. Het is alleen de moeite waard om te vermelden dat de draagbare versie in een archief is verpakt.
Daarom heeft u na het downloaden van het archief van de draagbare versie een archiver nodig zodat u het archief kunt openen. Als het gedownloade archief niet kan worden geopend, is de archiver niet op de computer geïnstalleerd. Download en installeer in dit geval, de installatie en het gebruik hiervan hebben we al in een apart artikel behandeld.
Als u van plan bent de draagbare versie te gebruiken op een computer waarvan u niet weet welke bitdiepte, gebruik dan een archief dat is ontworpen voor 32 bitsystemen. Of beter, download beide versies - sommige zullen zeker starten, anders wordt er gewoon een bericht weergegeven:

Dus: Als u zelfs van tijd tot tijd naar bestanden of mappen op uw computer moet zoeken, weet ik zeker dat u dit gratis programma zult waarderen!
Download, gebruik, deel uw indrukken in de opmerkingen!
Hallo, beste lezers van de blogsite. , dan hadden de weinige gebruikers genoeg van hun eigen bladwijzers. Zoals je je herinnert, gebeurde het echter exponentieel en al snel werd het moeilijker om in al zijn diversiteit te navigeren.
Toen verschenen er mappen (Yahu, Dmoz en anderen), waarin hun auteurs verschillende sites toevoegden en in categorieën sorteerden. Dit maakte het leven van de toen nog niet zo talrijke gebruikers van het wereldwijde netwerk meteen gemakkelijker. Veel van deze mappen zijn nog steeds in leven.
Maar na een tijdje werd de omvang van hun databases zo groot dat de ontwikkelaars er eerst over dachten om er een zoekopdracht in te maken en vervolgens over het creëren van een geautomatiseerd indexeringssysteem voor alle internetinhoud om het voor iedereen beschikbaar te maken.
De belangrijkste zoekmachines van het Russisch sprekende segment van internet
Zoals je je kunt voorstellen, werd dit idee met doorslaand succes gerealiseerd, maar alles bleek echter alleen goed voor een handvol geselecteerde bedrijven die erin slaagden niet op internet te verdwijnen. Bijna alle zoekmachines die op de eerste golf verschenen zijn nu ofwel verdwenen, of vegeteren, of werden gekocht door meer succesvolle concurrenten.
Het zoeksysteem is een zeer complex en, belangrijker nog, zeer arbeidsintensief mechanisme (dat wil zeggen niet alleen materiële, maar ook menselijke). Achter de ogenschijnlijk eenvoudige, of zijn ascetische tegenhanger van Google, zijn er duizenden werknemers, honderdduizenden servers en vele miljarden investeringen die nodig zijn om deze kolos te laten blijven werken en concurrerend te blijven.
Nu deze markt betreden en alles opnieuw beginnen is meer een utopie dan echte zaken projecteren. Een van de rijkste bedrijven ter wereld, Microsoft, probeert bijvoorbeeld al tientallen jaren voet aan de grond te krijgen op de zoekmarkt, en pas nu begint hun Bing-zoekmachine langzaam hun verwachtingen te rechtvaardigen. En daarvoor was er een hele reeks mislukkingen en mislukkingen.
Wat kunnen we zeggen over het betreden van deze markt zonder speciale financiële invloeden. Onze binnenlandse zoekmachine Nigma heeft bijvoorbeeld veel nuttige en innovatieve dingen in zijn arsenaal, maar hun verkeer is duizenden keren inferieur aan de leiders van de Russische markt. Kijk bijvoorbeeld eens naar het dagelijkse publiek van Yandex:

In dit opzicht kunnen we aannemen dat de lijst met de belangrijkste (beste en meest succesvolle) zoekmachines van de Runet en het hele internet al is gevormd, en de hele intrige ligt alleen in wie uiteindelijk wie zal verslinden, nou ja, of hoe hun percentage zal worden verdeeld als ze allemaal overleven en blijven drijven.
Russische zoekmachine markt is zeer goed zichtbaar, en hier zijn waarschijnlijk twee of drie hoofdspelers en een paar secundaire te onderscheiden. Over het algemeen heeft zich in Runet een nogal unieke situatie ontwikkeld, die, zoals ik het begrijp, slechts in twee andere landen in de wereld is herhaald.
Ik heb het over het feit dat de Google-zoekmachine, die in 2004 naar Rusland is gekomen, nog niet het voortouw heeft kunnen nemen. In feite probeerden ze rond deze periode Yandex te kopen, maar daar werkte iets niet, en nu zijn "ons Rusland", samen met de Tsjechische Republiek en China, de plaatsen waar de almachtige Google, zo niet verslagen, dan, stuitte in ieder geval op ernstige weerstand.
Zie in feite de huidige stand van zaken onder: beste zoekmachines runet iedereen kan. Het is voldoende om deze URL te plakken in adresbalk je browser:
http://www.liveinternet.ru/stat/ru/searches.html?period=month;total=yes
Het feit is dat de meeste van hen .
Na het invoeren van de opgegeven URL, ziet u een afbeelding die niet erg aantrekkelijk en toonbaar is, maar die de essentie van de zaak goed weergeeft. Besteed aandacht aan de top vijf zoekmachines waarvan sites in het Russisch verkeer ontvangen:

Ja, natuurlijk worden niet alle bronnen met Russischtalige inhoud in deze zone gehost. Er zijn ook SU en de Russische Federatie, en gemeenschappelijke ruimtes zoals COM of NET staan vol met internetprojecten gericht op Runet, maar toch is de steekproef behoorlijk representatief.
Deze afhankelijkheid kan op een kleurrijkere manier worden getekend, zoals bijvoorbeeld iemand online deed voor zijn presentatie:

Het verandert niets aan de essentie. Er zijn een paar leiders en een paar heel, heel ver achter op zoekmachines. Over velen heb ik trouwens al geschreven. Soms is het best vermakelijk om in de geschiedenis van succes te duiken of, omgekeerd, in de redenen voor de mislukkingen van ooit veelbelovende zoekmachines.
Dus, in volgorde van belangrijkheid voor Rusland en de Runet als geheel, zal ik ze opsommen en korte kenmerken geven:
Google zoeken is al een begrip geworden voor veel bewoners van de planeet - daarover kun je lezen op de link. Ik vond de optie "resultaten vertalen" in deze zoekmachine leuk, toen je antwoorden van over de hele wereld ontving, maar in je eigen taal, maar nu is het helaas niet beschikbaar (tenminste op google.ru).

Ook ben ik onlangs verbaasd over de kwaliteit van hun uitgifte (Search Engine Result Page). Persoonlijk gebruik ik altijd eerst de zoekmachine van de Runet mirror (ik ben er wel aan gewend) en pas als ik daar geen begrijpelijk antwoord vind, wend ik me tot Google.
Meestal maakte hun uitgifte me blij, maar de laatste tijd verbaast het me alleen maar - soms komt zulke onzin naar buiten. Het is mogelijk dat hun strijd om de inkomsten uit contextuele advertenties en het constant schudden van de uitgifte te verhogen om het in diskrediet te brengen SEO-promotie kan averechts werken. In ieder geval heeft deze zoekmachine een concurrent in RuNet, en zelfs welke.
Ik denk dat bijna niemand specifiek naar Go.mail.ru zal gaan om in Runet te zoeken. Daarom kan het verkeer op entertainmentprojecten van deze zoekmachine aanzienlijk meer dan tien procent bedragen. Eigenaren van dergelijke projecten moeten aandacht besteden aan dit systeem.
Afgezien van de prominente leiders op de markt van zoekmachines in het Russisch sprekende segment van internet, zijn er echter verschillende andere spelers waarvan het aandeel vrij laag is, maar niettemin alleen al het feit van hun bestaan doet me een paar woorden over hen zeggen .
Runet-zoekmachines uit het tweede echelon

Internetbrede zoekmachines
Door over het algemeen op de schaal van het hele internet is er maar één serieuze speler - Google. Dit is de onbetwiste leider, maar hij heeft nog wel wat concurrentie.
Ten eerste is het nog steeds hetzelfde bing, dat bijvoorbeeld zeer goede posities heeft op de Amerikaanse markt, vooral gezien het feit dat zijn engine ook wordt gebruikt op alle Yahoo-diensten (bijna een derde van de gehele Amerikaanse zoekmarkt).

Nou, en ten tweede, vanwege het enorme aandeel gebruikers uit China in totaal aantal Internetgebruikers, hun belangrijkste zoekmachine gerechtigd Baidu ingeklemd in de verdeling van plaatsen op de wereld Olympus. Hij werd geboren in 2000 en nu is zijn aandeel ongeveer 80% van het totale nationale publiek in China.
Het is moeilijk om iets begrijpelijks over Baidu te zeggen, maar op internet zijn er oordelen dat de plaatsen in zijn Top niet alleen worden ingenomen door de meest relevante sites, maar ook door degenen die ervoor hebben betaald (direct naar de zoekmachine, en niet naar het SEO-kantoor). Dit geldt natuurlijk in de eerste plaats voor de commerciële uitgifte.

Over het algemeen wordt, als we naar de statistieken kijken, duidelijk waarom Google daar gemakkelijk heen gaat om zijn uitgifte te verslechteren in ruil voor toenemende winsten uit contextuele advertenties. Sterker nog, ze zijn niet bang voor de uitstroom van gebruikers, omdat ze in de meeste gevallen nergens heen en nergens heen kunnen. Deze situatie is enigszins triest, maar laten we eens kijken wat er daarna gebeurt.
Terloops, om het leven van de optimalisatieprogramma's nog moeilijker te maken, of misschien om de gemoedsrust van de gebruikers van deze zoekmachine te behouden, heeft Google onlangs codering gebruikt bij het verzenden van verzoeken van de browsers van gebruikers naar zoekreeks. Binnenkort is in de statistieken van bezoekerstellers niet meer te zien waarvoor gebruikers van Google bij jou zijn gekomen.
Naast de zoekmachines die in deze publicatie worden genoemd, zijn er natuurlijk meer dan duizend andere - regionaal, gespecialiseerd, exotisch, enz. Het zal niet mogelijk zijn om ze allemaal op te sommen en te beschrijven in het kader van één artikel, en waarschijnlijk is het ook niet nodig. Laten we een paar woorden zeggen over hoe gemakkelijk het is om een zoekmachine te maken en hoe niet eenvoudig en niet goedkoop om het up-to-date te houden.
De overgrote meerderheid van de systemen werkt volgens vergelijkbare principes (lees daarover en over) en streeft hetzelfde doel na: gebruikers een antwoord geven op hun vraag. Bovendien moet dit antwoord relevant zijn (overeenkomend met de vraag), uitputtend en, niet onbelangrijk, relevant (van de eerste versheid).
Het oplossen van dit probleem is niet zo eenvoudig, vooral gezien het feit dat de zoekmachine de inhoud van miljarden internetpagina's on-the-fly moet analyseren, onnodige pagina's moet verwijderen en een lijst (output) moet vormen van de resterende, waar de meest geschikte antwoorden op de vraag van de gebruiker zullen eerst gaan.
Deze uiterst complexe taak wordt opgelost door vooraf informatie van deze pagina's te verzamelen met behulp van verschillende indexerende robots. Ze verzamelen links van reeds bezochte pagina's en laden informatie daaruit in de database van de zoekmachine. Er zijn tekstindexerende bots (normale en snelle bots die op nieuws en regelmatig bijgewerkte bronnen leven, zodat de meest recente gegevens altijd in de resultaten worden weergegeven).
Daarnaast zijn er robots die afbeeldingen indexeren (voor hun latere uitvoer naar), favicons, site mirrors (voor hun latere vergelijking en mogelijke verlijming), bots die de prestaties van internetpagina's controleren die gebruikers of via tools voor webmasters (hier kunt u lezen over, en).
Het indexeringsproces zelf en het daaropvolgende proces van het bijwerken van indexdatabases zijn behoorlijk tijdrovend. Hoewel Google dit veel sneller doet dan zijn concurrenten, in ieder geval Yandex, wat een week of twee nodig heeft om dit te doen (lees meer).
Gewoonlijk wordt de tekstinhoud van een webpagina door de zoekmachine opgedeeld in afzonderlijke woorden, wat leidt tot: basiskennis zodat het later mogelijk zou zijn om correcte antwoorden te geven op vragen in verschillende morfologische vormen. Alle extra bodykit in de vorm Html-tags, spaties, enz. dingen worden verwijderd en de overige woorden worden alfabetisch gesorteerd en daarnaast wordt hun positie in dit document aangegeven.
Deze shnyaga wordt een omgekeerde index genoemd en stelt u in staat niet langer op webpagina's te zoeken, maar op gestructureerde gegevens die zich op de servers van de zoekmachine bevinden.
Het aantal van dergelijke servers bij Yandex (die voornamelijk alleen zoekt op Russischtalige sites en een beetje op Oekraïens en Turks) loopt in de tien- of zelfs honderdduizenden, en Google (die in honderden talen zoekt) loopt in de miljoenen.
Veel servers hebben kopieën die zowel dienen om de veiligheid van documenten te vergroten als om de snelheid van het verwerken van een verzoek te verhogen (vanwege load balancing). Schat de kosten van het in stand houden van deze hele economie.
Het verzoek van de gebruiker wordt door de load balancer doorgestuurd naar het serversegment dat momenteel het minst wordt belast. Vervolgens wordt de analyse van de regio uitgevoerd, van waaruit de gebruiker van de zoekmachine zijn verzoek heeft verzonden, en wordt de morfologische analyse gedaan. Als onlangs een soortgelijk verzoek in de zoekregel is ingevoerd, worden de gegevens uit de cache naar de gebruiker geschoven om de server niet opnieuw te laden.
Als het verzoek nog niet in de cache is opgeslagen, wordt het doorgegeven aan het gebied waar de indexbasis van de zoekmachine zich bevindt. Het antwoord zal een lijst zijn van alle webpagina's die op zijn minst enige relatie hebben met het verzoek. Er wordt niet alleen rekening gehouden met directe voorvallen, maar ook met andere morfologische vormen, enz. dingen.
Hen moet worden gesorteerd en in dit stadium komt het algoritme in het spel ( kunstmatige intelligentie). In feite wordt het verzoek van de gebruiker vermenigvuldigd vanwege alle mogelijke opties voor de interpretatie en antwoorden op vele verzoeken worden gelijktijdig doorzocht (door het gebruik van zoektaaloperatoren, waarvan sommige beschikbaar zijn voor gewone gebruikers).
In de regel is er in het nummer één pagina van elke site (soms meer). zijn nu zeer complex en houden rekening met veel factoren. Bovendien, voor hun aanpassing, en worden gebruikt, die de referentiesites handmatig evalueren, waardoor u de werking van het algoritme als geheel kunt aanpassen.
Over het algemeen is het duidelijk dat de zaak donker is. Je kunt hier lang over praten, maar toch is het duidelijk dat gebruikerstevredenheid met een zoekmachine wordt bereikt, oh, hoe niet gemakkelijk. En er zullen altijd mensen zijn die iets niet leuk vinden, zoals bijvoorbeeld jij en ik, beste lezers.
Veel succes! Tot snel op de blogpagina's site
Je kunt meer video's bekijken door naar . te gaan");">

Misschien ben je geïnteresseerd
Yandex People - zoeken naar mensen op sociale netwerken Apometer - gratis dienst het volgen van wijzigingen in de uitgifte en updates van zoekmachines DuckDuckGo is een zoekmachine die u niet volgt.  Hoe de internetsnelheid te controleren - online verbindingstest op een computer en telefoon, SpeedTest, Yandex en andere meters
Hoe de internetsnelheid te controleren - online verbindingstest op een computer en telefoon, SpeedTest, Yandex en andere meters  Yandex- en Google-foto's, evenals zoeken op afbeeldingsbestand in Tineye en Google
Yandex- en Google-foto's, evenals zoeken op afbeeldingsbestand in Tineye en Google
Elke dag neemt de hoeveelheid informatie uit het netwerk, en dus op de computers van gebruikers, toe. Op de harde schijven Voor een gewone gebruiker kan het aantal bestanden oplopen tot enkele honderden, en het vinden van de juiste in de totale massa is helemaal niet eenvoudig. De standaard Windows-zoekmachine werkt niet altijd snel en heeft een zeer slechte functionaliteit, dus het is logisch om programma's van derden te gebruiken.
In deze review zullen we verschillende programma's bekijken die u zullen helpen de benodigde gegevens op uw computer te vinden.
Dit programma is misschien wel het meest krachtig gereedschap om pc-stations te zoeken. Het heeft veel fijne instellingen, filters en functies. De distributie omvat ook: extra hulpprogramma's om te communiceren met het bestandssysteem.

Een van de onderscheidende kenmerken Search My Files is de mogelijkheid om bestanden volledig te verwijderen door ze te overschrijven met nullen of willekeurige gegevens.
ZoekenMijnBestanden
Door de naam van de medeklinker wordt Search My Files vaak verward met de vorige software. Dit programma onderscheidt zich doordat het gemakkelijker te gebruiken is, maar tegelijkertijd mist het een aantal functies, zoals zoeken op netwerkschijven.

Alles
Een eenvoudig zoekprogramma met zijn eigen mogelijkheden. Alles kan naar gegevens zoeken, niet alleen op de lokale computer, maar ook op ETP en FTP-servers. Het onderscheidt zich van andere vertegenwoordigers van dergelijke software doordat u wijzigingen in het bestandssysteem van de computer kunt volgen.

Effectief zoeken naar bestanden
Nog een zeer eenvoudig te installeren en te gebruiken software. Met een zeer klein formaat heeft het voldoende functies, kan het resultaten exporteren naar tekst- en spreadsheetbestanden en kan het op een USB-flashstation worden geïnstalleerd.

UltraSearch
UltraSearch kan niet alleen bestanden en mappen vinden, maar ook zoeken naar informatie in de inhoud van documenten op trefwoord of woord. Het belangrijkste onderscheidende kenmerk van het programma is de automatische initialisatie van aangesloten media.

REM
REM heeft een vriendelijkere interface dan eerdere leden. Het principe van het programma is om zones te creëren waarin bestanden automatisch worden geïndexeerd, wat het zoekproces aanzienlijk kan versnellen. Zones kunnen niet alleen op de lokale computer worden gemaakt, maar ook op stations op het netwerk.

Google Desktop Zoeken
Google Desktop Search, ontwikkeld door een wereldberoemd bedrijf, is een kleine lokale zoekmachine. Hiermee kunt u zowel op uw thuiscomputer als op internet naar informatie zoeken. Naast de hoofdfunctie voorziet het programma in het gebruik van informatieblokken - gadgets voor de desktop.

Alle programma's vermeld in deze lijst, zijn geweldig voor het vervangen van de native Windows-zoekopdracht. Kies zelf: installeer eenvoudiger software, maar met een kleinere set aan functies, of een hele zoekmachine met de mogelijkheid om bestanden te verwerken. Als u met mappen en schijven op een lokaal netwerk werkt, dan is REM en Everything geschikt voor u, en als u van plan bent het programma "met u mee te nemen", let dan op Effectief zoeken naar bestanden of Zoeken in mijn bestanden.
Runet is een plek waar je bijna alles kunt vinden. Maar alleen als je de juiste zoekmachine gebruikt. Er zijn tegenwoordig al ongeveer een dozijn van deze laatste op het Russische deel van internet, maar sommige worden door bijna alle gebruikers gebruikt, terwijl andere door slechts een klein percentage worden gebruikt. Dit komt zowel door de eigenaardigheden van de zoekmachines zelf, als door de gevestigde mening dat Yandex en Goggle cool zijn, en de rest probeert ze gewoon bij te houden.
Weet je wie Yandex en Goggle heeft uitgevonden? Hier .
Wat is een zoekmachine?
Een zoekmachine is een dienst die informatie zoekt op het World Wide Web volgens een bepaalde zoekopdracht van een gebruiker. Om deze informatie te vinden, moet u de website van de zoekmachine openen en een zoekopdracht formuleren. Het is niet nodig om hele zinnen in de zoekbalk te schrijven. Zoekmachines zijn tegenwoordig al zo 'slim' dat ze het verzoek van de gebruiker letterlijk uit een half woord kunnen begrijpen.
IN moderne wereld er is praktisch niemand die niet minstens één keer in zijn leven naar iets op het World Wide Web heeft gezocht. Zoekmachines, waarmee we zoeken, zijn al stevig in ons leven getreden - we "googlen" de titels van films en boeken, de namen en adressen van mensen, culinaire recepten en studentenwerk.
Het is moeilijk voor te stellen hoe moeilijk het voor ons was als er geen Yandex-, Google-, Mile- en andere systemen voor het ophalen van informatie waren. Je zou de namen van de sites moeten opschrijven of ze zelfs uit een reeks tekens moeten oppikken. Maar ondanks het feit dat zoekmachines een integraal onderdeel zijn van Alledaagse leven moderne man, denken maar weinig mensen na over hoe ze werken en hoe ze eruitzien.
De geschiedenis van zoekmachines
Verrassend genoeg begon de geschiedenis van zoekmachines in 1945. Het was toen dat de Amerikaanse wetenschapper Vaniver Bush voor het eerst het idee van hypertext introduceerde in een van zijn artikelen. Vervolgens nam hij ook deel aan de creatie van het eerste prototype van de zoekmachine, maar andere mensen deden het hoofdwerk.
In 1969 werkten wetenschappers van een van de bureaus aan onderzoeksproject De Verenigde Staten hebben een concept gecreëerd waarmee je informatie kunt overdragen via een computernetwerk. deze ontwikkeling ze wilden het voor militaire doeleinden gebruiken, maar de verbinding bleek te zwak en er kon informatie worden gelekt. Het werk aan het concept stopte, maar werd in 1980 weer hervat. Deze keer was het mogelijk om de informatiebibliotheek van Amerikaanse universiteiten te verenigen met behulp van computernetwerken.
Het eerste echte prototype van moderne zoekmachines verscheen in het midden van de jaren negentig, toen catalogi van sites werden gemaakt die konden worden doorzocht. Er waren ook zoekmachine-bots, maar die konden hun taken niet meer aan na de ontwikkeling van internet en het verschijnen van een groot aantal sites.
Sinds 1995 zijn moderne zoekmachines begonnen met hun werk op het World Wide Web - Yahoo, Google, Yandex en anderen.
Hoe zoekmachines werken
Het zoeken naar informatie op internet door een zoekmachine bestaat uit drie fasen:
- Studie van alle sites - scannen;
- Indexeren;
- Variërend
In de eerste fase dwaalt de zoekmachine rond op het World Wide Web en bestudeert de inhoud van elke site. Als je bedenkt hoeveel sites er op internet zijn vertegenwoordigd en hoeveel informatie erop wordt weergegeven, kun je alleen maar raden hoe snel het scannen plaatsvindt. U moet het resultaat immers direct na het verzoek van de gebruiker geven.
Zoekmachines scannen speciale robots. Ze worden ook wel spinnen genoemd. Ze gaan naar elke site op internet en voeren de informatie ervan in hun database in. Op oude sites gebeurt dit periodiek, maar hoe vaak per maand bepalen de zoekmachines zelf. Wanneer een nieuwe site verschijnt, scannen robots snel alle inhoud en nemen al deze informatie voor zichzelf. Dan gebeurt alles precies hetzelfde als op andere sites.
In de tweede fase vindt het proces van het invoeren van de gevonden informatie in de database plaats. Ook hier werkt elke zoekmachine anders. Goggle neemt bijvoorbeeld alle informatie die op de site te vinden is, terwijl Yandex alleen het deel neemt dat hem nuttig lijkt. Zoekmachines categoriseren de gegevens vervolgens in onderwerpen om het later gemakkelijker te maken om ermee te werken.

In de derde fase worden sites op volgorde gerangschikt, afhankelijk van hoeveel de informatie erop overeenkomt met de zoekopdracht van de gebruiker.
Het aantal gebruikers van zoekmachines groeit elke dag, waardoor ook de populariteit van zoekmachines groeit. Misschien veranderen de functies van diensten binnenkort, gaan ze op een andere manier werken of verdwijnen ze helemaal. En gewone gebruikers kunnen zich alleen aan hen aanpassen.
Dus, hier zijn de meest voorkomende Runet-zoekmachines.
Yandex: geschiedenis van oorsprong
Google zoeken gebruiken
Het werk van Goggle lijkt bijna op het werk van Yandex. Hier ook voor het vinden Nodige informatie het is voldoende om een schriftelijk verzoek in de gewenste taal in het zoekvak te plaatsen. U kunt ook een spraakopdracht instellen. Om dit te doen, klikt u op het microfoonpictogram en doet u een zoekopdracht.
De zoekmachine helpt u niet alleen sites te vinden met: tekst informatie, maar ook de gewenste foto's, video's of nieuws. Om dit te doen, moet u een zoekopdracht instellen en vervolgens de juiste sectie onder aan de zoekbalk selecteren.
Mile-zoekmachine
- het grootste internetportaal van Runet, dat verschillende diensten combineert. Een daarvan is de Mail-zoekmachine, die relatief recentelijk verscheen - in 2003. Dit project werd gelanceerd met de bedoeling het net zo succesvol te maken als mail.ru, Odnoklassniki of Agent. Hiervoor werd gebruik gemaakt van de ontwikkelingen van Google WebSearch, werd de dienst geïntegreerd met List.mail.ru, maar toch werd de zoekmachine niet zo populair als bijvoorbeeld Yandex.
Desondanks heeft mail.ru zijn eigen kenmerken die het onderscheiden van andere vergelijkbare services. De zoekopdracht daarin wordt dus niet alleen op internet uitgevoerd, maar ook in de Mail-services zelf. Ook kan de zoekmachine onderscheid maken tussen de titels van films en boeken, eerdere gebruikersverzoeken onthouden en informatie verstrekken over soortgelijke verzoeken. In de toekomst, de schepping speciale service voor webmasters, waar u informatie kunt krijgen over:
- zoekopdrachten die van belang zijn voor gebruikers van zoekmachines;
- bezochte pagina's;
- gedownloade bestanden;
- cache van bezochte pagina's;
- beoordeling van websiteverkeer.
Momenteel staat de Mail-zoekmachine op de derde plaats in populariteit in Runet en verwerkt bijna 6% van alle internetvragen in de Russische Federatie.
E-mail zoeken gebruiken
In tegenstelling tot Google en Yandex bevindt de zoekbalk van Mail zich bovenaan de hoofdpagina. Maar het zoekalgoritme is hetzelfde. Om informatie te vinden, voert u een zoekopdracht in en klikt u op het vergrootglaspictogram. Vergelijkbaar met de belangrijkste zoekmachines van Runet en secties van Mail. Hier kunt u ook foto's en video's vinden, maar daarnaast zijn "applicaties" en "antwoorden" beschikbaar. Door de eerste sectie te selecteren, kunt u de talrijke tools van de dienst gebruiken. Met de tweede kunt u informatie vinden in Mail.Answers.
En in dit artikel schreef ik uitgebreid over diensten.
Zoekmachine Rambler
wandelaar- de allereerste Runet-zoekmachine en een enorme informatie ruimte. De geschiedenis begon in 1991. In die tijd begon het internet als zodanig in Rusland net op te komen en werd het alleen in grote organisaties gebruikt. Deze organisaties omvatten instituten van de Russische Academie van Wetenschappen, en een van hen begon te gebruiken lokaal netwerk gegevens uitwisselen tussen medewerkers. Later werd het netwerk aangesloten op het internet.
Na vijf jaar succesvol gebruik op een netwerkgebaseerd Russische programmeur Dmitry Kryukov creëerde een zoekmachine genaamd Rambler, wat "zwerver" betekent. Deze naam weerspiegelt volledig de essentie van niet alleen deze zoekmachine, maar ook alle andere.
Nu, 16 jaar later, bestaat Rambler als een systeem met een verscheidenheid aan tools - games, weer, nieuws, goederen, kaarten, enz. Het is goed voor 0,4% van de Runet-zoekopdrachten.
In 2012 onderging de dienst de belangrijkste wijzigingen: de vormgeving veranderde, nieuws werd standaard weergegeven. Maar vrijwel onmiddellijk daarna besloot het management een overeenkomst met Yandex te sluiten en over te gaan tot het zoeken. Dat wil zeggen, nu worden verzoeken van Rambler verwerkt en uitgegeven door Yandex, en de service zelf werkt op basis van zijn andere tools.
Hoe de Rambler-zoekopdracht te gebruiken
Zoeken in Rambler is niet anders dan zoeken in andere vergelijkbare services. De gebruiker stelt het commando in de zoekbalk in en na het klikken op "vinden" worden de resultaten weergegeven. Naast tekstuele informatie vindt u hier ook afbeeldingen.
Andere zoekmachines van Runet
Zoekmachine Nigma
Nigma is de meest intelligente zoekmachine die in 2004 is gemaakt door programmeurs Viktor Lavrenko en Vladimir Chernyshov. Het verschilt van andere vergelijkbare diensten doordat het niet alleen zijn eigen zoekalgoritme gebruikt, maar ook gegevens van andere zoekmachines. Met Nigma kun je ook filters gebruiken om snel de informatie te vinden die je nodig hebt.
Hier kun je apart zoeken naar films, muziek, afbeeldingen, links en zelfs tools die leerlingen helpen met huiswerk. De filterfunctie wordt clustering genoemd. In eerste instantie is Nigma bedacht als een slimme zoekmachine die tijd bespaart. Daarom zijn er filters gemaakt.
Ondanks alle chips van Nigma is het niet zo populair als Yandex, Google, Mile en zelfs Rambler. Het is goed voor slechts 0,1% van alle zoekopdrachten in zoekmachines. Misschien is dat de reden waarom sinds september 2017 de website nigma.rf niet meer beschikbaar is voor gebruik, maar er zijn nog geen officiële aankondigingen over de sluiting van het project.
Zoekmachine Spoetnik
Satelliet- Russische officiële zoekmachine, die in 2014 op de markt verscheen. De maker is het bedrijf Rostelecom.
De geschiedenis van Spoetnik begon in 2010, toen de regering van de Russische Federatie de noodzaak aankondigde om een nationale zoekmachine te creëren. De reden hiervoor was de onmogelijkheid om bestaande zoekmachines te controleren, aangezien ze geen staatseigendom zijn. In 2011 steunde president Dmitry Medvedev het idee, en al in 2013 had het project een naam en bereidde het zich voor op lancering. Op 22 mei werd het gelanceerd in bètatestmodus.
Naast het zoeken naar informatie biedt Spoetnik diensten aan zoals "Weer", "Geneeskunde", "TV-programma", "Kaarten", "Financiën", "Afisha", enz. Maar desondanks namen internetgebruikers de zoekmachine zonder veel enthousiasme waar en in 2017 werd het project niet succesvol verklaard.
Hoe de satellietzoekfunctie te gebruiken
Een andere Russische zoekmachine Sputnik heeft een eenvoudige en gebruiksvriendelijke interface. Om er informatie in te zoeken, voert u gewoon een zoekopdracht in het zoekvak in en klikt u op de knop "vinden". Het enige dat deze service fundamenteel verschilt van soortgelijke, is de kwaliteit van het resultaat. Dat wil zeggen, Spoetnik zal niet zoveel zoekresultaten geven als andere, meer populaire.
Aport-zoekmachine
Ik heb een tijd gevonden dat we het actief gebruikten. Ik vond hem leuk. poort as a zoekmachine werd in 1996 opgericht door Agama, een van de leiders in softwareontwikkeling. Aanvankelijk doorzocht de service slechts één site, maar na verloop van tijd waren er meer, en toen werd het zoeken in de hele Runet mogelijk.
Tot 2000 hield Aport hoge posities in Runet samen met Yandex en Google. De ontwikkelaars veranderden het ontwerp verschillende keren, introduceerden andere tools dan zoeken, maar toch begon het terrein te verliezen.
In 2011 sloot Aport een overeenkomst met Yandex en stapte over op zijn motor. Sinds die tijd bestaat de zoekmachine niet meer als vertrouwd voor gebruikers. Nu is het een dienst om prijzen voor verschillende goederen te zoeken en deze te vergelijken met die in andere winkels.

Hoe Aport te gebruiken?
Aport is een zoekmachine, maar vindt alleen producten met prijzen. Om dit te doen, moet u het gewenste product uit de catalogus selecteren en de service toont de prijzen ervoor in verschillende winkels. Dan kun je met meer naar de winkel gunstige prijs en koop wat je nodig hebt.
De service heeft veel secties met een grote verscheidenheid aan producten. Dankzij hem kun je veel besparen.
Bing-zoekmachine
Bing- een zoekmachine van Microsoft, die het derde project van het bedrijf werd en het meest succesvolle. Het management van Microsoft droomde er al lang van om een eigen zoekmachine te creëren en voor het eerst werd de droom werkelijkheid in 1998, toen het MSN Search-project op de markt verscheen. Maar het idee werd helemaal niet met enthousiasme ontvangen door internetgebruikers. En geen wonder, aangezien de zoekmachine niets de moeite waard was.
In 2006 verscheen Windows Live Search werd een jaar later vervangen door Live Search, maar beide waren ook niet succesvol bij gebruikers.
Eindelijk in 2009 Microsoft jaar heeft een nieuwe service aangekondigd - Bing. Ondanks de mislukkingen van zijn voorgangers heeft de zoekmachine zichzelf in korte tijd fans verdiend. Binnen een jaar, in termen van het aantal gebruikers, haalde het Yahoo in, wat op zich al een verbazingwekkend fenomeen is, en even later kwam het op de lijst van de beste zoekmachines ter wereld.

In Runet is Bing veel minder populair dan op het hele World Wide Web. belangrijkste reden Dit is dat de zoekmachine heel weinig Russisch-talige sites weergeeft. Bovendien is het in RuNet bijna onmogelijk om die zoekmachines te verplaatsen die zich hebben gevestigd.
Naast de meest populaire, zijn er ook een groot aantal zoekmachines die weinig bekend zijn, maar nog steeds door sommige gebruikers worden gebruikt. In China wordt dus meer dan 60% van de zoekopdrachten verwerkt door de Baidu-zoekmachine.
Bing heeft een goed dashboard voor webmasters. Zorg ervoor dat u uw site daar toevoegt.
Bing gebruiken
Zoeken op Bing is net zo handig als de meeste andere zoekmachines. Om hier een site met tekstuele informatie, een afbeelding, een video of nieuws te vinden, typt u de juiste zoekopdracht in de zoekbalk. De zoekmachine vindt informatie zowel op Russische als op buitenlandse sites.
Het belangrijkste verschil tussen Bing en andere services met vergelijkbare functionaliteit is de interface met: mooi ontwerp. In tegenstelling tot dezelfde Google is standaard een kleurrijke achtergrond ingesteld.
Vergelijking van populaire Runet-zoekmachines: waar moet je op letten?
Zoekmachines zijn beter hoe meer Precieze informatie kan worden uitgegeven als reactie op een gebruikersverzoek. Tegenwoordig is Google het populairste systeem op internet en op Runet Yandex. Afgaande op de kwaliteit van het probleem, hebben ze ongeveer hetzelfde, maar toch is het gemakkelijker om iets in Goggle te vinden, over iets - in Yandex. Hetzelfde geldt voor andere zoekmachines. Elk van hen is gericht op een bepaalde categorie gebruikers en verzoeken.
De taak van alle zoekmachines is om informatie te vinden, maar elk van hen doet dit op zijn eigen manier. Ze hebben allemaal hun eigen zoekalgoritme en hun eigen kenmerken. Laten we Yandex nemen. Hier kun je bijna alles vinden, maar het is meer gericht op Russischtalige sites. Dat wil zeggen, als u informatie in het Russisch zoekt over een Russische schrijver, heeft u beslist geen andere bron nodig. Maar als u een artikel in het Engels nodig heeft, moet u zich al wenden tot Goggle of Bing. Hetzelfde kan gezegd worden over buitenlandse video's en nieuws. Er zijn er genoeg in de secties met dezelfde naam van deze zoekmachines.
De satelliet is ook gericht op Russisch sprekende gebruikers en het is onwaarschijnlijk dat u hier veel informatie in vreemde talen zult vinden. Hoogstwaarschijnlijk zullen de resultaten iets bevatten dat lijkt op de informatie die u zoekt, maar dan in het Russisch.
Mile en Rambler lijken qua resultaten op Yandex, maar het zal in zeer zeldzame gevallen lukken om hier iets te vinden dat niet in de hoofdzoekmachine van Runet staat. Tegelijkertijd kan Mile worden gebruikt om te zoeken in de Answers-service, waar vaak de benodigde informatie te vinden is.
Aport is een specifieke zoekmachine en is ontworpen om naar goederen te zoeken. Als u dus van plan bent te gaan winkelen en op zoek bent naar geweldige aanbiedingen, zal deze service u zeker helpen. Door prijzen in populaire online winkels te vergelijken, kunt u de beste opties vinden.
Welke zoekmachine gebruik je?
Weet u wanneer de eerste site werd gelanceerd? Gok?. Alles voor nu.