Van vc.ru, hoe je in een paar stappen een eenvoudig neuraal netwerk maakt en het leert beroemde ondernemers op foto's te herkennen.
Stap 0. Begrijpen hoe neurale netwerken werken
De gemakkelijkste manier om de principes van neurale netwerken te begrijpen, is de Teachable Machine, een educatief project van Google.
Als input - wat verwerkt moet worden door het neurale netwerk - gebruikt de Teachable Machine een beeld van een laptopcamera. Als output - wat het neurale netwerk moet doen na het verwerken van de binnenkomende gegevens - kun je een GIF of geluid gebruiken.

U kunt de leerbare machine bijvoorbeeld leren 'hallo' te zeggen met uw handpalm naar boven. Met de duim omhoog - "Cool", en met een verbaasd gezicht met een open mond - "Wow".
Eerst moet je het neurale netwerk trainen. Om dit te doen, hef je je handpalm op en klik je op de Train Green-knop - de service maakt enkele tientallen foto's om een patroon in de afbeeldingen te vinden. Een set van dergelijke snapshots wordt gewoonlijk een "dataset" genoemd.
Nu blijft het om de actie te kiezen die moet worden aangeroepen bij herkenning van de afbeelding - zeg een zin, laat een GIF zien of speel een geluid af. Op dezelfde manier trainen we het neurale netwerk om een verrast gezicht en een duim te herkennen.
Zodra het neurale netwerk is getraind, kan het worden gebruikt. De leerbare machine laat de "vertrouwensfactor" zien - hoe zeker het systeem is dat het een van de vaardigheden wordt getoond.
Stap 1. De computer voorbereiden om met een neuraal netwerk te werken
Laten we nu ons eigen neurale netwerk maken, dat bij het verzenden van een afbeelding zal rapporteren wat op de afbeelding wordt getoond. Eerst leren we het neurale netwerk bloemen te herkennen in een afbeelding: kamille, zonnebloem, paardenbloem, tulp of roos.
Om je eigen neurale netwerk te maken, heb je Python nodig - een van de meest minimalistische en meest voorkomende programmeertalen, en TensorFlow - de open bibliotheek van Google voor het maken en trainen van neurale netwerken.
Python installeren
Dienovereenkomstig neemt het neurale netwerk twee getallen als invoer en moet het een ander getal aan de uitgang geven - het antwoord. Nu over de neurale netwerken zelf.Wat is een neuraal netwerk?

Een neuraal netwerk is een opeenvolging van neuronen die verbonden zijn door synapsen. De structuur van het neurale netwerk kwam rechtstreeks uit de biologie naar de programmeerwereld. Dankzij deze structuur verwerft de machine de mogelijkheid om verschillende informatie te analyseren en zelfs te onthouden. Neurale netwerken zijn ook in staat om niet alleen binnenkomende informatie te analyseren, maar ook om deze uit hun geheugen te reproduceren. Voor geïnteresseerden, bekijk zeker 2 video's van TED Talks: Video 1 , Video 2). Met andere woorden, een neuraal netwerk is een machinale interpretatie van het menselijk brein, dat miljoenen neuronen bevat die informatie doorgeven in de vorm van elektrische impulsen.
Wat zijn neurale netwerken?
Voor nu zullen we voorbeelden bekijken van het meest elementaire type neurale netwerken - dit is een feedforward-netwerk (hierna FNS genoemd). Ook in volgende artikelen zal ik meer concepten introduceren en vertellen over terugkerende neurale netwerken. DSS is, zoals de naam al aangeeft, een netwerk met een seriële verbinding van neurale lagen, waarin informatie altijd maar in één richting gaat.Waar zijn neurale netwerken voor?
Neurale netwerken worden gebruikt om complexe problemen op te lossen die analytische berekeningen vereisen die vergelijkbaar zijn met die van het menselijk brein. De meest voorkomende toepassingen voor neurale netwerken zijn:Classificatie- gegevensverdeling per parameters. Er wordt bijvoorbeeld een groep mensen bij de ingang gegeven en het is noodzakelijk om te beslissen wie van hen een lening geeft en wie niet. Dit werk kan worden gedaan door een neuraal netwerk dat informatie zoals leeftijd, solvabiliteit, kredietgeschiedenis, enz. analyseert.
Voorspelling- het vermogen om de volgende stap te voorspellen. Bijvoorbeeld de stijging of daling van een aandeel op basis van de situatie op de aandelenmarkt.
Erkenning- momenteel het meest wijdverbreide gebruik van neurale netwerken. Gebruikt op Google wanneer u op zoek bent naar een foto of in telefooncamera's wanneer het de positie van uw gezicht detecteert en het opvalt en nog veel meer.
Laten we nu, om te begrijpen hoe neurale netwerken werken, eens kijken naar de componenten en hun parameters.
Wat is een neuron?

Een neuron is een rekeneenheid die informatie ontvangt, er eenvoudige berekeningen op uitvoert en deze verder doorstuurt. Ze zijn onderverdeeld in drie hoofdtypen: ingang (blauw), verborgen (rood) en uitgang (groen). Er is ook een bias-neuron en een context-neuron, waar we het in het volgende artikel over zullen hebben. In het geval dat een neuraal netwerk uit een groot aantal neuronen bestaat, wordt de term laag geïntroduceerd. Dienovereenkomstig is er een invoerlaag die informatie ontvangt, n verborgen lagen (meestal niet meer dan 3) die deze verwerken en een uitvoerlaag die het resultaat uitvoert. Elk van de neuronen heeft 2 hoofdparameters: invoergegevens en uitvoergegevens. In het geval van een inputneuron: input = output. In de rest komt de totale informatie van alle neuronen uit de vorige laag in het invoerveld, waarna het wordt genormaliseerd met behulp van de activeringsfunctie (voor nu, representeer het gewoon f (x)) en komt in het uitvoerveld.

Belangrijk om te onthouden dat neuronen werken met getallen in het bereik of [-1,1]. Maar wat, vraag je, dan omgaan met getallen die buiten dit bereik vallen? In dit stadium is het eenvoudigste antwoord om 1 te delen door dat getal. Dit proces wordt normalisatie genoemd en wordt heel vaak gebruikt in neurale netwerken. Hierover later meer.
Wat is een synaps?

Een synaps is een verbinding tussen twee neuronen. Synapsen hebben 1 parameter - gewicht. Dankzij hem verandert de invoerinformatie wanneer deze van het ene neuron naar het andere wordt verzonden. Laten we zeggen dat er 3 neuronen zijn die informatie doorgeven aan de volgende. Dan hebben we 3 gewichten die overeenkomen met elk van deze neuronen. Voor het neuron met het grootste gewicht zal die informatie dominant zijn in het volgende neuron (bijvoorbeeld kleurmenging). In feite is de set gewichten van een neuraal netwerk of een matrix van gewichten een soort brein van het hele systeem. Dankzij deze gewichten wordt de ingevoerde informatie verwerkt en omgezet in een resultaat.
Belangrijk om te onthouden dat tijdens de initialisatie van het neurale netwerk de gewichten willekeurig worden toegewezen.
Hoe werkt een neuraal netwerk?

In dit voorbeeld is een deel van een neuraal netwerk afgebeeld, waarbij de letters I de inputneuronen aanduiden, de letter H de verborgen neuron en de letter w de gewichten. Uit de formule blijkt dat de invoerinformatie de som is van alle invoergegevens vermenigvuldigd met de bijbehorende gewichten. Dan geven we de invoer 1 en 0. Zij w1 = 0,4 en w2 = 0,7 De invoergegevens van het neuron H1 zullen als volgt zijn: 1 * 0,4 + 0 * 0,7 = 0,4. Nu we de invoer hebben, kunnen we de uitvoer krijgen door de invoer in de activeringsfunctie te steken (daarover later meer). Nu we de output hebben, geven we deze door. En dus herhalen we voor alle lagen totdat we bij het uitgangsneuron komen. Als we voor de eerste keer zo'n netwerk starten, zullen we zien dat het antwoord verre van correct is, omdat het netwerk niet is getraind. We gaan haar trainen om haar resultaten te verbeteren. Maar voordat we leren hoe we dit moeten doen, laten we eerst een paar termen en eigenschappen van een neuraal netwerk introduceren.
Activeringsfunctie:
Een activeringsfunctie is een manier om invoergegevens te normaliseren (we hebben hier eerder over gesproken). Dat wil zeggen, als u een groot aantal bij de ingang hebt, nadat u het door de activeringsfunctie hebt geleid, krijgt u een uitgang in het bereik dat u nodig hebt. Er zijn veel activeringsfuncties, dus we zullen de meest elementaire functies beschouwen: lineair, sigmoid (logistiek) en hyperbolische tangens. Hun belangrijkste verschil is het bereik van waarden.Lineaire functie
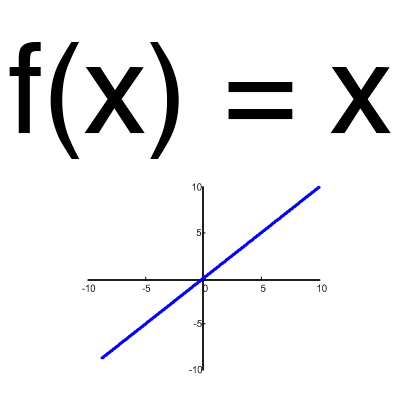
Deze functie wordt bijna nooit gebruikt, behalve wanneer u een neuraal netwerk moet testen of een waarde moet overdragen zonder transformaties.
sigmoïde

Dit is de meest voorkomende activeringsfunctie en het bijbehorende waardenbereik. Hierop worden de meeste voorbeelden op het web getoond, het wordt ook wel de logistieke functie genoemd. Dienovereenkomstig, als er in uw geval negatieve waarden zijn (aandelen kunnen bijvoorbeeld niet alleen stijgen, maar ook dalen), dan heeft u een functie nodig die ook negatieve waarden vastlegt.
hyperbolische tangens

Het is logisch om de hyperbolische tangens alleen te gebruiken wanneer uw waarden zowel negatief als positief kunnen zijn, aangezien het bereik van de functie [-1,1] is. Het is ongepast om deze functie alleen met positieve waarden te gebruiken, omdat dit de resultaten van uw neurale netwerk aanzienlijk zal verslechteren.
Trainingsset
Een trainingsset is een reeks gegevens waarop een neuraal netwerk werkt. In ons geval, de exclusieve of (xor) hebben we slechts 4 verschillende uitkomsten, dat wil zeggen dat we 4 trainingssets hebben: 0xor0 = 0, 0xor1 = 1, 1xor0 = 1.1xor1 = 0.iteratie
Dit is een soort teller die elke keer dat het neurale netwerk één trainingsset doorloopt, hoger wordt. Met andere woorden, dit is het totale aantal trainingssets dat door het neurale netwerk wordt doorlopen.Tijdperk
Bij het initialiseren van het neurale netwerk wordt deze waarde op 0 gezet en is er een handmatig ingesteld plafond. Hoe groter het tijdperk, hoe beter het netwerk is getraind en dus ook het resultaat. Het tijdperk neemt toe elke keer dat we de hele set trainingssets doorlopen, in ons geval 4 sets of 4 iteraties.
Belangrijk verwar iteratie niet met tijdperk en begrijp de volgorde van hun toename. Eerste n
zodra de iteratie toeneemt, en dan het tijdperk en niet omgekeerd. Met andere woorden, je kunt een neuraal netwerk niet eerst op de ene set trainen, dan op een andere, enz. Je moet elke set één keer per tijdperk trainen. Zo voorkom je fouten in berekeningen.
Fout
Fout is een percentage dat de discrepantie aangeeft tussen verwachte en ontvangen reacties. De fout wordt elk tijdperk gevormd en zou moeten afnemen. Gebeurt dit niet, dan doe je iets niet goed. De fout kan op verschillende manieren worden berekend, maar we zullen slechts drie hoofdmanieren beschouwen: Mean Squared Error (hierna MSE), Root MSE en Arctan. Er is geen beperking op het gebruik zoals in de activeringsfunctie, en u bent vrij om te kiezen welke methode u de beste resultaten geeft. Men hoeft er alleen rekening mee te houden dat elke methode fouten op verschillende manieren telt. In Arctan zal de fout bijna altijd groter zijn, omdat het werkt volgens het principe: hoe groter het verschil, hoe groter de fout. Root MSE zal de kleinste fout hebben, daarom wordt meestal MSE gebruikt, wat een balans houdt in de foutberekening.Veel van de termen in neurale netwerken zijn biologisch verwant, dus laten we bij het begin beginnen:
Het brein is een complex iets, maar het kan ook worden onderverdeeld in verschillende hoofdonderdelen en operaties:

De veroorzaker kan zijn: intern(zoals een afbeelding of een idee):

Laten we nu eens kijken naar de basis en vereenvoudigd onderdelen brein:

De hersenen zijn over het algemeen als een bedraad netwerk.
neuron- de basiseenheid van calculus in de hersenen, het ontvangt en verwerkt chemische signalen van andere neuronen, en doet, afhankelijk van een aantal factoren, ofwel niets, of genereert een elektrische impuls, of een actiepotentiaal, dat vervolgens signalen naar naburige degenen door synapsen gebonden neuronen:

Dromen, herinneringen, zelfregulerende bewegingen, reflexen en in het algemeen alles wat je denkt of doet - alles gebeurt dankzij dit proces: miljoenen of zelfs miljarden neuronen werken op verschillende niveaus en creëren verbindingen die verschillende parallelle subsystemen creëren en een biologische vertegenwoordiging vertegenwoordigen. neuraal netto-.
Natuurlijk zijn dit allemaal vereenvoudigingen en generalisaties, maar dankzij hen kunnen we een eenvoudige
neuraal netwerk:

En om het te beschrijven geformaliseerd met behulp van een grafiek:

Enige verduidelijking is hier vereist. De cirkels zijn neuronen, en de lijnen zijn de verbindingen ertussen,
en om het in dit stadium niet ingewikkeld te maken, onderlinge verbinding vertegenwoordigen de directe beweging van informatie van links naar rechts... Het eerste neuron is momenteel actief en grijs gemarkeerd. We hebben er ook een nummer aan toegekend (1 - als het werkt, 0 - zo niet). De getallen tussen neuronen tonen: gewicht communicatie.
De grafieken hierboven tonen het moment in de tijd van het netwerk, voor een nauwkeurigere weergave moet u het in tijdsintervallen verdelen:

Om uw eigen neurale netwerk te creëren, moet u begrijpen hoe gewichten neuronen beïnvloeden en hoe neuronen worden getraind. Laten we als voorbeeld een konijn (testkonijn) nemen en het onder de voorwaarden van een klassiek experiment plaatsen.

Wanneer een veilige luchtstroom op hen wordt gericht, knipperen konijnen, net als mensen:

Dit gedrag kan worden getekend met grafieken:

Net als in het vorige diagram tonen deze grafieken alleen het moment waarop het konijn de adem voelt, en dus kunnen we codering snuf als boolean. Daarnaast berekenen we op basis van de gewichtswaarde of het tweede neuron vuurt. Als het gelijk is aan 1, dan wordt het sensorische neuron geactiveerd, we knipperen; als het gewicht minder is dan 1, knipperen we niet: het tweede neuron heeft begrenzing- 1.
Laten we nog een element introduceren - een veilig geluidssignaal:

We kunnen konijneninteresse als volgt modelleren:

Het belangrijkste verschil is dat het gewicht nu is nul dus we kregen geen knipperend konijn, nou ja, in ieder geval nog niet. Nu gaan we het konijn leren knipperen op commando, mixen
irriterende stoffen (piep en adem):

Het is belangrijk dat deze evenementen op verschillende tijdstippen plaatsvinden tijdperken, in grafieken ziet het er als volgt uit:

Het geluid zelf doet niets, maar de luchtstroom laat het konijn nog steeds knipperen, en dit laten we zien door de gewichten maal de prikkels (in rood).
Onderwijs complex gedrag kan worden vereenvoudigd als een geleidelijke verandering in gewicht tussen gekoppelde neuronen in de loop van de tijd.
Herhaal de stappen om het konijn te trainen:

Voor de eerste drie pogingen zien de circuits er als volgt uit:

Houd er rekening mee dat het gewicht voor de geluidsstimulus na elke herhaling toeneemt (rood gemarkeerd), deze waarde is nu willekeurig - we hebben 0,30 gekozen, maar het aantal kan van alles zijn, zelfs negatief. Na de derde herhaling merk je geen verandering in het gedrag van het konijn, maar na de vierde herhaling zal er iets verbazingwekkends gebeuren - het gedrag zal veranderen.

We hebben de belichting met lucht verwijderd, maar het konijn knippert nog steeds als hij de piep hoort! Ons laatste diagram kan dit gedrag verklaren:

We hebben het konijn getraind om op geluid te reageren door te knipperen.

Bij een echt experiment als dit kan het meer dan 60 herhalingen kosten om het resultaat te bereiken.
Nu zullen we de biologische wereld van de hersenen en konijnen verlaten en proberen alles aan te passen dat
geleerd om een kunstmatig neuraal netwerk te creëren. Laten we eerst proberen een eenvoudige taak uit te voeren.
Laten we zeggen dat we een machine met vier knoppen hebben die voedsel afgeeft wanneer de juiste wordt ingedrukt.
knoppen (nou ja, of energie als je een robot bent). De taak is om erachter te komen welke knop de beloning geeft:

We kunnen (schematisch) weergeven wat de knop doet als deze als volgt wordt ingedrukt:

Het is beter om zo'n probleem in zijn geheel op te lossen, dus laten we eens kijken naar alle mogelijke resultaten, inclusief de juiste:

Klik op de 3e knop om je diner te halen.
Om een neuraal netwerk in code te reproduceren, moeten we eerst een model of grafiek maken waarmee we het netwerk in kaart kunnen brengen. Hier is een grafiek die geschikt is voor de taak, bovendien geeft het zijn biologische tegenhanger goed weer:

Dit neurale netwerk ontvangt eenvoudigweg invoer - in dit geval is het de perceptie op welke knop is gedrukt. Vervolgens vervangt het netwerk de invoerinformatie door gewichten en trekt het een gevolgtrekking op basis van de toevoeging van de laag. Het klinkt een beetje verwarrend, maar laten we eens kijken hoe de knop in ons model wordt weergegeven:

Merk op dat alle gewichten 0 zijn, dus het neurale netwerk is, net als een baby, volledig leeg maar volledig met elkaar verbonden.
We associëren de externe gebeurtenis dus met de invoerlaag van het neurale netwerk en berekenen de waarde aan de uitvoer. Het kan al dan niet samenvallen met de realiteit, maar we zullen dit voor nu negeren en beginnen de taak op een voor de computer begrijpelijke manier te beschrijven. Laten we beginnen met het invoeren van de gewichten (we gebruiken JavaScript):
Var ingangen =; var gewichten =; // Voor het gemak kunnen deze vectoren worden genoemd
De volgende stap is het maken van een functie die de invoerwaarden en gewichten verzamelt en de uitvoerwaarde berekent:
Functie evaluatieNeuralNetwork (inputVector, weightVector) (var resultaat = 0; inputVector.forEach (functie (inputValue, weightIndex) (layerValue = inputValue * weightVector; result + = layerValue;)); return (result.toFixed (2));) / / Het lijkt misschien ingewikkeld, maar het enige wat het doet is het matchen van het gewicht / de invoerparen en het resultaat toevoegen
Zoals verwacht, als we deze code uitvoeren, krijgen we hetzelfde resultaat als in ons model of onze grafiek ...
EvaluateNeuralNetwork (invoeren, gewichten); // 0,00
Live voorbeeld: Neural Net 001.
De volgende stap in het verbeteren van ons neurale netwerk zal een manier zijn om zijn eigen output of resulterende waarden te controleren die vergelijkbaar zijn met de werkelijke situatie,
laten we eerst deze specifieke realiteit coderen in een variabele:

Om inconsistenties te detecteren (en hoeveel), voegen we een foutfunctie toe:
Fout = Realiteit - Neurale netto-uitvoer
Hiermee kunnen we de prestaties van ons neurale netwerk evalueren:

Maar nog belangrijker, hoe zit het met situaties waarin de realiteit gunstig is?

Nu weten we dat ons neurale netwerkmodel niet werkt (en we weten hoeveel), geweldig! Dit is geweldig omdat we nu de foutfunctie kunnen gebruiken om ons leren te beheersen. Maar dit alles is logisch als we de foutfunctie als volgt opnieuw definiëren:
Fout = Gewenste output- Neurale netto-uitvoer
Een onmerkbare maar zo belangrijke discrepantie, die stilzwijgend laat zien dat we zullen
eerder verkregen resultaten gebruiken voor vergelijking met toekomstige acties
(en voor training, zoals we later zullen zien). Dit bestaat ook in het echt, compleet
herhalende patronen, zodat het een evolutionaire strategie kan worden (nou ja, in
in de meeste gevallen).
Var-invoer =; var gewichten =; var gewenstResult = 1;
En een nieuwe functie:
Functie evaluatieNeuralNetError (gewenst, actueel) (retour (gewenst - actueel);) // Na evaluatie van zowel het netwerk als de fout zouden we krijgen: // "Neural Net output: 0.00 Error: 1"
Live voorbeeld: Neural Net 002.
Laten we het tussentijdse resultaat samenvatten... We begonnen met een probleem, maakten er een eenvoudig model van in de vorm van een biologisch neuraal netwerk en kregen een manier om de prestaties ervan te meten in vergelijking met de werkelijkheid of het gewenste resultaat. Nu moeten we een manier vinden om de inconsistentie te corrigeren - een proces dat kan worden gezien als leren voor zowel computers als mensen.
Hoe train je een neuraal netwerk?
De basis voor het leren van zowel biologische als kunstmatige neurale netwerken is herhaling
en leeralgoritmen dus we zullen afzonderlijk met hen werken. Laten we beginnen met
trainingsalgoritmen.
In de natuur worden leeralgoritmen begrepen als veranderingen in fysisch of chemisch
kenmerken van neuronen na experimenten:

Een dramatische illustratie van hoe twee neuronen in de loop van de tijd veranderen in de code en ons 'leeralgoritme'-model betekent dat we in de loop van de tijd gewoon iets zullen veranderen om ons leven gemakkelijker te maken. Laten we daarom een variabele toevoegen om de mate van levensgemak aan te geven:
Var leersnelheid = 0,20; // Hoe hoger de waarde, hoe sneller het leerproces zal zijn :)
En wat maakt dat uit?
Dit zal de gewichten veranderen (net als een konijn!), Vooral het gewicht van de output die we willen krijgen:

Hoe je zo'n algoritme codeert is jouw keuze, voor de eenvoud voeg ik de leerfactor toe aan het gewicht, hier is het als een functie:
Functie leren (inputVector, weightVector) (weightVector.forEach (functie (weight, index, weights) (if (inputVector> 0) (weights = weight + learningRate;)));)
Indien gebruikt, zal deze leerfunctie eenvoudig onze leerfactor toevoegen aan de gewichtsvector actief neuron, voor en na de leerronde (of herhaling), zijn de resultaten als volgt:
// Oorspronkelijke gewichtsvector: // Neurale netto-uitvoer: 0,00 Fout: 1 leren (invoer, gewichten); // Nieuwe gewichtsvector: // Neurale netto-output: 0,20 Error: 0.8 // Als het niet duidelijk is, is de output van het neurale netwerk dicht bij 1 (output van een kip) - dat is wat we wilden, dus we kunnen concluderen dat we gaan de goede kant op
Live voorbeeld: Neural Net 003.
Oké, nu we de goede kant op gaan, zal het laatste stukje van deze puzzel de implementatie zijn. herhalingen.
Het is niet zo moeilijk, in de natuur doen we gewoon steeds weer hetzelfde, en in de code specificeren we gewoon het aantal herhalingen:
Var proeven = 6;
En de implementatie van de functie van het aantal herhalingen in ons neurale trainingsnetwerk ziet er als volgt uit:
Functietrein (proeven) (voor (i = 0; i< trials; i++) {
neuralNetResult = evaluateNeuralNetwork(input, weights);
learn(input, weights);
}
}
Nou, ons eindrapport:
Neurale netto-uitvoer: 0,00 Fout: 1,00 Gewichtsvector: Neurale netto-uitvoer: 0,20 Fout: 0,80 Gewichtsvector: Neurale netto-uitvoer: 0,40 Fout: 0,60 Gewichtsvector: Neurale netto-uitvoer: 0,60 Fout: 0,40 Gewichtsvector: Neurale netto-uitvoer: 0,80 Fout : 0.20 Weight Vector: Neural Netto output: 1.00 Error: 0.00 Weight Vector: // Chicken Dinner!
Live voorbeeld: Neural Net 004.
Nu hebben we een gewichtsvector die slechts één resultaat geeft (kip voor het avondeten) als de invoervector overeenkomt met de werkelijkheid (door op de derde knop te drukken).
Dus wat is er zo cool dat we net hebben gedaan?
In dit specifieke geval kan ons neurale netwerk (na training) de invoergegevens herkennen en zeggen, wat tot het gewenste resultaat zal leiden (we moeten nog specifieke situaties programmeren):

Daarnaast is het een schaalbaar model, speeltje en tool voor onze trainingen met jou. We konden iets nieuws leren over machine learning, neurale netwerken en kunstmatige intelligentie.
Waarschuwing voor gebruikers:
- Het mechanisme voor het opslaan van de bestudeerde gewichten is niet voorzien, dus dit neurale netwerk vergeet alles wat het weet. Wanneer u de code bijwerkt of opnieuw uitvoert, heeft u ten minste zes succesvolle pogingen nodig om het netwerk volledig te laten leren of u denkt dat een persoon of een machine in willekeurige volgorde op knoppen zal drukken ... Het zal enige tijd duren.
- Biologische netwerken voor het leren van belangrijke dingen hebben een leersnelheid van 1, dus er is slechts één succesvolle herhaling nodig.
- Er is een leeralgoritme dat sterk lijkt op biologische neuronen, met een pakkende naam: Widroff-hoff regel, of Widroff-hoff training.
- Neurondrempels (1 in ons voorbeeld) en overfitting-effecten (bij een groot aantal herhalingen zal het resultaat groter zijn dan 1) worden niet in aanmerking genomen, maar ze zijn erg belangrijk van aard en zijn verantwoordelijk voor grote en complexe gedragsblokken. reacties. Dat geldt ook voor negatieve gewichten.
Noten en bibliografie om verder te lezen
Ik heb geprobeerd de wiskundige en harde termen te vermijden, maar als je geïnteresseerd bent, we hebben een perceptron gebouwd, dat wordt gedefinieerd als een algoritme voor begeleid leren (supervised learning) voor dubbele classificaties - een moeilijke zaak.De biologische structuur van de hersenen is geen gemakkelijk onderwerp, deels vanwege onnauwkeurigheid, deels vanwege de complexiteit ervan. Het is beter om te beginnen met Neuroscience (Purves) en Cognitive Neuroscience (Gazzaniga). Ik heb het konijnenvoorbeeld van Gateway to Memory (Gluck) aangepast en aangepast, wat ook een geweldige gids is voor de wereld van grafieken.
Een andere geweldige bron, An Introduction to Neural Networks (Gurney), voldoet aan al uw AI-behoeften.
Nu in Python! Met dank aan Ilya Andshmidt voor het verstrekken van de Python-versie:
Invoer = gewichten = gewenst_resultaat = 1 leersnelheid = 0,2 proeven = 6 def evalueren_neuraal_netwerk (input_array, weight_array): resultaat = 0 voor i binnen bereik (len (input_array)): layer_value = input_array [i] * weight_array [i] resultaat + = layer_value print ("evaluate_neural_network:" + str (resultaat)) print ("weights:" + str (weights)) return resultaat def evaluatiefout (gewenst, actueel): fout = gewenst - actueel print ("evaluate_error:" + str (fout) ) return error def learn (input_array, weight_array): print ("learning ...") voor i binnen bereik (len (input_array)): if input_array [i]> 0: weight_array [i] + = learning_rate def train (trials ): voor i binnen bereik (proeven): neural_net_result = evaluatie_neural_network (invoer, gewichten) leren (invoer, gewichten) trainen (proeven)
Nu op GO! Met dank aan Kieran Macher voor deze versie.
Pakket main import ("fmt" "math") func main () (fmt.Println ("Creating inputs and weights ...") inputs: = float64 (0.00, 0.00, 1.00, 0.00) weights: = float64 (0.00, 0.00, 0.00, 0.00) gewenst: = 1.00 learningRate: = 0.20 trials: = 6 train (trials, inputs, weights, wanted, learningRate)) func train (trials int, inputs float64, weights float64, gewenste float64, learningRate float64) ( voor i: = 1; i< trials; i++ { weights = learn(inputs, weights, learningRate) output:= evaluate(inputs, weights) errorResult:= evaluateError(desired, output) fmt.Print("Output: ") fmt.Print(math.Round(output*100) / 100) fmt.Print("\nError: ") fmt.Print(math.Round(errorResult*100) / 100) fmt.Print("\n\n") } } func learn(inputVector float64, weightVector float64, learningRate float64) float64 { for index, inputValue:= range inputVector { if inputValue >0.00 (weightVector = weightVector + learningRate)) return weightVector) func evaluatie (inputVector float64, weightVector float64) float64 (resultaat: = 0.00 voor index, inputValue: = bereik inputVector (layerValue: = inputValue * weightVector resultaat = resultaat + layerValue) resultaat resultaat ) func evaluatieError (gewenste float64, actual float64) float64 (return gewenst - actueel)
U kunt helpen en geld overmaken voor de ontwikkeling van de site
James Loy, Georgia Tech. Een beginnershandleiding, waarna je je eigen neurale netwerk in Python kunt maken.
Motivatie: Op basis van mijn persoonlijke ervaring met het leren van deep learning, heb ik besloten om vanaf het begin een neuraal netwerk te creëren zonder een complexe leerbibliotheek zoals. Ik geloof dat het belangrijk is voor een beginnende Data Scientist om de interne structuur te begrijpen.
Dit artikel bevat wat ik heb geleerd en hopelijk is het ook nuttig voor jou! Andere nuttige gerelateerde artikelen:
Wat is een neuraal netwerk?
De meeste artikelen over neurale netwerken trekken parallellen met de hersenen wanneer ze worden beschreven. Het is gemakkelijker voor mij om neurale netwerken te beschrijven als een wiskundige functie die een gegeven invoer toewijst aan een gewenst resultaat zonder in details te treden.
Neurale netwerken bestaan uit de volgende componenten:
- invoerlaag, x
- willekeurig bedrag verborgen lagen
- uitvoerlaag,
- kit schubben en verplaatsingen tussen elke laag W en B
- selectie voor elke verborgen laag σ ; in dit werk zullen we de activeringsfunctie van Sigmoid . gebruiken
Het onderstaande diagram toont de architectuur van een neuraal netwerk met twee lagen (merk op dat de invoerlaag meestal wordt uitgesloten bij het tellen van het aantal lagen in het neurale netwerk).
Het maken van een Neural Network-klasse in Python ziet er eenvoudig uit:
Neurale netwerk training
Uitgang ŷ een eenvoudig tweelaags neuraal netwerk:
In de bovenstaande vergelijking zijn de gewichten W en de vooroordelen b de enige variabelen die de output ŷ beïnvloeden.
Uiteraard bepalen de juiste waarden voor de gewichten en biases de nauwkeurigheid van de voorspellingen. Het proces van fijnafstemming van gewichten en vooroordelen van invoergegevens staat bekend als.
Elke iteratie van het trainingsproces bestaat uit de volgende stappen:
- het berekenen van de voorspelde output (voorwaartse voortplanting genoemd)
- bijwerken van gewichten en vooroordelen genaamd
Onderstaande sequentiële grafiek illustreert het proces:

Directe distributie
Zoals we in de bovenstaande grafiek zagen, is voorwaartse voortplanting slechts een eenvoudige berekening, en voor een eenvoudig 2-laags neuraal netwerk wordt de uitvoer van het neurale netwerk gegeven door:
Laten we feedforward toevoegen aan onze Python-code om dit te doen. Merk op dat we voor de eenvoud hebben aangenomen dat de offsets 0 zijn.
We hebben echter een manier nodig om de "goedheid" van onze voorspellingen te beoordelen, dat wil zeggen, hoe ver onze voorspellingen zijn). Verliesfunctie stelt ons gewoon in staat om het te doen.
Verliesfunctie
Er zijn veel verliesfuncties beschikbaar en de aard van ons probleem zou onze keuze voor de verliesfunctie moeten bepalen. In dit werk gebruiken we som van kwadraten van fouten als verliesfunctie.

De som van de gekwadrateerde fouten is het gemiddelde van het verschil tussen elke voorspelde waarde en de werkelijke waarde.
Het doel van training is om een set gewichten en vooroordelen te vinden die de verliesfunctie minimaliseert.
Terugvermeerdering
Nu we onze voorspellingsfout (verlies) hebben gemeten, moeten we een manier vinden het doorgeven van de fout terug en onze gewichten en vooroordelen bijwerken.
Om de juiste hoeveelheid te vinden om te corrigeren voor de gewichten en vooroordelen, moeten we de afgeleide kennen van de verliesfunctie met betrekking tot de gewichten en vooroordelen.
Bedenk uit de analyse dat: de afgeleide van de functie is de helling van de functie.

Als we een afgeleide hebben, kunnen we de gewichten en vooroordelen eenvoudig bijwerken door ze te verhogen/verlagen (zie diagram hierboven). Het heet .
We kunnen de afgeleide van de verliesfunctie echter niet rechtstreeks berekenen met betrekking tot de gewichten en vooroordelen, aangezien de vergelijking van de verliesfunctie geen gewichten en vooroordelen bevat. Daarom hebben we een kettingregel nodig om te helpen bij de berekening.

Fuh! Het was omslachtig, maar het stelde ons in staat om te krijgen wat we nodig hebben - de afgeleide (helling) van de verliesfunctie met betrekking tot de gewichten. We kunnen nu de gewichten dienovereenkomstig aanpassen.
Laten we de backpropagation-functie toevoegen aan onze Python-code:
De werking van het neurale netwerk controleren
Nu we onze volledige Python-code hebben voor het uitvoeren van voorwaartse en achterwaartse propagatie, laten we eens kijken naar ons neurale netwerk als voorbeeld en kijken hoe het werkt.
 De perfecte set gewichten
De perfecte set gewichten Ons neurale netwerk moet de ideale set gewichten leren om deze functie weer te geven.
Laten we een neuraal netwerk trainen voor 1500 iteraties en kijken wat er gebeurt. Als we naar de onderstaande iteratieverliesgrafiek kijken, kunnen we duidelijk zien dat het verlies monotoon tot een minimum daalt. Dit komt overeen met het algoritme voor gradiëntafdaling waar we het eerder over hadden.
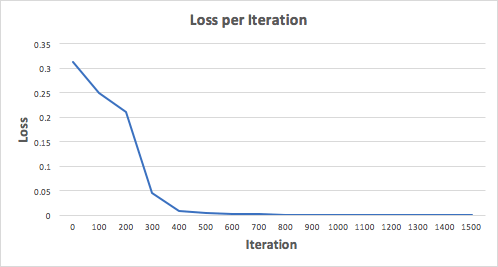
Laten we eens kijken naar de uiteindelijke voorspelling (output) van het neurale netwerk na 1500 iteraties.

We hebben het gedaan! Ons algoritme voor voorwaartse en achterwaartse propagatie liet zien dat het neurale netwerk succesvol werkte, en de voorspellingen convergeren naar echte waarden.
Merk op dat er een klein verschil is tussen voorspellingen en werkelijke waarden. Dit is wenselijk omdat het overfitting voorkomt en het neurale netwerk in staat stelt onzichtbare gegevens beter te generaliseren.
laatste reflecties
Ik heb veel geleerd tijdens het schrijven van mijn eigen neurale netwerk vanaf het begin. Hoewel deep learning-bibliotheken zoals TensorFlow en Keras het mogelijk maken om diepe netwerken te bouwen zonder de innerlijke werking van een neuraal netwerk volledig te begrijpen, vind ik het nuttig voor aspirant-gegevenswetenschappers om er een dieper inzicht in te krijgen.
Ik heb veel van mijn persoonlijke tijd in dit werk gestoken en ik hoop dat je het nuttig vindt!
De juiste formulering van de vraag zou moeten zijn: hoe train je je eigen neurale netwerk? U hoeft zelf geen netwerk te schrijven, u moet enkele kant-en-klare implementaties nemen, waarvan er veel zijn, eerdere auteurs gaven links. Maar op zichzelf is deze implementatie als een computer waarop geen programma's zijn gedownload. Om ervoor te zorgen dat het netwerk uw probleem oplost, moet het worden aangeleerd.
En hier komt het belangrijkste dat je hiervoor nodig hebt: DATA. Er zijn veel voorbeelden van taken die naar de input van een neuraal netwerk worden gestuurd, en de juiste antwoorden op deze taken. Het neurale netwerk zal hier vanzelf van leren om deze juiste antwoorden te geven.
En hier ontstaan een heleboel details en nuances die bekend en begrepen moeten worden, zodat dit alles een kans heeft om een acceptabel resultaat te geven. Het is onrealistisch om ze hier allemaal te behandelen, dus ik zal slechts enkele punten opsommen. Ten eerste de hoeveelheid data. Dit is een heel belangrijk punt. Grote bedrijven, waarvan de activiteiten gerelateerd zijn aan machine learning, hebben meestal speciale afdelingen en medewerkers die zich alleen bezighouden met het verzamelen en verwerken van gegevens voor het trainen van neurale netwerken. Vaak moeten er gegevens worden gekocht en al deze activiteit vertaalt zich in een aanzienlijke uitgave. Ten tweede de presentatie van de gegevens. Als elk object in uw probleem wordt vertegenwoordigd door een relatief klein aantal numerieke parameters, dan is er een kans dat ze in zo'n ruwe vorm rechtstreeks aan een neuraal netwerk kunnen worden gegeven, en een acceptabel resultaat kan worden verkregen aan de output. Maar als de objecten complex zijn (afbeeldingen, geluid, objecten met variabele afmetingen), dan zult u hoogstwaarschijnlijk tijd en moeite moeten steken om de kenmerken te isoleren die van belang zijn voor het probleem dat wordt opgelost. Dit alleen al kan erg lang duren en een veel grotere impact hebben op het eindresultaat dan zelfs het type en de architectuur van het neurale netwerk dat voor gebruik is gekozen.
Er zijn vaak gevallen waarin echte gegevens te ruw en onbruikbaar zijn zonder voorafgaande verwerking: ze bevatten hiaten, ruis, inconsistenties en fouten.
Gegevens moeten ook niet zomaar, maar vakkundig en doordacht worden verzameld. Anders kan het getrainde netwerk zich vreemd gedragen en zelfs een heel ander probleem oplossen dan de auteur bedoelde.
Je moet je ook voorstellen hoe je het leerproces correct organiseert, zodat het netwerk niet overtraind blijkt te zijn. De complexiteit van het netwerk moet worden gekozen op basis van de dimensie van de gegevens en hun hoeveelheid. Sommige gegevens moeten voor de test apart worden gehouden en niet tijdens de training worden gebruikt om de werkelijke kwaliteit van het werk te beoordelen. Soms moeten verschillende objecten uit de trainingsset verschillende gewichten krijgen. Tijdens de training is het soms handig om deze gewichten te variëren. Het is soms handig om te beginnen met trainen op een stukje data en de rest van de data toe te voegen terwijl je traint. Over het algemeen kan dit worden vergeleken met koken: elke huisvrouw heeft haar eigen methoden om zelfs dezelfde gerechten te koken.