В sql server’е базы данных хранятся в виде обычных файлов на диске. Как минимум на одну БД приходится таких файлов 2: *.mdf и *.ldf. В первом хранятся сами данные, таблицы, индексы и пр., а во втором находится т.н. transaction log, в котором находится информация необходимая для восстановления БД.
Как можно создать новую БД? Это можно сделать 2 способами:
используя sql server enterprise manager
с использованием языка sql и оператора create database
Первый вариант прост и нагляден. Второй — удобен при распространении Ваших замечательных продуктов, использующих ms sql server, поскольку позволяет создать БД без нажатия разных кнопок.
Использование sql server enterprise manager
Залогиньтесь на Ваш компьютер как administrator или как пользователь, входящий в локальную группу administrators
Запустите sql server enterprise manager.
Раскройте Вашу группу sql серверов. Затем раскройте Ваш sql сервер. (раскрыть — значит щелкнуть мышкой на "+" в дереве объектов enterprise manager).
Щелкните на Вашем сервере.
В меню tools выберите пункт wizards…. В появившемся окне раскройте пункт database, щелкните на create database wizard и нажмите ok.
На экране появится окно "волшебника" по созданию БД. Жмем "next"
На этом шаге "волшебник" поинтересуется у Вас именем БД, а также местом ее расположения на необъятных просторах Ваших дисков 🙂 Проще говоря нужно указать название БД (лучше не использовать русские буквы в имени БД), а также расположение файлов.mdf и.ldf
Я назвал ее гордым именем sqlstepbystep и в дальнейшем буду на нее так и ссылаться.
Теперь от Вас потребуется указать начальный размер БД и имя файла для хранения данных. укажите размер сколько Вам не жалко для экспериментов. imho, 5 МБ будет вполне достаточно. Имя файла тоже вполне произвольно. Например, я ввел sqlstep.
Этот шаг называется: "Определение роста БД", т.е. требуется определить как будет (и будет ли) изменяться размер БД по мере добавления данных. Даны две группы опций:
do not automatically grow the database files — запретить автоматический рост файлов БД
automatically grow the database file — автоматический рост файлов БД, выбрано по умолчанию. Пусть так и будет.
В случае автоматического роста файлов можно задать прирост БД в мегабайтах или в процентах (по умолчанию стоит 10%). Кроме того можно ограничить или неограничивать максимальный размер БД (по умолчанию — неограниченно). Выбор тех или иных значений зависит от назначения БД, интенсивности и характера ее использования, т.е. от Ваше конкретной задачи. Как правильно (с моей колокольни 🙂 выбрать эти параметры мы рассмотрим позднее, в шагах посвященных вопросам оптимизации.
С параметрами файла данных определились, теперь требуется определиться с параметрами лога. Они точно такие же. Обязательно введите имя файла лога отличное от имени файла БД, просто добавьте к нему log
Нажмете "next" и можно посмотреть на итоговый отчет. Если все в порядке нажмите "finish" БД и создастся. Об этом вы получите сообщение, а затем Вам будет предложено создать maintenance plan нам сейчас не нужен, поэтому откажитесь.
Использование sql оператора create database
Оператор create database может повторить все ваши действия, описанные выше. Собственно enterprise manager "перевел" ваши нажатия в этот оператор и передал его sql server’у. Почти все функции enterprise manager’а именно так и выполняются: у пользователя запрашиваются данные, формируется оператор замечательного языка sql (который мы рассмотрим позднее) и передается для выполнения sql server, а результаты выполнения показывают пользователю.
Рассмотрим поближе синтаксис оператора create database.
create database database_name (name = logical_file_name, filename = "os_file_name" [, size = size] [, maxsize = max_size] [, filegrowth = growth_increment]) } [,...n] ] ) } [,...n] ]
filename — полный путь и имя файла для размещения БД, должен указывать на локальный диск компьютера, на котором установлен sql server.
size — начальный размер каждого файла в Мб.
maxsize — максимальный размер файла в Мб, если не указана размер не ограничивается.
filegrowth — единица увеличения файла, указывается в Мб (по умолчанию) или в процентах (т.е. к числу добавляется %), значение 0 запрещает увеличение файла.
Теперь посмотрим как выглядит создание БД:
create database sqlstepbystep on primary (name=sqlstepdata, filename="c:mssql7datasqlstep_data.mdf", size=5, maxsize=10, filegrowth=10%) log on (name=sqlsteplog, filename="c:mssql7datasqlstep_log.ldf", size=1, maxsize=5, filegrowth=1)
Чтобы проверить эту команду, запустите query analyzer — очень полезная утилита, для выполнения sql запросов. Подключитесь к Вашему серверу и в окне ввода команд наберите этот оператор. Отправьте запрос на выполнение (клавишей f5 или ctrl-e или щелкните мышкой на кнопке с зеленой стрелкой). Все пошуршит и вскоре внизу, в окне сообщений, появится сообщение о том что БД создана успешно (или нет).
Все что мы создали можно и уничтожить. Удаление БД очень просто, как говорится "ломать не строить". sql оператор:
drop database <имя бд>
Набирается в query analyzer и запускается на выполнение. Фю-ю-и-ить, и БД уже нет.
В enterprise manager’e выберите БД щелкните правой кнопкой мыши и в контекстном меню выберите "delete" и все… пропало.
На следующем этапе мы рассмотрим создание таблиц, типы данных в transact-sql.
Каждый веб-разработчик должен знать SQL, чтобы писать запросы к базам данных. И, хотя, phpMyAdmin никто не отменял, зачастую необходимо испачкать руки, чтобы написать низкоуровневый SQL.
Именно поэтому мы подготовили краткий экскурс по основам SQL. Начнем же!
1. Создание таблицы
Для создания таблиц предназначена инструкция CREATE TABLE . В качестве аргументов должно быть задано название столбцов, а также их типы данных.
Создадим простую таблицу по имени month . Она состоит из 3 колонок:
- id – Номер месяца в календарном году (целое число).
- name – Название месяца (строка, максимум 10 символов).
- days – Количество дней в этом месяце (целое число).
Вот как будет выглядеть соответствующий SQL запрос:
CREATE TABLE months (id int, name varchar(10), days int);
Также при создании таблиц целесообразно добавить первичный ключ для одной из колонок. Это позволит держать записи уникальными и ускорит запросы на выборку. Пусть в нашем случае уникальным будет название месяца (столбец name )
CREATE TABLE months (id int, name varchar(10), days int, PRIMARY KEY (name));
| Тип данных | Описание |
|---|---|
| DATE | Значения даты |
| DATETIME | Значения даты и времени с точностью до минты |
| TIME | Значения времени |
2. Вставка строк
Теперь давайте заполнять нашу таблицу months полезной информацией. Добавление записей в таблицу производится через инструкцию INSERT . Есть два способа записи этой инструкции.
Первый способ не указать имена столбцов, куда будут вставлены данные, а указать только значения.
Этот способ записи прост, но небезопасен, поскольку нет гарантии, что по мере расширения проекта и редактировании таблицы, столбцы будут располагаться в том же порядке, что и ранее. Безопасный (и в тоже время более громоздкий) способ записи инструкции INSERT требует указания как значений, так и порядка следования столбцов:
Здесь первое значение в списке VALUES соответствует первому указанному имени столбца и т.д.
3. Извлечение данных из таблиц
Инструкция SELECT - наш лучший друг, когда мы хотим получить данные из базы данных. Она используется очень часто, так что отнеситесь к этому разделу очень внимательно.
Самый простое использование инструкции SELECT - запрос, который возвращает все столбцы и строки из таблицы (например, таблицы по имени characters ):
SELECT * FROM "characters"
Символ звездочка (*) означает, что мы хотим получить данные из всех столбцов. Так базы данных SQL обычно состоят из более чем одной таблицы, то требуется обязательно указывать ключевое слово FROM , следом за которым через пробел должно следовать название таблицы.
Иногда мы не хотим получить данные не из всех столбцов в таблице. Для этого, вместо звездочки (*) мы должны через запятую записать имена желаемых столбцов.
SELECT id, name FROM month
Кроме того, во многих случаях мы хотим, чтобы полученные результаты были отсортированы в определенном порядке. В SQL мы делаем это с помощью ORDER BY . Он может принимать опциональный модификатор – ASC (по-умолчанию) сортирующий по возрастанию или DESC , сортирующий по убыванию:
SELECT id, name FROM month ORDER BY name DESC
При использовании ORDER BY убедитесь, что оно будет последним в инструкции SELECT . В противном случае будет выдано сообщение об ошибке.
4. Фильтрация данных
Вы узнали, как выбрать из базы данных с помощью SQL запроса строго определенные столбцы, но что если нам нужно получить еще и определенные строки? На помощь здесь приходит условие WHERE , позволяющее нам фильтровать данные в зависимости от условия.
В этом запросе мы выбираем только те месяцы из таблицы month , в которых больше 30 дней с помощью оператора больше (>).
SELECT id, name FROM month WHERE days > 30
5. Расширенная фильтрация данных. Операторы AND и OR
Ранее мы использовали фильтрацию данных с использованием одного критерия. Для более сложной фильтрации данных можно использовать операторы AND и OR и операторов сравнения (=,<,>,<=,>=,<>).
Здесь мы имеем таблицу, содержащую четыре самых продаваемых альбомов всех времен. Давайте выберем те из них, которые классифицируются как рок и у которых менее 50 миллионов проданных копий. Это можно легко сделать путем размещения оператора AND между этими двумя условиями.
 SELECT *
FROM albums
WHERE genre = "рок" AND sales_in_millions <= 50
ORDER BY released
SELECT *
FROM albums
WHERE genre = "рок" AND sales_in_millions <= 50
ORDER BY released
6. In/Between/Like
WHERE также поддерживает несколько специальных команд, позволяя быстро проверять наиболее часто используемые запросы. Вот они:
- IN – служит для указания диапазона условий, любое из которых может быть выполнено
- BETWEEN – проверяет, находится ли значение в указанном диапазоне
- LIKE – ищет по определенным паттернам
Например, если мы хотим выбрать альбомы с поп и соул музыкой, мы можем использовать IN("value1","value2") .
SELECT * FROM albums WHERE genre IN ("pop","soul");
Если мы хотим получить все альбомы, изданные между 1975 и 1985годами, мы должны записать:
SELECT * FROM albums WHERE released BETWEEN 1975 AND 1985;
7. Функции
SQL напичкан с функциями, которые делают разные полезные вещи. Вот некоторые из наиболее часто используемых:
- COUNT() – возвращает количество строк
- SUM() – возвращает общую сумму числового столбца
- AVG() – возвращает среднее значение из множества значений
- MIN() / MAX() – получает минимальное / максимальное значение из столбца
Чтобы получить самый последний год в нашей таблице мы должны записать такой SQL запрос:
SELECT MAX(released) FROM albums;
8. Подзапросы
В предыдущем пункте мы научились делать простые расчеты с данными. Если мы хотим использовать результат от этих расчетов, нам не обойтись без вложенных запросов. Допустим, мы хотим вывести artist , album и release year для старейшего альбома в таблице.
Мы знаем, как получить эти конкретные столбцы:
SELECT artist, album, released FROM albums;
Мы также знаем, как получить самый ранний год:
SELECT MIN(released) FROM album;
Все, что нужно сейчас, - это объединить два запроса с помощью WHERE:
SELECT artist,album,released FROM albums WHERE released = (SELECT MIN(released) FROM albums);
9. Объединение таблиц
В более сложных базах данных существует несколько таблиц, связанных друг с другом. Например, ниже представлены две таблицы о видеоиграх (video_games ) и разработчиков видеоигр (game_developers ).


В таблице video_games есть колонка разработчик (developer_id ), но в ней содержится целое число, а не имя разработчика. Это число представляет собой идентификатор (id ) соответствующего разработчика из таблицы разработчиков игр (game_developers ), связывая логически два списка, что позволяет нам использовать информацию, хранящуюся в них обоих одновременно.
Если мы хотим создать запрос, который возвращает все, что нужно знать об играх, мы можем использовать INNER JOIN для связи колонок из обеих таблиц.
SELECT video_games.name, video_games.genre, game_developers.name, game_developers.country FROM video_games INNER JOIN game_developers ON video_games.developer_id = game_developers.id;
Это самый простой и наиболее распространенный тип JOIN . Есть несколько других вариантов, но они применимы к менее частым случаям.
10. Алиасы
Если вы посмотрите на предыдущий пример, то вы заметите, что существуют две колонки называемые name . Это сбивает с толку, так что давайте установим псевдоним одного из повторяющихся столбцов, например, name из таблицы game_developers будет называться developer .
Мы также можем сократить запрос задав псевдонимы имен таблиц: video_games назовем games , game_developers - devs :
SELECT games.name, games.genre, devs.name AS developer, devs.country FROM video_games AS games INNER JOIN game_developers AS devs ON games.developer_id = devs.id;
11. Обновление данных
Часто мы должны изменить данные в некоторых строках. В SQL это делается с помощью инструкции UPDATE . Инструкция UPDATE состоит из:
- Таблицы, в которой находится значение для замены;
- Имен столбцов и их новых значений;
- Выбранные с помощью WHERE строки, которые мы хотим обновить. Если этого не сделать, то изменятся все строки в таблице.
Ниже приведена таблица tv_series с сериалами с их рейтингом. Однако, в таблицу закралась маленькая ошибка: хотя сериал Игра престолов и описывается как комедия, он на самом деле ей не является. Давайте исправим это!
 Данные таблицы tv_series
UPDATE tv_series SET genre = "драма" WHERE id = 2;
Данные таблицы tv_series
UPDATE tv_series SET genre = "драма" WHERE id = 2;
12. Удаление данных
Удаление строки таблицы с помощью SQL - это очень простой процесс. Все, что вам нужно, - это выбрать таблицу и строку, которую нужно удалить. Давайте удалим из предыдущего примера последнюю строку в таблице tv_series . Делается это с помощью инструкции >DELETE
DELETE FROM tv_series WHERE id = 4
Будьте осторожными при написании инструкции DELETE и убедитесь, что условие WHERE присутствует, иначе все строки таблицы будут удалены!
13. Удаление таблицы
Если мы хотим, чтобы удалить все строки, но оставить саму таблицу, то воспользуйтесь командой TRUNCATE:
TRUNCATE TABLE table_name;
В случае, когда мы на самом деле хотим, чтобы удалить и данные, и саму таблицу, то нам пригодится команда DROP:
DROP TABLE table_name;
Будьте очень осторожны с этими командами. Их нельзя отменить!/p>
На этом мы завершаем наш учебник по SQL! Мы многое о чем не рассказали, но то, что вы уже знаете, должно быть достаточно, чтобы дать вам несколько практических навыков в вашей веб-карьере.
После установки необходимо добавить пользователя для работы с БД, и, соответственно, создать новую базу данных. Ниже будет рассказано как это сделать.
1. Добавление нового пользователя
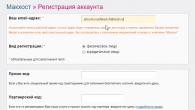
Запускаем программу «Среда SQL Server Management Studio » («Пуск » — «Microsoft SQL Server 2008 R2 » — «Среда SQL Server Management Studio ») .
В открывшемся окне выбираем:
- Тип сервера: «Компонент Database Engine » .
- Имя сервера в формате «<Имя компьютера>\<Идентификатор экземпляра>
» , где
<Имя компьютера> — имя физического компьютера на котором установлен SQL Server (в моем примере «S4 »).
<Идентификатор экземпляра> — задается только в случае подключения к именованному экземпляра SQL Server. - Проверка подлинности:«Проверка подлинности SQL Server » или «Проверка подлинности Windows »
- Имя входа: имя пользователя SQL Server.
- Пароль: в случае проверки подлинности SQL Server, пароль для выбранного пользователя.
После чего нажимаем «Соединить » .

Если все введено верно, в окне «Обозреватель объектов » мы увидим вкладку с именем нашего SQL-сервера. В нем раскрываем вкладку «Безопасность » — «Имена входа » и в контекстном меню выбираем «Создать имя входа » .

Откроется окно «Создание имени входа » . На вкладке «Общие » заполняем:
- Имя входа: наименование пользователя SQL.
- Проверку подлинности выбираем: SQL Server.
- Придумываем пароль для пользователя.
(При необходимости можно определить и остальные настройки безопасности). Затем переходим на вкладку «Роли сервера » .

На данной странице необходимо указать для данного пользователя. Например, если необходимо создать пользователя с административными правами, необходимо установить для него роль
- sysadmin
Если создается пользователь для подключения программ или , то достаточно указания ролей
- dbcreator
- processadmin
- public
назначается всем пользователям.
Указав все необходимые роли для создаваемого пользователя нажимаем «ОК » .

На этом процедура создания пользователя завершена.
2. Создание новой базы данных
Для добавления новой базы данных, в «Среде Microsoft SQL Server Management Studio » кликаем правой кнопкой мышки на вкладке «Базы данных » и выбираем «Создать базу данных » .

В открывшемся окне «Создание базы данных » на вкладке «Общие » заполняем:
- Задаем имя базы данных. Имя базы данных не должно начинаться с цифры или иметь пробелы в названии, иначе получим ошибку:
«неправильный синтаксис около конструкции %имя базы данных%» . - В качестве владельца выбираем созданного на предыдущем шаге пользователя.
Затем переходим на вкладку «Параметры » .

Здесь необходимо выбрать «Модель восстановления » базы данных и «Уровень совместимости » . Эти параметры зависят от того приложения, которое будет с создаваемой базой данных на SQL сервере. Например для необходимо задать
- Уровень совместимости: «SQL Server 2000 (80) » .
Очень внимательно стоит отнестись к параметру «Модель восстановления » создаваемой базы данных. Подробно про модели восстановления баз данных и о том, на что данный параметр влияет, я писал . Если сомневаетесь — выбирайте простую модель восстановления.
Определившись с параметрами нажимаем «ОК » .

После чего в списке мы должны увидеть только что созданную базу данных.

Помогла ли Вам данная статья?
Разновидность языка, применяемая в конкретной СУБД, называется диалектом SQL . Например, диалект СУБДOracleназываетсяPL / SQL ; вMSSQLServerиDB2 применяется диалектTransact - SQL ; вInterbaseиFirebird–isql . Каждый диалектSQLсовместим до определенной степени со стандартомSQL, но может иметь отличия и специфические расширения языка, поэтому для выяснения синтаксиса того или иногоSQL-оператора следует в первую очередь смотретьHelp конкретной СУБД.
Для операций над базами данных и таблицами в стандарте sql предусмотрены операторы:
Ниже приводится синтаксис этих операторов по стандарту SQL92. Поскольку их синтаксис в СУБД может отличаться от стандарта, при выполнении лабораторной работы рекомендуется обращаться к справочной системе СУБД.
Имена объектов базы данных (таблиц, столбцов и др.) могут состоять из буквенно-цифровых символов и символа подчеркивания. Специальные символы (@$# и т.п.) обычно указывают на особый тип таблицы (системная, временная и др.). Не рекомендуется использовать в именах национальные (русские) символы, пробелы и зарезервированные слова, но если они всё же используются, то такие имена следует писать в кавычках ".." или в квадратных скобках [..].
Далее при описании конструкций операторов SQLбудут использоваться следующие обозначения: в квадратных скобках записываются необязательные части конструкции; альтернативные конструкции разделяются вертикальной чертой | ; фигурные скобки {} выделяют логические блоки конструкции; многоточие… указывает на то, что предшествующая часть конструкции может многократно повторяться. «Раскрываемые» конструкции записываются в угловых скобках < >.
Создание базы данных
CREATE DATABASE Имя_базы_данных
Удаление одной и более баз данных
DROP DATABASE Имя_базы_данных [,Имя_базы_данных …]
Объявление текущей базы данных
USE Имя_базы_данных –- в SQL Server и MySQL
SET DATABASE Имя _ базы _ данных – в Firebird
Создание таблицы
CREATE TABLE Имя_таблицы (
<описание_столбца> [, <описание_столбца> |
<ограничение_целостности_таблицы> …]
< описание_столбца >
Имя_столбца ТИП
{NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
ТИП столбца может быть либо стандартным типом данных (см. таблицу 1), либо именем домена (см. п.6.2).
Некоторые СУБД позволяют создавать вычислимые столбцы (computed columns ). Это виртуальные столбцы, значение которых не хранится в физической памяти, а вычисляется сервером СУБД при всяком обращении к этому столбцу по формуле, заданной при объявлении этого столбца. В формулу могут входить значения других столбцов этой строки, константы, встроенные функции и глобальные переменные.
Описание вычислимого столбца в SQL Server имеет вид:
<описание_столбца> Имя_столбца AS выражение
Описание вычислимого столбца в Firebird имеет вид:
<описание_столбца> Имя_столбца COMPUTED BY <выражение>
СУБД MySQL 3.23 вычислимые столбцы не поддерживает.
< >
CONSTRAINT Имя_ограничения_целостности
{UNIQUE|PRIMARY KEY}(список_столбцов_образующих_ключ )
|FOREIGN KEY (список _ столбцов _FK )
REFERENCES Имя_таблицы (список_столбцов_ PK )
{NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
{NO ACTION|CASCADE|SET DEFAULT|SET NULL}]
|CHECK (условие_проверки )
Некоторые СУБД допускают объявление врéменных таблиц (существующих только во время сеанса). В SQL Server имена временных таблиц должны начинаться с символа # (локальные временные таблицы, видимые только создавшему их пользователю) или ## (глобальные таблицы, видимые всем пользователям); в MySQL для создания временных таблиц используется ключевое слово TEMPORARY, например:
CREATE TEMPORARY TABLE … (далее синтаксис см. CREATE TABLE).
Изменение структуры таблицы
Используется для изменения типа столбцов существующих таблиц, добавления и удаления столбцов и ограничений целостности.
ALTER TABLE Имя_таблицы
Изменение типа столбца (в SQLServerиFirebird)
ALTER COLUMN Имя_столбца новый_ТИП
Изменение типа, имени и ограничений столбца (в MySQL)
CHANGE COLUMN Имя_столбца <описание_столбца>
Добавление обычного или вычислимого столбца
|ADD <описание_столбца >
Добавление ограничения целостности
| ADD
<ограничение_целостности_таблицы >
Удаление столбца
|DROP COLUMN Имя_столбца
Удаление ограничения целостности
|DROP CONSTRAINT Имя_ограничения_целостности
Включение или отключение проверки ограничений целостности
ВMSSQLServer
|{CHECK|NO CHECK} CONSTRAINT
{Список_имен_ограничений_целостности |ALL}
Удаление таблицы
DROP TABLE Имя_таблицы
Далее рассмотрим, как при создании новых таблиц командой CREATETABLEили изменении структуры существующих таблиц командойALTERTABLEобъявить декларативные ограничения целостности (подробнее они описаны в п.4.2) .
1. Обязательное наличие данных (NULL–значения)
Объявляется словом NULL(столбец может иметь пустые ячейки) илиNOT NULL(столбец обязательный). По умолчанию принимаетсяNULL.
Пример создания таблицы 7:
CREATE TABLE Clients(
ClientName NVARCHAR (60) NOT NULL ,
DateOfBirth DATE NULL ,
Phone CHAR (12)); -- по умолчанию тоже NULL
2. Значение по умолчанию (DEFAULT)
Значение по умолчанию можно задать для каждого столбца таблицы. Если при модификации ячейки ее новое значение не указано, сервер вставляет значение по умолчанию. Значение по умолчанию может быть NULL, константой, вычислимым выражением или системной функцией.
Рассмотрим пример создания таблицы Orders (Заказы). Столбец OrderDate принимает по умолчанию значение текущей даты, а столбец Quantity (количество) по умолчанию равен 0.
CREATE TABLE Orders(
OrderNum INT NOT NULL , -- номер заказа
OrderDate DATETIME NOT NULL -- дата заказа
DEFAULT GetDate(),
Функция GetDate() возвращает текущую дату 8
Quantity SMALLINT NOT NULL -- кол-во товара, DEFAULT 0);
3. Объявление первичных ключей (PRIMARYKEY)
Простой первичный ключ объявляется словами PRIMARYKEYпри создании таблицы. Например,
CREATE TABLE Staff(-- таблица "Работники"
TabNum INT PRIMARY KEY , -- первичный ключ
WName NVARCHAR (40) NOT NULL , -- ФИО
... -- описание прочих столбцов );
Составной первичный ключ объявляется иначе:
-- способ 1 (объявление PK при создании таблицы)
CREATE TABLE Clients(
PasSeria NUMERIC (4,0)NOT NULL ,-- серия паспорта
PasNumber NUMERIC (6,0)NOT NULL ,-- номер паспорта
Name NVARCHAR (40)NOT NULL ,
Phone CHAR (12),
-- объявление составного первичного ключа
CONSTRAINT Clients_PK
PRIMARY KEY (PasSeria,PasNumber));
-- способ 2(PK объявляется после создания таблицы)
-- сначала создаем таблицу без PK
CREATE TABLE Clients(
PasSeria NUMERIC (4,0)NOT NULL ,--серия паспорта
PasNumber NUMERIC (6,0)NOT NULL ,--номер паспорта
ClientName NVARCHAR (40)NOT NULL ,
Phone CHAR (12));
-- модификация таблицы – добавляем РК
ALTER TABLE Clients
ADD CONSTRAINT Clients_PK
PRIMARY KEY (PasSeria,PasNumber);
4. Уникальность столбцов (UNIQUE)
Подобно Primary Key указывает, что столбец или группа столбцов не могут содержать повторяющихся значений, но не являютсяPK . Все столбцы, объявленныеUNIQUE, должны бытьNOTNULL. Пример объявления простого уникального столбца:
CREATE TABLE Students(
SCode INT PRIMARY KEY , -- суррогатный РК
FIO NVARCHAR (40) NOT NULL , -- ФИО
RecordBook CHAR (6) NOT NULL UNIQUE ); -- № зачетки
Пример объявления составного уникального поля:
CREATE TABLE Staff(-- таблица " Работники "
TabNum INT PRIMARY KEY , -- табельный номер
WName NVARCHAR (40) NOT NULL , -- ФИО
PasSeria NUMERIC (4,0) NOT NULL , -- серия паспорта
PasNumber NUMERIC (6,0) NOT NULL , -- номер паспорта
-- объявление составного уникального поля
CONSTRAINT Staff_UNQ UNIQUE (PasSeria,PasNumber));
5. Ограничения на значения столбца (CHECK)
Это ограничение позволяет указать диапазон, список или «маску» логически допустимых значений столбца.
Пример создания таблицы Workers (Работники) :
CREATE TABLE Workers(
-- табельные номера 4-значные
TabNum INT PRIMARY KEY
CHECK (TabNum BETWEEN 1000 AND 9999),
Name VARCHAR (60) NOT NULL , -- ФИО сотрудника
-- пол – буква " м " или " ж "
Gentry CHAR (1) NOT NULL
CHECK (Gentry IN ("м","ж")),
Возраст не менее 14 лет
Age SMALLINT NOT NULL CHECK (Age>=14),
--№ свидет-ва пенсионного страхования (по маске)
PensionCert CHAR (14)
CHECK (PensionSert LIKE ""));
В этом примере показаны разные типы проверок. Диапазон допустимых значений указывается конструкцией BETWEEN…AND; обычные условия (как для столбцаAge ) используют знаки сравнений =, <>, >, >=, <, <=, связанные при необходимости логическими операциямиAND,OR,NOT(например,Age >=14ANDAge <=70); для указания списка допустимых значений используется предикатINи его отрицаниеNOTIN; конструкция
LIKEмаска_допустимых_значений EXCEPTсписок_исключений
используется для задания маски допустимых значений строковых столбцов. В маске применяются два спецсимвола: «%» – произвольная подстрока, и «_» – любой единичный символ. Конструкция EXCEPTявляется необязательной.
В условии отбора CHECKмогут сравниваться значения двух столбцов одной таблицы и столбцы разных таблиц.
Каждый из нас регулярно сталкивается и пользуется различными базами данных. Когда мы выбираем адрес электронной почты, мы работаем с базой данных. Базы данных используют поисковые сервисы, банки для хранения данных о клиентах и т.д.
Но, несмотря на постоянное использование баз данных, даже для многих разработчиков программных систем остается много «белых пятен» из-за разного толкования одних и тех же терминов. Мы дадим краткое определение основных терминов баз данных перед рассмотрением языка SQL. Итак.
База данных - файл или набор файлов для хранения упорядоченных структур данных и их взаимосвязей. Очень часто базой данных называют систему управления - это только хранилище информации в определенном формате и может работать с различными СУБД.
Таблица - представим себе папку, в которой хранятся документы, сгруппированные по определенному признаку, например список заказов за последний месяц. Это и есть таблица в компьютерной Отдельная таблица имеет свое уникальное имя.
Тип данных - вид информации, разрешенной для хранения в отдельном столбце или строке. Это могут быть числа или текст определенного формата.
Столбец и строка - все мы работали с электронными таблицами, в которых также присутствуют строки и столбцы. Любая реляционная база данных работает с таблицами аналогичным образом. Строки иногда называют записями.
Первичный ключ - каждая строка таблицы может иметь один или несколько столбцов для ее уникальной идентификации. Без первичного ключа очень трудно производить обновление, изменение и удаление нужных строк.
Что такое SQL?
SQL (англ. - язык структурированных запросов) был разработан только для работы с базами данных и в настоящий момент является стандартом для всех популярных СУБД. Синтаксис языка состоит из небольшого количества операторов и прост в изучении. Но, несмотря на внешнюю простоту, он позволяет создание sql запросов для сложных операций с БД любого размера.
С 1992 г. существует общепринятый стандарт, называемый ANSI SQL. Он определяет базовый синтаксис и функции операторов и поддерживается всеми лидерами рынка СУБД, такими как ORACLE Рассмотреть все возможности языка в одной небольшой статье невозможно, поэтому мы кратко рассмотрим только основные SQL запросы. Примеры наглядно показывают простоту и возможности языка:
- создание баз и таблиц;
- выборка данных;
- добавление записей;
- модификация и удаление информации.
Типы данных SQL
Все столбцы в таблице базы данных хранят один тип данных. Типы данных в SQL такие же, как и в других языках программирования.
Создаем таблицы и базы данных

Создавать новые базы, таблицы и другие запросы в SQL можно двумя способами:
- Операторами SQL через консоль СУБД
- Используя интерактивные средства администрирования, входящие в состав сервера баз данных.
Создается новая база данных оператором CREATE DATABASE <наименование базы данных>; . Как видим, синтаксис прост и лаконичен.
Таблицы внутри базы данных создаем оператором CREATE TABLE со следующими параметрами:
- наименование таблицы
- имена и типы данных столбцов
В качестве примера создадим таблицу Commodity со следующими столбцами:
Создаем таблицу:
CREATE TABLE Commodity
(commodity_id CHAR(15) NOT NULL,
vendor_id CHAR(15) NOT NULL,
commodity_name CHAR(254) NULL,
commodity_price DECIMAL(8,2) NULL,
commodity_desc VARCHAR(1000) NULL);
Таблица состоит из пяти столбцов. После наименования идет тип данных, столбцы разделяются запятыми. Значение столбца может принимать пустые значения (NULL) или должно быть обязательно заполнено (NOT NULL), и это определяется при создании таблицы.
Выборка данных из таблицы

Оператор выборки данных - самые часто используемые SQL запросы. Для получения информации необходимо указать, что мы хотим выбрать из такой таблицы. Вначале простой пример:
SELECT commodity_name FROM Commodity
После оператора SELECT указываем имя столбца для получения информации, а FROM определяет таблицу.
Результатом выполнения запроса будут все строки таблицы со значениями Commodity_name в том порядке, в котором они были внесены в базу данных т.е. без всякой сортировки. Для упорядочивания результата используется дополнительный оператор ORDER BY.
Для запроса по нескольким полям перечисляем их через запятую, как в следующем примере:
SELECT commodity_id, commodity_name, commodity_price FROM Commodity
Есть возможность получить как результат запроса значение всех столбцов строки. Для этого используется знак «*»:
SELECT * FROM Commodity
- Дополнительно SELECT поддерживает:
- Сортировку данных (оператор ORDER BY)
- Выбор согласно условиям (WHERE)
- Группировку срок (GROUP BY)
Добавляем строку

Для добавления строки в таблицу используются SQL запросы с оператором INSERT. Добавление может производиться тремя способами:
- добавляем новую целую строку;
- часть строки;
- результаты запроса.
Для добавления полной строки необходимо указать имя таблицы и значения столбцов (полей) новой строки. Приведем пример:
INSERT INTO Commodity VALUES("106 ", "50", "Coca-Cola", "1.68", "No Alcogol ,)
Пример добавляет в таблицу новый товар. Значения указываются после VALUES для каждого столбца. Если нет соответствующего значения для столбца, то необходимо указывать NULL. Столбцы заполняются значениями в порядке, указанном при создании таблицы.
В случае добавления только части строки необходимо явно указать наименования столбцов, как в примере:
INSERT INTO Commodity (commodity_id, vendor_id, commodity_name)
VALUES("106 ", ‘50", "Coca-Cola",)
Мы ввели только идентификаторы товара, поставщика и его наименование, а остальные поля отставили пустыми.
Добавление результатов запроса
В основном INSERT используется для добавления строк, но может использоваться и для добавления результатов оператора SELECT.
Изменение данных

Для изменения информации в полях таблицы базы данных необходимо использовать оператор UPDATE. Оператор может применяться двумя способами:
- Обновляются все строки в таблице.
- Только для определенной строки.
UPDATE состоит из трех основных элементов:
- таблица, в которой необходимо производить изменения;
- имена полей и их новые значения;
- условия выбора строк для изменения.
Рассмотрим пример. Допустим, у товара с ID=106 изменилась стоимость, поэтому эту строку необходимо обновить. Пишем следующий оператор:
UPDATE Commodity SET commodity_price = "3.2" WHERE commodity_id = "106"
Мы указали имя таблицы, в нашем случае Commodity, где будет производиться обновление, затем после SET - новое значение столбца и нашли нужную запись, указав в WHERE нужное значение ID.
Для изменения нескольких столбцов после оператора SET указываются несколько пар столбец-значение, разделенных запятыми. Смотрим пример, в котором обновляется наименование и цена товара:
UPDATE Commodity SET commodity_name=’Fanta’, commodity_price = "3.2" WHERE commodity_id = "106"
Для удаления информации в столбце можно присвоить ему значение NULL, если это позволяет структура таблицы. Необходимо помнить, что NULL - это именно «никакое» значение, а не нуль в виде текста или числа. Удалим описание товара:
UPDATE Commodity SET commodity_desc = NULL WHERE commodity_id = "106"
Удаление строк

SQL запросы на удаление строк в таблице выполняются оператором DELETE. Есть два варианта использования:
- в таблице удаляются определенные строки;
- удаляются все строки в таблице.
Пример удаления одной строки из таблицы:
DELETE FROM Commodity WHERE commodity_id = "106"
После DELETE FROM указываем имя таблицы, в которой будут удаляться строки. Оператор WHERE содержит условие, по которому будут выбираться строки для удаления. В примере мы удаляем строку товара с ID=106. Указывать WHERE очень важно т.к. пропуск этого оператора приведт к удалению всех строк в таблице. Это относится и к изменению значения полей.
В операторе DELETE не указываются наименования столбцов и метасимволы. Он полностью удаляет строки, а удалить отдельный столбец он не может.
Использование SQL в Microsoft Access

Обычно используется в интерактивном режиме для создания таблиц, баз данных, для управления, изменения, анализа данных в базе данных и с целью внедрить запросы SQL Access через удобный интерактивный конструктор запросов (Query Designer), используя который можно построить и немедленно выполнить операторов SQL любой сложности.
Также поддерживается режим доступа к серверу, при котором СУБД Access может использоваться как генератор SQL-запросов к любому ODBC источнику данных. Эта возможность позволяет приложениям Access взаимодействовать с любого формата.
Расширения SQL
Поскольку SQL запросы не имеют всех возможностей процедурных языков программирования, таких как циклы, ветвления и т.д., производители СУБД разрабатывают свой вариант SQL с расширенными возможностями. В первую очередь это поддержка хранимых процедур и стандартных операторов процедурных языков.
Наиболее распространенные диалекты языка:
- Oracle Database - PL/SQL
- Interbase, Firebird - PSQL
- Microsoft SQL Server - Transact-SQL
- PostgreSQL - PL/pgSQL.
SQL в Интернет
СУБД MySQL распространяется под свободной лицензией GNU General Public License. Имеется коммерческая лицензия с возможностью разработки заказных модулей. Как составная часть входит в наиболее популярные сборки Интернет-серверов, таких как XAMPP, WAMP и LAMP, и является самой популярной СУБД для разработки приложений в сети Интернет.
Была разработана компанией Sun Microsystems и в настоящий момент поддерживается корпорацией Oracle. Поддерживаются базы данных размером до 64 терабайт, стандарт синтаксиса SQL:2003, репликация баз данных и облачных сервисов.