Иногда в повседневной компьютерной деятельности возникает задача найти дубликаты файлов. Причин для этого может быть множество: нехватка места на жестком диске, попытки уменьшить энтропию в своих файлах, разобраться со сброшенными в разное время фотографиями с фотоаппарата и множество других нужных случаев.
В сети можно найти большое количество программ, которые позволяют искать дубликаты файлов. Но зачем искать какие-то программы, если шикарный инструмент для такой работы обычно всегда под рукой. И называется этот инструмент Total Commander (TC ).
В этой статье я покажу все методы на основе Total Commander версии 8.5 , в этой версии поиск дубликатов файлов стал очень богат функционально.
!!!Маленькое важное отступление. Что нужно понимать под словом дубликат файла? Два файла ИДЕНТИЧНЫ только тогда, когда они полностью совпадают побитно. Т.е. любая информация в компьютере представлена последовательностью нулей и единиц. Так вот, файлы совпадают только тогда, когда у них полностью совпадает последовательность нулей и единиц, из которых эти файлы состоят. Все разговоры о том, что можно сравнить два файла по какому-либо другому признаку, глубоко ошибочны.
В TC есть два, различающихся по своей сути, метода поиска дублирующихся файлов:
- Синхронизировать каталоги;
- Поиск дубликатов;
Их особенность и применение лучше всего показать на примерах.
1.Синхронизация каталогов.
Данный метод применяется тогда, когда у вас две сравниваемые папки имеют идентичную структуру. Это обычно бывает во многих случаях, вот несколько из них:
- Вы регулярно делали архив своей рабочей папки. Через какое-то время вам понадобилось выяснить, какие файлы были добавлены или изменены с момента создания архива. Вы распаковываете весь архив в отдельную папку. Структура папок в нем практически совпадает с рабочей. Вы проводите сравнение двух папок «исходной» и «восстановленной из архива» и легко получаете список всех измененных, добавленных или удаленных файлов. Пара несложных манипуляций — и вы удаляете из восстановленной папки все дубликаты файлов, которые есть в рабочей.
- Вы работаете в папке на сетевом диске и регулярно делаете копию к себе на локальный диск. Со временем ваша рабочая папка стала довольно большой и время, затрачиваемое на полное копирование, стало очень большим. Чтобы не копировать каждый раз всю папку, можно сначала провести сравнение с резервной и скопировать только те файлы, которые были изменены или добавлены, а также удалить в резервной папке файлы, которые были удалены из основной.
Когда вы войдете во вкус, почувствуете всю предоставленную мощь этого метода, вы сами сможете придумать тысячи ситуаций, когда метод синхронизации каталогов окажет вам огромную помощь в работе.
Итак, как же все происходит на практике. Приступаем.
Предположим у нас есть основная папка «Рабочая» , в которой лежат файлы, с которыми происходит работа. И есть папка «Архив» , в которой лежит старая копия папки «Рабочая» . Наша задача найти в обеих папках дублирующиеся файлы и удалить их из папки «Архив» .
Открываем TC. В правой и левой панелях открываем сравниваемые папки:
Нажимаем меню «Команды»-«Синхронизировать каталоги…»
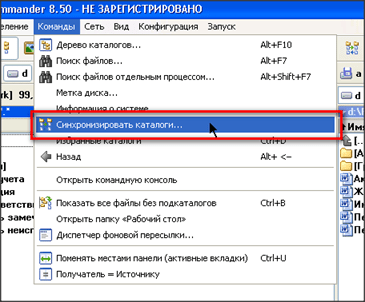
Открывается окно сравнения каталогов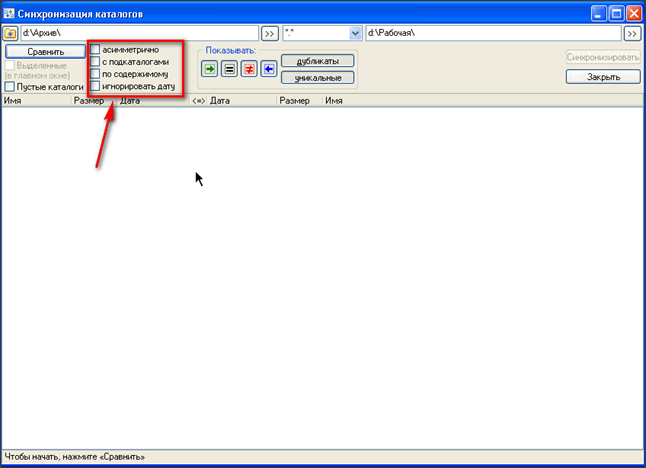
Далее нам необходимо установить параметры сравнения. Ставим галочки в параметры «с подкаталогами», «по содержимому», «игнорировать дату»

- «с подкаталогами» — будут сравниваться файлы во всех подкаталогах, указанных папок;
- «по содержимому» — вот ключевая опция, которая заставляет TC сравнивать файлы ПОБИТНО!!! В противном случае, файлы будут сравниваться по имени, размеру, дате;
- «игнорировать дату» — эта опция заставляет TC показывать различающиеся файлы, без попытки автоматического определения направления будущего копирования;
!!! Сравниваться будут файлы только с одинаковыми именами!!! Если файлы идентичны, но они имеют разное имя, то они не будут сравниваться!
Нажимаем кнопку «Сравнить».
В зависимости от объёма файлов, сравнение может идти очень долго, не пугайтесь. В конце концов сравнение закончится и в нижней строке состояния(на рисунке секция 1) отобразится результат: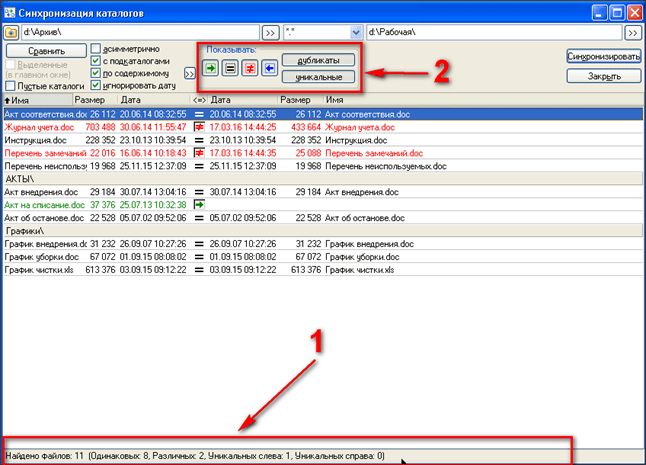
Если кнопки в секции «Показывать» (на рисунке секция 2) нажаты, то вы увидите результат сравнения для каждого файла.
— эта кнопка включает отображение файлов, которые есть в левой панели, но которых нету в правой;
— эта кнопка включает отображение идентичных файлов;
— эта кнопка включает отображение различающихся файлов;
— эта кнопка включает отображение файлов, которые есть в правой панели, но которых нету в левой;
Если у вас, изначально, все кнопки отображения выключены, то результат сравнения можно оценить только по строке состояния (на рисунке выше секция 1), в данном случае мы видим что сравнились 11 файлов, из которых 8 файлов являются одинаковыми, 2 файла различаются, и еще в левой панели имеется файл, которого нет в правой панели.
Для выполнения нашего задания необходимо оставить отображение только идентичных(одинаковых) файлов, поэтому все остальные кнопки отображения выключаем
Теперь у нас остались только идентичные файлы, и мы спокойно можем удалить их в папке «Архив»
. Для этого выделяем все файлы. Проще всего это сделать нажатием универсальной комбинации CTRL+A
. Или сначала выделить мышкой первую строчку, потом нажать на клавиатуре клавишу SHIFT
и не отпуская ее выделить мышкой последнюю строчку. В результате у вас должно получиться вот так: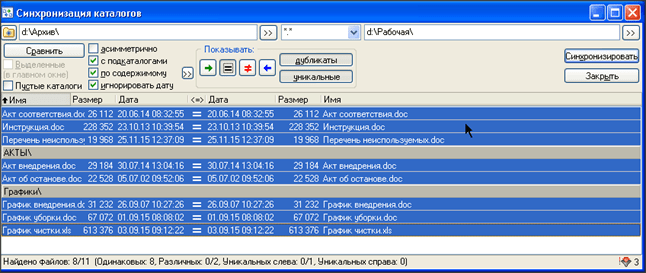
Заключительным шагом мы нажимаем правой клавишей мышки на любую строку и в открывшемся меню выбираем пункт «Удалить слева»

TC любезно переспрашивает нас о нашем желании,
и если мы нажимаем «ДА»
, то он удаляет все помеченные файлы в папке «Архив»
.
После этого, автоматически, происходит повторное сравнение двух папок. Если вам не нужно повторное сравнение, то процесс можно прервать, нажав на кнопку «Прервать»
или нажать клавишу ESC
на клавиатуре. Если повторное сравнение не было прервано, и мы включили все кнопки отображения, то мы увидим вот такое окно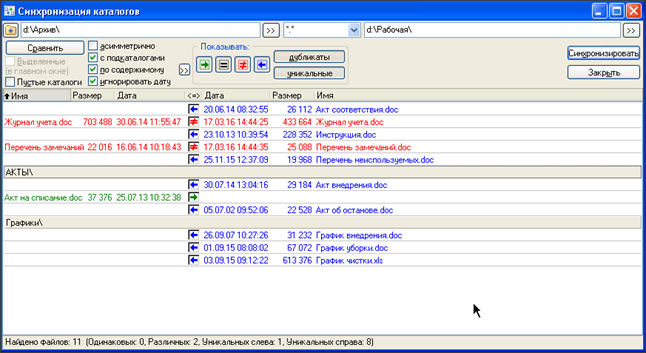
Все. Поставленная задача выполнена. Все одинаковые файлы найдены и удалены в папке «Архив» .
Обучающее видео по теме
2.Поиск дубликатов.
Коренное отличие данного метода от метода синхронизации каталогов заключается в том, что TC игнорирует имена сравниваемых файлов. Фактически, он сравнивает каждый файл с каждым, и показывает нам идентичные файлы как бы они не назывались ! Такой поиск очень удобен, когда вы не знаете ни структуры папок, ни имен сравниваемых файлов. В любом случае, после поиска дубликатов, вы получите точный список идентичных файлов.
Поиск дубликатов я покажу на одной практической задаче, поиске дубликатов личных фотографий. Довольно часто вы сбрасываете в компьютер фотографии со своих цифровых гаджетов. Частенько ситуация запутывается, что-то сбрасывается по многу раз, что-то пропускается. Как быстро удалить файлы, сброшенные несколько раз? Очень просто!
Приступаем.
Предположим, вы всегда сбрасываете все свои фотографии в папку «ФОТО»
на диске D. После всех сбросов папка имеет примерно такой вид:
Как видим, некоторые файлы находятся в папках, названных по дате съемки, некоторые сброшены в корень папки «_Новые»
и «_Новые1»

Чтобы начать поиск дубликатов открываем в любой панели TC папку, в которой будем искать. В нашем случае это папка «ФОТО»

Далее нажимаем на клавиатуре комбинацию клавиш ALT+F7
или в меню выбираем «Команды»-«Поиск файлов»

Открывается окно стандартного поиска TC. Строку «Искать файлы:»
оставляем пустой, тогда будут сравниваться все файлы.
Затем переходим на закладку «Дополнительно»
и выставляем галочки «Поиск дубликатов:», «по размеру», «по содержимому»
и нажимаем «Начать поиск»
.
Поиск может идти ОЧЕНЬ долго, не надо этого пугаться, так как происходит огромное количество сравнений большого объёма файлов. При этом в строке состояния показывается процент выполнения
Когда поиск закончится, откроется окно результатов поиска, в котором нажимаем кнопку «Файлы на панель»

В окне поиска и в окне панели идентичные файлы собраны в секции, отделенные пунктирными линиям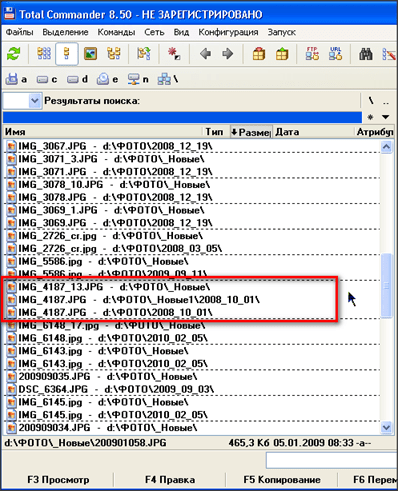
В каждой секции отображается имя файла и полный путь к файлу. Имена ИДЕНТИЧНЫХ файлов могут быть абсолютно различными!
В данном случае видно, что одна и таже фотография записана ТРИ раза, причем два раза под одним именем(IMG_4187.JPG
) а третий раз эта фотография записана под совершенно другим именем(IMG_4187_13.JPG
).
Далее остается выделить ненужные одинаковые файлы и удалить их. Это можно делать вручную, выделяя каждый файл нажатием клавиши Ins . Но это долго и не эффективно. Есть более правильные и быстрые способы.
Итак, наша задача состоит в том, чтобы удалить повторяющиеся файлы в папках «_Новые»
и «_Новые1»
.
Для этого нажимаем на дополнительной клавиатуре, справа большую клавишу [+]
. Обычно этой клавишей в TC выделяются файлы по маске. Эту же операцию можно сделать через меню «Выделение»-«Выделить группу»

Рассмотрим, к
ак найти и выделить одинаковые значения в Excel.
Нам поможет условное форматирование.
Что такое условное форматирование и как с ним работать, смотрите в статье "Условное форматирование в Excel" .
Выделить повторяющиеся значения в Excel можно как во всей таблицы, так и в определенном диапазоне (строке, столбце). А функция "
Фильтр в Excel " поможет их скрыть, если нужно. Рассмотрим несколько способов.
Первый способ
.
Как найти одинаковые значения в Excel
.
Например, число, фамилию, т.д. Как это сделать, смотрите в статье «Как выделить ячейки в Excel ».
Второй способ.
Как выделить повторяющиеся значения в Excel
. В этой таблице нам нужно выделить год рождения 1960.
Выделяем столбец «Год рождения».
На закладке «Главная» в разделе «Стили» нажимаем кнопку «Условное форматирование». Затем в разделе «Правила выделенных ячеек» выбираем «Повторяющиеся значения».
В появившемся диалоговом окне выбираем, что нам нужно выделить: повторяющиеся или уникальные значения. Выбираем цвет заливки ячейки или цвет шрифта.
Подробнее смотрите в статье «Выделить дату, день недели в Excel при условии» . Нажимаем «ОК». В столбце D выделились все года – 1960.
Нажимаем «ОК». В столбце D выделились все года – 1960.

Можно в условном форматировании тоже в разделе «Правила выделенных ячеек» выбрать функцию «Содержит текст». Написать этот текст (например, фамилию, цифру, др.), и все ячейки с этим текстом выделятся цветом. Мы написали фамилию «Иванов». Есть еще много способов найти одинаковые значения в Excel и выделить их не только цветом, но и словами, числами, знаками. Можно настроить таблицу так, что дубли будут не только выделяться, но и считаться. Можно выделить повторяющиеся значения с первого слова, а можно выделять дубли со второго и далее. Обо всем этом и другом читайте в статье "
Есть еще много способов найти одинаковые значения в Excel и выделить их не только цветом, но и словами, числами, знаками. Можно настроить таблицу так, что дубли будут не только выделяться, но и считаться. Можно выделить повторяющиеся значения с первого слова, а можно выделять дубли со второго и далее. Обо всем этом и другом читайте в статье "
Если Вы работаете с большими количеством информации в Excel и регулярно добавляете ее, например, данные про учеников школы или сотрудников компании, то в таких таблицах могут появиться повторяющиеся значения, другими словами – дубликаты.
В данной статье мы рассмотрим, как найти, выделить, удалить и посчитать количество повторяющихся значений в Эксель.
Как найти и выделить
Найти и выделить дубликаты в документе можно, используя условное форматирование в Эксель . Выделите весь диапазон данных в нужной таблице. На вкладке «Главная» кликните на кнопочку «Условное форматирование» , выберите из меню «Правила выделения ячеек» – «Повторяющиеся значения» .
В следующем окне выберите из выпадающего списка «повторяющиеся» , и цвет для ячейки и текста, в который нужно закрасить найденные дубликаты. Затем нажмите «ОК» и программа выполнит поиск дубликатов.

В примере Excel выделил розовым всю одинаковую информацию. Как видите, данные сравниваются не построчно, а выделяются одинаковые ячейки в столбцах. Поэтому выделена ячейка «Саша В.» . Таких учеников может быть несколько, но с разными фамилиями.

Как посчитать
Если Вам нужно найти и посчитать количество повторяющихся значений в Excel, создадим для этого сводную таблицу Excel. Добавляем в исходную столбец «Код» и заполняем его «1» : ставим 1, 1 в первых двух ячейка, выделяем их и протягиваем вниз. Когда будут найдены дубликаты для строк, каждый раз значение в столбце «Код» будет увеличиваться на единицу.
Выделяем все вместе с заголовками, переходим на вкладку «Вставка» и нажимаем кнопочку «Сводная таблица» .
Чтобы более подробно узнать, как работать со сводными таблицами в Эксель , прочтите статью перейдя по ссылке.

В следующем окне уже указаны ячейки диапазона, маркером отмечаем «На новый лист» и нажимаем «ОК» .

Справой стороны перетаскиваем первые три заголовка в область «Названия строк» , а поле «Код» перетаскиваем в область «Значения» .

В результате получим сводную таблицу без дубликатов, а в поле «Код» будут стоять числа, соответствующие повторяющимся значениям в исходной таблице – сколько раз в ней повторялась данная строка.
Для удобства, выделим все значения в столбце «Сумма по полю Код» , и отсортируем их в порядке убывания.

Думаю теперь, Вы сможете найти, выделить, удалить и даже посчитать количество дубликатов в Excel для всех строк таблицы или только для выделенных столбцов.
Оценить статью:Распространенный вопрос как найти и удалить дубликаты в Excel. Предположим вы выгрузили месячный отчет из вашей учетной системы, но в итоге вам нужно понять какие контрагенты вообще взаимодействовали с компанией за этот период — оставить список контрагентов без повтарений. Как отобрать уникальные значения?
Можно ли удалить задвоеные, затроенные и так далее значения в Excel по нескольким столбцам?
Можно, причем очень просто. Для этого есть специальная функция. Предварительно выберите диапазон, где нужно удалять дубликаты. На ленте заходим Данные — Удалить дубликаты (смотрите картинку в начале статьи).
Выбираем первый столбец
При этом важно понимать, что если вы выберите только первый столбец, то все данные в не выбранных столбцах удаляться в случае неуникальности.
Очень удобно!
2. Как выделить все дубликаты в Excel?
Уже слышали про ? Да, здесь оно еще как поможет! Выделяете столбец в котором надо пометить дубликаты, выбираете в меню Главное — Условное форматирование — Правила выделения ячеек — Повторяющиеся значения…
В открывшемся окне Повторяющиеся значения, выберите какие ячейки выделяем (уникальные или повторяющиеся), а так же формат выделения, либо из преложенных, либо создайте Пользовательский формат. Предустановлено форматом будет красная заливка и красный текст.

Нажимаете ОК, если не хотите изменять форматирование. Теперь все данные по выбранным условиям подкрасятся.
Отмечу, что инструмент применяется только для выбранного одного (!) столбца.
Кстати, если нужно увидеть уникальные, то в окне слева выберите — уникальные.
3. Уникальные значения при помощи сводных таблиц
Признаюсь честно, когда-то я не подозревал о существовании возможности «удалить дубликаты» и пользовался сводными таблицами. Как я это делал? Выделяете таблицу, в которых надо найти уникальные значения — Вставка —
Поиск дубликатов в Excel может оказаться не простой задачей, но если Вы вооружены некоторыми базовыми знаниями, то найдёте несколько способов справиться с ней. Когда я впервые задумался об этой проблеме, то достаточно быстро придумал пару способов как найти дубликаты, а немного поразмыслив, обнаружил ещё несколько способов. Итак, давайте для начала рассмотрим пару простых, а затем перейдём к более сложным способам.
Первый шаг – Вам необходимо привести данные к такому формату, который позволяет легко оперировать ими и изменять их. Создание заголовков в верхней строке и размещение всех данных под этими заголовками позволяет организовать данные в виде списка. Одним словом, данные превращаются в базу, которую можно сортировать и выполнять с ней различные манипуляции.
Поиск дубликатов при помощи встроенных фильтров Excel
Организовав данные в виде списка, Вы можете применять к ним различные фильтры. В зависимости от набора данных, который у Вас есть, Вы можете отфильтровать список по одному или нескольким столбцам. Поскольку я использую Office 2010, то мне достаточно выделить верхнюю строку, в которой находятся заголовки, затем перейти на вкладку Data (Данные) и нажать команду Filter (Фильтр). Возле каждого из заголовков появятся направленные вниз треугольные стрелки (иконки выпадающих меню), как на рисунке ниже.
Если нажать одну из этих стрелок, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с Вашим выбором. Это быстрый способ подвести итог или увидеть объём выбранных данных. Вы можете убрать галочку с пункта Select All (Выделить все), а затем выбрать один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные Вами пункты. Так гораздо проще найти дубликаты, если они есть.
После настройки фильтра Вы можете удалить дубликаты строк, подвести промежуточные итоги или дополнительно отфильтровать данные по другому столбцу. Вы можете редактировать данные в таблице так, как Вам нужно. На примере ниже у меня выбраны элементы XP и XP Pro .

В результате работы фильтра, Excel отображает только те строки, в которых содержатся выбранные мной элементы (т.е. людей на чьём компьютере установлены XP и XP Pro). Можно выбрать любую другую комбинацию данных, а если нужно, то даже настроить фильтры сразу в нескольких столбцах.

Расширенный фильтр для поиска дубликатов в Excel
На вкладке Data (Данные) справа от команды Filter (Фильтр) есть кнопка для настроек фильтра – Advanced (Дополнительно). Этим инструментом пользоваться чуть сложнее, и его нужно немного настроить, прежде чем использовать. Ваши данные должны быть организованы так, как было описано ранее, т.е. как база данных.
Перед тем как использовать расширенный фильтр, Вы должны настроить для него критерий. Посмотрите на рисунок ниже, на нем виден список с данными, а справа в столбце L указан критерий. Я записал заголовок столбца и критерий под одним заголовком. На рисунке представлена таблица футбольных матчей. Требуется, чтобы она показывала только домашние встречи. Именно поэтому я скопировал заголовок столбца, в котором хочу выполнить фильтрацию, а ниже поместил критерий (H), который необходимо использовать.

Теперь, когда критерий настроен, выделяем любую ячейку наших данных и нажимаем команду Advanced (Дополнительно). Excel выберет весь список с данными и откроет вот такое диалоговое окно:

Как видите, Excel выделил всю таблицу и ждёт, когда мы укажем диапазон с критерием. Выберите в диалоговом окне поле Criteria Range (Диапазон условий), затем выделите мышью ячейки L1 и L2 (либо те, в которых находится Ваш критерий) и нажмите ОК . Таблица отобразит только те строки, где в столбце Home / Visitor стоит значение H , а остальные скроет. Таким образом, мы нашли дубликаты данных (по одному столбцу), показав только домашние встречи:

Это достаточно простой путь для нахождения дубликатов, который может помочь сохранить время и получить необходимую информацию достаточно быстро. Нужно помнить, что критерий должен быть размещён в ячейке отдельно от списка данных, чтобы Вы могли найти его и использовать. Вы можете изменить фильтр, изменив критерий (у меня он находится в ячейке L2). Кроме этого, Вы можете отключить фильтр, нажав кнопку Clear (Очистить) на вкладке Data (Данные) в группе Sort & Filter (Сортировка и фильтр).
Встроенный инструмент для удаления дубликатов в Excel
В Excel есть встроенная функция Remove Duplicates (Удалить дубликаты). Вы можете выбрать столбец с данными и при помощи этой команды удалить все дубликаты, оставив только уникальные значения. Воспользоваться инструментом Remove Duplicates (Удалить дубликаты) можно при помощи одноименной кнопки, которую Вы найдёте на вкладке Data (Данные).

Не забудьте выбрать, в каком столбце необходимо оставить только уникальные значения. Если данные не содержат заголовков, то в диалоговом окне будут показаны Column A , Column B (столбец A, столбец B) и так далее, поэтому с заголовками работать гораздо удобнее.
Когда завершите с настройками, нажмите ОК . Excel покажет информационное окно с результатом работы функции (пример на рисунке ниже), в котором также нужно нажать ОК . Excel автоматически ликвидирует строки с дублирующимися значениями, оставив Вам только уникальные значения в столбцах, которые Вы выбрали. Кстати, этот инструмент присутствует в Excel 2007 и более новых версиях.

Поиск дубликатов при помощи команды Найти
Если Вам нужно найти в Excel небольшое количество дублирующихся значений, Вы можете сделать это при помощи поиска. Зайдите на вкладку Hom e (Главная) и кликните Find & Select (Найти и выделить). Откроется диалоговое окно, в котором можно ввести любое значение для поиска в Вашей таблице. Чтобы избежать опечаток, Вы можете скопировать значение прямо из списка данных.
В случае, когда объём информации очень велик и требуется ускорить работу поиска, выделите строку или столбец, в котором нужно искать, и только после этого запускайте поиск. Если этого не сделать, Excel будет искать по всем имеющимся данным и находить не нужные результаты.
Если нужно выполнить поиск по всем имеющимся данным, возможно, кнопка Find All (Найти все) окажется для Вас более полезной.

В заключение
Все три метода просты в использовании и помогут Вам с поиском дубликатов:
- Фильтр – идеально подходит, когда в данных присутствуют несколько категорий, которые, возможно, Вам понадобится разделить, просуммировать или удалить. Создание подразделов – самое лучшее применение для расширенного фильтра.
- Удаление дубликатов уменьшит объём данных до минимума. Я пользуюсь этим способом, когда мне нужно сделать список всех уникальных значений одного из столбцов, которые в дальнейшем использую для вертикального поиска с помощью функции ВПР .
- Я пользуюсь командой Find (Найти) только если нужно найти небольшое количество значений, а инструмент Find and Replace (Найти и заменить), когда нахожу ошибки и хочу разом исправить их.
Это далеко не исчерпывающий список методов поиска дубликатов в Excel. Способов много, и это лишь некоторые из них, которыми я пользуюсь регулярно в своей повседневной работе.