Регулярните изрази са много мощен инструмент за съпоставяне на шаблони, манипулиране и модифициране на низове и могат да се използват за различни задачи. Ето основните от тях:
- Проверка на въвеждане на текст;
- Търсене и замяна на текст във файл;
- Пакетно преименуване на файлове;
- Взаимодействие с услуги като Apache;
- Проверка на низ спрямо шаблон.
Това не е пълен списък, има много повече, които можете да направите с регулярните изрази. Но за новите потребители те може да изглеждат твърде сложни, тъй като за оформянето им се използва специален език. Но предвид възможностите, които предоставя, регулярните изрази на Linux трябва да бъдат познати и използвани от всеки системен администратор.
В тази статия ще ви преведем през регулярните изрази на bash за начинаещи, за да можете да разберете всички функции на този инструмент.
Има два типа знаци, които могат да се използват в регулярни изрази:
- обикновени писма;
- метазнаци.
Редовните знаци са буквите, цифрите и препинателните знаци, които съставят всеки низ. Всички текстове са съставени от букви и можете да ги използвате в регулярни изрази, за да намерите желаната позиция в текста.
Метасимволите са нещо друго, те дават сила на регулярните изрази. С метазнаците можете да направите много повече от търсенето на един символ. Можете да търсите комбинации от знаци, да използвате динамичен брой знаци и да избирате диапазони. Всички специални знаци могат да бъдат разделени на два типа, това са заместващи знаци, които заместват обикновените знаци, или оператори, които показват колко пъти даден знак може да се повтори. Синтаксисът на регулярния израз ще изглежда така:
редовен_символ специален символ_оператор
специален символ_замяна специален символ_оператор
- - буквалните специални знаци започват с обратна наклонена черта и се използва и ако трябва да използвате специален знак под формата на препинателен знак;
- ^ - обозначава началото на реда;
- $ - обозначава края на реда;
- * - показва, че предишният знак може да се повтори 0 или повече пъти;
- + - показва, че предишният знак трябва да се повтори повече от един или повече пъти;
- ? - предишният знак може да се появи нула или един път;
- (н)- показва колко пъти (n) да се повтори предишният знак;
- (N, n)- предишният знак може да се повтори от N до n пъти;
- . - всеки знак с изключение на превод на ред;
- - всеки знак, посочен в скоби;
- х | у- символ x или символ y;
- [^ az]- всеки знак, различен от посочените в скоби;
- - всеки знак от посочения диапазон;
- [^ a-z]- всеки знак, който не е в диапазона;
- б- обозначава граница на думата с интервал;
- Б- означава, че символът трябва да е вътре в дума, например ux съответства на uxb или tuxedo, но не съответства на Linux;
- д- означава, че символът е цифра;
- д- нецифров знак;
- н- символ за подаване на ред;
- с- един от символите интервал, интервал, табулация и т.н.;
- С- всеки знак с изключение на интервал;
- т- табличен характер;
- v- вертикален табулаторен знак;
- w- всеки азбучен знак, включително долна черта;
- У- всеки азбучен знак с изключение на долна черта;
- uXXX- Символ Unicdoe.
Важно е да се отбележи, че наклонената черта трябва да се използва преди специалните символи на литерала, за да се посочи, че специалният знак е следващият. Обратното също е вярно, ако искате да използвате специален знак, който се използва без наклонена черта като обикновен знак, тогава трябва да добавите наклонена черта.
Например, да предположим, че искате да намерите реда 1+ 2 = 3 в текста. Ако използвате този низ като регулярен израз, няма да намерите нищо, защото системата интерпретира плюс като специален символ, който казва, че предишната единица трябва да се повтори един или повече пъти. Така че трябва да се екранира: 1 + 2 = 3. Без екраниране, нашият редовен израз би съвпадал само с низа 11 = 3 или 111 = 3 и т.н. Не е необходимо да се поставя ред пред равен, тъй като това не е специален символ.
Примери за използване на регулярни изрази
След като покрихме основите и знаете как работи всичко, остава да консолидираме на практика придобитите знания за регулярните изрази на linux grep. Два много полезни специални символа са ^ и $, които обозначават началото и края на ред. Например, искаме да регистрираме всички потребители в нашата система, чието име започва с s. След това може да се приложи регулярният израз "^ S"... Можете да използвате команда egrep:
egrep "^ s" / etc / passwd
Ако искаме да избираме редове по последния знак в реда, можем да използваме $ за това. Например, нека изберем всички потребители на системата, без shell, записите за такива потребители завършват с false:
egrep "false $" / etc / passwd
За да отпечатате потребителски имена, които започват с s или d, използвайте израз като този:
egrep "^" / etc / passwd
Същият резултат може да се получи с помощта на знака "|". Първият вариант е по-подходящ за диапазони, а вторият се използва по-често за редовни или/или:
egrep "^" / etc / passwd
Сега нека изберем всички потребители, чието име е повече от три знака. Потребителското име завършва с двоеточие. Можем да кажем, че може да съдържа всеки азбучен знак, който трябва да се повтори три пъти преди двоеточие:
egrep "^ w (3):" / etc / passwd
заключения
В тази статия разгледахме регулярните изрази на Linux, но това бяха само основите. Ако се поразровите малко по-дълбоко, ще откриете, че има много по-интересни неща, които можете да правите с този инструмент. Времето, прекарано в изучаване на регулярни изрази, определено ще си заслужава.
В заключение, лекция от Yandex за регулярните изрази:
За да обработвате напълно текстове в bash скриптове, използвайки sed и awk, просто трябва да разберете регулярните изрази. Реализациите на този най-полезен инструмент могат да бъдат намерени буквално навсякъде и въпреки че всички регулярни изрази са подредени по подобен начин, базирани на едни и същи идеи, работата с тях има определени особености в различни среди. Тук ще говорим за регулярни изрази, които са подходящи за използване в скриптове на командния ред на Linux.
Този материал е предназначен да бъде въведение в регулярните изрази за тези, които може би изобщо не знаят какво представляват. Така че нека започнем от самото начало.
Какво представляват регулярните изрази
При мнозина, когато за първи път видят регулярни изрази, веднага възниква мисълта, че са пред безсмислена смесица от знаци. Но това, разбира се, далеч не е така. Разгледайте този регулярен израз например
Според нас дори абсолютен начинаещ веднага ще разбере как работи и защо ви е нужен :) Ако не разбирате съвсем, просто прочетете и всичко ще си дойде на мястото.
Регулярният израз е модел, който програми като sed или awk използват за филтриране на текст. Шаблоните използват обикновени ASCII знаци, които представляват себе си, и така наречените метасимволи, които играят специална роля, например, позволявайки ви да се позовавате на определени групи знаци.
Типове регулярни изрази
Реализациите на регулярни изрази в различни среди, като езици за програмиране като Java, Perl и Python, и инструменти на Linux като sed, awk и grep, имат определени странности. Тези функции зависят от така наречените машини за регулярни изрази, които интерпретират шаблони.Има два механизма за регулярни изрази в Linux:
- Машина, която поддържа стандарта POSIX Basic Regular Expression (BRE).
- Машина, която поддържа стандарта POSIX Extended Regular Expression (ERE).
Стандартът POSIX ERE често се прилага в езици за програмиране. Позволява ви да използвате много инструменти при проектирането на регулярни изрази. Например, това могат да бъдат специални поредици от знаци за често използвани модели, като например търсене в текста за отделни думи или набори от числа. Awk поддържа стандарта ERE.
Има много начини за разработване на регулярни изрази, в зависимост както от мнението на програмиста, така и от характеристиките на двигателя, за който са създадени. Не е лесно да се напишат общи регулярни изрази, които всеки двигател може да разбере. Затова ще се съсредоточим върху най-често използваните регулярни изрази и ще разгледаме как са имплементирани за sed и awk.
POSIX BRE регулярни изрази
Може би най-простият модел BRE е регулярен израз за намиране на точното появяване на поредица от знаци в текста. Ето как изглежда sed и awk търсенето на низ:$ echo "Това е тест" | sed -n "/ test / p" $ echo "Това е тест" | awk "/ test / (отпечатайте $ 0)"
Търсене на текст по шаблон в sed
Намиране на текст по шаблон в awk
Можете да забележите, че търсенето на даден шаблон се извършва без да се отчита точното местоположение на текста в низа. Освен това броят на събитията няма значение. След като регулярният израз намери посочения текст навсякъде в низа, низът се счита за валиден и се предава за по-нататъшна обработка.
Когато работите с регулярни изрази, имайте предвид, че те са чувствителни към главни букви:
$ echo "Това е тест" | awk "/ Тест / (отпечатване $ 0)" $ echo "Това е тест" | awk "/ тест / (отпечатайте $ 0)"
Регулярните изрази са чувствителни към главни букви
Първият регулярен израз не съвпада, тъй като думата "тест", започваща с главна буква, не се среща в текста. Вторият, конфигуриран да търси дума с главни букви, намери съвпадащ низ в потока.
В регулярните изрази можете да използвате не само букви, но и интервали и числа:
$ echo "Това отново е тест 2" | awk "/ тест 2 / (отпечатайте $ 0)"
Намерете част от текст, съдържаща интервали и числа
Пространствата се третират като редовни знаци от механизма за регулярни изрази.
Специални символи
Има няколко неща, които трябва да имате предвид, когато използвате различни знаци в регулярни изрази. И така, има някои специални знаци или метазнаци, които изискват специален подход за използване в шаблон. Ето ги и тях: .*^${}\+?|()
Ако един от тях е необходим в шаблона, той ще трябва да бъде екраниран с обратна наклонена черта (обратна наклонена черта) - \.
Например, ако трябва да намерите знак за долар в текста, той трябва да бъде включен в шаблона, предшестван от escape-символ. Да приемем, че имате файл, наречен myfile със следния текст:
В джоба ми има 10 $
Знакът на долара може да бъде открит с помощта на модел като този:
$ awk "/ \ $ / (отпечатайте $ 0)" myfile
Използване на специален символ в шаблон
В допълнение, обратната наклонена черта също е специален знак, така че ако искате да го използвате в шаблон, ще трябва също да го избягате. Изглежда като две наклонени черти напред:
$ echo "\ е специален знак" | awk "/ \\ / (отпечатайте $ 0)"
Обратна наклонена черта избяга
Въпреки че наклонената черта не е включена в горния списък със специални знаци, опитът да се използва в регулярен израз, написан за sed или awk, ще доведе до грешка:
$ echo "3/2" | awk "/// (отпечатайте $ 0)"
Неправилно използване на наклонена черта в шаблон
Ако имате нужда от него, трябва също да го прегледате:
$ echo "3/2" | awk "/ \ // (отпечатване $ 0)"
Наклонена черта напред
Котва символи
Има два специални знака за закотвяне на шаблон към началото или края на текстов низ. Символът на корицата - ^ ви позволява да опишете поредици от знаци, които се появяват в началото на текстовите редове. Ако моделът, който търсите, се появи на друго място в низа, регулярният израз няма да отговори на него. Използването на този символ изглежда така:$ echo "добре дошли в уебсайта на likegeeks" | awk "/ ^ likegeeks / (печат $ 0)" $ echo "сайт на likegeeks" | awk "/ ^ likegeeks / (отпечатайте $ 0)"
Намиране на шаблон в началото на ред
Символът ^ е предназначен за търсене на шаблон в началото на низ, като случайът също се взема предвид. Нека видим как това се отразява на обработката на текстов файл:
$ awk "/ ^ това / (отпечатайте $ 0)" myfile

Търсене на шаблон в началото на ред в текст от файл
Със sed, ако поставите капачка някъде вътре в шаблона, тя ще се третира като всеки друг редовен знак:
$ echo "Това ^ е тест" | sed -n "/ s ^ / p"
Не покривайте в началото на шаблона в sed
В awk, когато се използва същия модел, даденият символ трябва да бъде екраниран:
$ echo "Това ^ е тест" | awk "/ s \ ^ / (отпечатайте $ 0)"
Корица не в началото на шаблон в awk
Разбрахме търсенето на текстови фрагменти, разположени в началото на реда. Ами ако искате да намерите нещо в края на реда?
Знакът за долар - $, който е символът за котва за края на реда, ще ни помогне за това:
$ echo "Това е тест" | awk "/ тест $ / (отпечатайте $ 0)"
Намиране на текст в края на ред
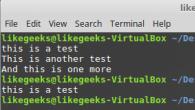
И двата символа на котва могат да се използват в един и същ модел. Нека обработим файла myfile, чието съдържание е показано на фигурата по-долу, като използваме следния регулярен израз:
$ awk "/ ^ това е тест $ / (отпечатайте $ 0)" myfile

Шаблон, който използва специални знаци за началото и края на ред
Както можете да видите, шаблонът реагира само на низ, който напълно съответства на определената последователност от знаци и тяхното местоположение.
Ето как да филтрирате празни редове с помощта на котвени знаци:
$ awk "! / ^ $ / (отпечатайте $ 0)" myfile
В този шаблон използвах символа за отрицание, удивителния знак -! ... Този шаблон търси редове, които не съдържат нищо между началото и края на реда, а удивителният знак отпечатва само редове, които не съвпадат с шаблона.
Символ на точка
Точката се използва за търсене на всеки единичен знак, с изключение на символа за преместване на ред. Нека предадем файла myfile на такъв регулярен израз, чието съдържание е дадено по-долу:$ awk "/.st/(print $ 0)" myfile

Използване на точка в регулярни изрази
Както можете да видите от показаните данни, само първите два реда от файла съответстват на шаблона, тъй като съдържат последователността от знаци "st", предшествана от още един знак, докато третият ред не съдържа подходяща последователност и в четвъртия е, но е в самото начало на реда.
Класове по персонажи
Точката съответства на всеки единичен знак, но какво ще стане, ако трябва да сте по-гъвкави в ограничаването на набора от знаци, които търсите? В подобна ситуация можете да използвате класове на знаци.Благодарение на този подход можете да организирате търсене на всеки герой от даден набор. Квадратните скоби се използват за описване на клас символи -:
$ awk "/ th / (отпечатайте $ 0)" myfile

Описание на класа на символите с регулярни изрази
Тук търсим поредица от знаци "th", предшествани от знака "o" или знака "i".
Класовете са полезни, когато търсите думи, които могат да започват както с главни, така и с малки букви:
$ echo "това е тест" | awk "/ неговият е тест / (отпечатайте $ 0)" $ echo "Това е тест" | awk "/ негово е тест / (отпечатайте $ 0)"
Намерете думи, които могат да започват с малка или главна буква
Класовете на знаци не се ограничават до букви. Тук могат да се използват и други символи. Невъзможно е да се каже предварително в каква ситуация ще са необходими класовете - всичко зависи от проблема, който се решава.
Отрицание на класовете символи
Класовете на символи могат да се използват и за решаване на обратния проблем, описан по-горе. А именно, вместо да търсите символи, включени в класа, можете да организирате търсене на всичко, което не е включено в класа. За да се постигне това поведение на регулярен израз, ^ трябва да се постави пред списъка със знаци на класа. Изглежда така:$ awk "/ [^ oi] th / (отпечатайте $ 0)" myfile

Намерете герои извън клас
В този случай ще бъдат намерени поредици от знаци "th", пред които няма нито "o", нито "i".
Диапазони от знаци
В класовете от знаци можете да опишете диапазони от знаци с помощта на тире:$ awk "/ st / (отпечатайте $ 0)" myfile

Описване на набор от знаци в клас символи
В този пример регулярният израз отговаря на последователността от знаци "st", предшествана от всеки знак, разположен по азбучен ред между знаците "e" и "p".
Диапазоните могат да бъдат създадени и от числа:
$ echo "123" | awk "//" $ echo "12a" | awk "//"
Редовен израз за намиране на произволни три числа
Няколко диапазона могат да бъдат включени в клас символи:
$ awk "/ st / (отпечатайте $ 0)" myfile

Клас на многообхватни знаци
Този регулярен израз ще съответства на всички низове, предшествани от знаци в диапазоните a-f и m-z.
Класове със специални знаци
BRE има специални символни класове, които можете да използвате, когато пишете регулярни изрази:- [[: alpha:]] - съответства на всеки алфавитен знак с главни или малки букви.
- [[: alnum:]] - съответства на всеки буквено-цифров знак, а именно знаци в диапазоните 0-9, A-Z, a-z.
- [[: blank:]] - съответства на интервал и раздел.
- [[: цифра:]] - всеки цифров знак от 0 до 9.
- [[: upper:]] - главни букви на азбуката - A-Z.
- [[: low:]] - малки букви - a-z.
- [[: print:]] - съответства на всеки символ за печат.
- [[: punct:]] - съвпада с препинателните знаци.
- [[: интервал:]] - символи за интервал, по-специално - интервал, табулация, NL, FF, VT, CR символи.
$ echo "abc" | awk "/ [[: alpha:]] / (отпечатване $ 0)" $ echo "abc" | awk "/ [[: цифра:]] / (отпечатване $ 0)" $ echo "abc123" | awk "/ [[: цифра:]] / (отпечатайте $ 0)"

Класове специални знаци в регулярни изрази
Символ на звезда
Ако поставите звездичка след символ в шаблона, това означава, че регулярният израз ще работи, ако знакът се появи в низа произволен брой пъти - включително ситуацията, когато в низа няма символ.$ echo "тест" | awk "/ tes * t / (отпечатване $ 0)" $ echo "tessst" | awk "/ tes * t / (отпечатайте $ 0)"

Използване на знака * в регулярни изрази
Този заместващ знак обикновено се използва за работа с думи, които постоянно съдържат печатни грешки, или за думи, които могат да бъдат изписани по различен начин:
$ echo "Харесвам зелен цвят" | awk "/ colou * r / (печат $ 0)" $ echo "Харесвам зелен цвят" | awk "/ colou * r / (отпечатайте $ 0)"
Потърсете дума, която има различно изписване
В този пример едно и също редовно изражение реагира както на думата „цвят”, така и на думата „цвят”. Това се дължи на факта, че символът "u", след който има звездичка, може да отсъства или да се появи няколко пъти подред.
Друга полезна функция, която следва от особеностите на символа звездичка, е комбинирането му с точка. Тази комбинация позволява на регулярния израз да отговаря на произволен брой всякакви знаци:
$ awk "/this.*test/(print $0)" myfile

Шаблон, който отговаря на произволен брой всякакви знаци
В този случай няма значение колко и какви знаци има между думите „това“ и „тест“.
Звездичката може да се използва и с класове знаци:
$ echo "st" | awk "/ s * t / (отпечатване $ 0)" $ echo "sat" | awk "/ s * t / (отпечатване $ 0)" $ echo "set" | awk "/ s * t / (отпечатайте $ 0)"

Използване на звездичката с класове знаци
И в трите примера регулярният израз работи, защото звездичката след класа на знаците означава, че ако се намерят произволен брой символи "a" или "e" или ако не могат да бъдат намерени, низът ще съответства на посочения шаблон.
POSIX ERE регулярни изрази
Шаблоните POSIX ERE, които някои помощни програми на Linux поддържат, може да съдържат допълнителни знаци. Както вече споменахме, awk поддържа този стандарт, но sed не.Тук ще разгледаме най-често използваните символи в ERE шаблоните, които ще ви бъдат полезни, когато създавате свои собствени регулярни изрази.
▍Въпросителен знак
Въпросителният знак показва, че предходният знак може да се появи веднъж в текста или изобщо да не се появи. Този герой е един от повтарящите се метазнаци. Ето няколко примера:$ echo "tet" | awk "/ tes? t / (отпечатайте $ 0)" $ echo "тест" | awk "/ tes? t / (отпечатване $ 0)" $ echo "testst" | awk "/ tes? t / (отпечатайте $ 0)"

Въпросителен знак в регулярни изрази
Както можете да видите, в третия случай буквата "s" се среща два пъти, така че регулярният израз не реагира на думата "testst".
Въпросителният знак може да се използва и с класове знаци:
$ echo "tst" | awk "/ t? st / (отпечатване $ 0)" $ echo "тест" | awk "/ t? st / (отпечатване $ 0)" $ echo "tast" | awk "/ t? st / (отпечатване $ 0)" $ echo "taest" | awk "/ t? st / (печат $ 0)" $ echo "тест" | awk "/ t? st / (отпечатайте $ 0)"

Въпросителни и знаци класове
Ако в низа няма знаци от класа или един от тях се появи веднъж, регулярният израз се задейства, но веднага щом в думата се появят два знака, системата вече не намира съвпадение за шаблона в текста.
▍Символ плюс
Символът плюс в шаблона показва, че регулярният израз ще намери желания, ако предходният знак се появи един или повече пъти в текста. В същото време такава конструкция няма да реагира на липсата на символ:$ echo "тест" | awk "/ te + st / (отпечатване $ 0)" $ echo "тест" | awk "/ te + st / (отпечатване $ 0)" $ echo "tst" | awk "/ te + st / (отпечатайте $ 0)"

Плюс влизане в регулярни изрази
В този пример, ако няма „e“ в една дума, механизмът за регулярни изрази няма да намери съвпадение за шаблона в текста. Символът плюс работи и с класове знаци, което го прави да изглежда като звездичка и въпросителен знак:
$ echo "tst" | awk "/ t + st / (отпечатване $ 0)" $ echo "тест" | awk "/ t + st / (отпечатване $ 0)" $ echo "тест" | awk "/ t + st / (отпечатване $ 0)" $ echo "teeast" | awk "/ t + st / (отпечатайте $ 0)"

Плюс класове със знаци и знаци
В този случай, ако низът съдържа символ от класа, текстът ще се счита за съответстващ на шаблона.
▍Скоби за знаци
Къдравите скоби, които можете да използвате в шаблоните на ERE, са подобни на символите, обсъдени по-горе, но ви позволяват по-точно да посочите необходимия брой поява на символа, който ги предхожда. Ограничението може да бъде определено в два формата:- n е число, което определя точния брой събития, които да търсите
- n, m - две числа, които се тълкуват по следния начин: "най-малко n пъти, но не повече от m".
$ echo "tst" | awk "/ te (1) st / (отпечатайте $ 0)" $ echo "тест" | awk "/ te (1) st / (отпечатайте $ 0)"
Къдрави скоби в шаблони, намерете точен брой събития
В по-старите версии на awk трябваше да използвате превключвателя на командния ред --re-interval, за да може програмата да разпознава интервали в регулярните изрази, но в по-новите версии това не е необходимо.
$ echo "tst" | awk "/ te (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ te (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ te (1,2) st / (отпечатване $ 0)" $ echo "teeest" | awk "/ te (1,2) st / (отпечатайте $ 0)"

Разстоянието, определено в къдрави скоби
В този пример символът "e" трябва да се появи на реда 1 или 2 пъти, след което регулярният израз ще реагира на текста.
Къдравите скоби могат да се използват и с класове знаци. Ето принципите, които вече са ви познати:
$ echo "tst" | awk "/ t (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ t (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ t (1,2) st / (отпечатване $ 0)" $ echo "teeast" | awk "/ t (1,2) st / (отпечатайте $ 0)"

Къдрави скоби и класове знаци
Шаблонът ще реагира на текста, ако съдържа знака "a" или знака "e" веднъж или два пъти.
▍ Булева или символ
Символ | - вертикална лента, означава логическо "или" в регулярните изрази. Когато обработва регулярен израз, съдържащ няколко фрагмента, разделени с такъв знак, машината ще счита анализирания текст за подходящ, ако съвпада с някой от фрагментите. Ето един пример:$ echo "Това е тест" | awk "/ тест | изпит / (отпечатване $ 0)" $ echo "Това е изпит" | awk "/ тест | изпит / (отпечатване $ 0)" $ echo "Това е нещо друго" | awk "/ тест | изпит / (отпечатване $ 0)"

Булев "или" в регулярни изрази
В този пример регулярният израз е конфигуриран да търси в текста думите "тест" или "изпит". Имайте предвид, че между фрагментите на шаблона и разделящите | не трябва да има интервали.
Фрагменти на регулярна експресия могат да бъдат групирани с помощта на скоби. Ако групирате определена последователност от знаци, тя ще бъде възприета от системата като обикновен символ. Тоест, например, ще бъде възможно да се прилагат метасимволи за повторение към него. Ето как изглежда:$ echo "Харесвам" | awk "/ Харесвам (Geeks)? / (отпечатайте $ 0)" $ echo "LikeGeeks" | awk "/ Харесвам (Гийкове)? / (отпечатайте $ 0)"

Групиране на фрагменти с регулярни изрази
В тези примери думата "Geeks" е затворена в скоби, последвана от въпросителен знак. Припомнете си, че въпросителният знак означава "0 или 1 повторение", в резултат на което регулярният израз ще отговори както на низа "Like", така и на низа "LikeGeeks".
Практически примери
След като разгледахме основите на регулярните изрази, е време да направим нещо полезно с тях.▍Преброяване на броя на файловете
Нека напишем bash скрипт, който брои файловете в директориите, които са записани в променливата на средата PATH. За да направите това, първо ще трябва да генерирате списък с пътища към директории. Нека го направим със sed, като заменим двоеточия с интервали:$ ехо $ ПЪТ | sed "s /: / / g"
Командата replace поддържа регулярни изрази като шаблони за търсене на текст. В случая всичко е изключително просто, търсим символ на двоеточие, но никой не си прави труда да използва нещо друго тук - всичко зависи от конкретната задача.
Сега трябва да преминете през получения списък в цикъл и да извършите действията, необходими за преброяване на броя на файловете там. Общата схема на скрипта ще бъде както следва:
Mypath = $ (echo $ PATH | sed "s /: / / g") за директория в $ mypath do done
Сега нека напишем пълния текст на скрипта, като използваме командата ls, за да получим информация за броя на файловете във всяка от директориите:
#! / bin / bash mypath = $ (echo $ PATH | sed "s /: / / g") count = 0 за директория в $ mypath do check = $ (ls $ директория) за елемент в $ check do count = $ [$ count + 1] done echo "$ директория - $ count" count = 0 готово
Когато стартирате скрипта, може да се окаже, че някои директории от PATH не съществуват, но това няма да му попречи да брои файлове в съществуващи директории.

Преброяване на файлове
Основната стойност на този пример се крие във факта, че с помощта на същия подход можете да решите много по-сложни проблеми. Кое точно зависи от вашите нужди.
▍Проверка на имейл адреси
Има уебсайтове с огромни колекции от регулярни изрази, които ви позволяват да проверявате имейл адреси, телефонни номера и т.н. Едно е обаче да вземеш готов, а съвсем друго да създадеш нещо сам. Така че нека напишем регулярен израз за валидиране на имейл адреси. Нека започнем с анализ на първоначалните данни. Ето например определен адрес:[защитен с имейл]
Потребителското име, потребителското име може да бъде буквено-цифрено и някои други знаци. А именно, това е точка, тире, долна черта, знак плюс. Потребителското име е последвано от знака @.
Въоръжени с това знание, нека започнем да сглобяваме регулярния израз от лявата му страна, който служи за валидиране на потребителското име. Ето какво получихме:
^(+)@
Този регулярен израз може да се чете по следния начин: "В началото на ред трябва да има поне един знак от тези в групата, посочена в квадратни скоби, а след това трябва да има знак @."
Сега е опашката за име на хост - име на хост. Тук важат същите правила като за потребителското име, така че шаблонът за него ще изглежда така:
(+)
Името на домейн от най-високо ниво е предмет на специални правила. Може да има само азбучни знаци, от които трябва да има поне два (например такива домейни обикновено съдържат код на държавата) и не повече от пет. Всичко това означава, че шаблонът за проверка на последната част от адреса ще бъде така:
\.({2,5})$
Можете да го прочетете така: "Първо трябва да има точка, след това - от 2 до 5 азбучни знака и след това редът свършва."
След като подготвихме шаблоните за отделните части на регулярния израз, нека ги съберем заедно:
^(+)@(+)\.({2,5})$
Сега остава само да тестваме какво се е случило:
$ ехо " [защитен с имейл]"| awk" /^(+)@(+)\.((2,5))$/(печат $0) "$ ехо" [защитен с имейл]"| awk" /^(+)@(+)\.((2,5))$/(печат $0) "

Проверка на имейл адрес с помощта на регулярни изрази
Фактът, че текстът, предаден на awk, се отпечатва на екрана, означава, че системата е разпознала имейл адреса в него.
Резултати
Ако регулярният израз за валидиране на имейл адреси, който срещнахте в самото начало на статията, изглеждаше напълно неразбираем тогава, ние се надяваме, че сега вече не изглежда като безсмислен набор от знаци. Ако това е вярно, значи този материал е изпълнил целта си. Всъщност регулярните изрази са тема, с която можете да се занимавате цял живот, но дори малкото, което обсъдихме, вече може да ви помогне при писането на скриптове, които обработват текстове доста напреднало.В тази серия от статии обикновено показвахме много прости примери за bash скриптове, които се състоят буквално от няколко реда. Следващия път нека погледнем нещо по-голямо.
Уважаеми читатели! Използвате ли регулярни изрази, когато обработвате текст в скриптове на командния ред?
За да обработвате напълно текстове в bash скриптове, използвайки sed и awk, просто трябва да разберете регулярните изрази. Реализациите на този най-полезен инструмент могат да бъдат намерени буквално навсякъде и въпреки че всички регулярни изрази са подредени по подобен начин, базирани на едни и същи идеи, работата с тях има определени особености в различни среди. Тук ще говорим за регулярни изрази, които са подходящи за използване в скриптове на командния ред на Linux.
Този материал е предназначен да бъде въведение в регулярните изрази за тези, които може би изобщо не знаят какво представляват. Така че нека започнем от самото начало.
Какво представляват регулярните изрази
При мнозина, когато за първи път видят регулярни изрази, веднага възниква мисълта, че са пред безсмислена смесица от знаци. Но това, разбира се, далеч не е така. Разгледайте този регулярен израз например
Според нас дори абсолютен начинаещ веднага ще разбере как работи и защо ви е нужен :) Ако не разбирате съвсем, просто прочетете и всичко ще си дойде на мястото.
Регулярният израз е модел, който програми като sed или awk използват за филтриране на текст. Шаблоните използват обикновени ASCII знаци, които представляват себе си, и така наречените метасимволи, които играят специална роля, например, позволявайки ви да се позовавате на определени групи знаци.
Типове регулярни изрази
Реализациите на регулярни изрази в различни среди, като езици за програмиране като Java, Perl и Python, и инструменти на Linux като sed, awk и grep, имат определени странности. Тези функции зависят от така наречените машини за регулярни изрази, които интерпретират шаблони.
Има два механизма за регулярни изрази в Linux:
- Машина, която поддържа стандарта POSIX Basic Regular Expression (BRE).
- Машина, която поддържа стандарта POSIX Extended Regular Expression (ERE).
Повечето помощни програми на Linux отговарят поне на стандарта POSIX BRE, но някои помощни програми (включително sed) разбират само подмножество от стандарта BRE. Една от причините за това ограничение е желанието подобни помощни програми да се направят възможно най-бързи в текстообработката.
Стандартът POSIX ERE често се прилага в езици за програмиране. Позволява ви да използвате много инструменти при проектирането на регулярни изрази. Например, това могат да бъдат специални поредици от знаци за често използвани модели, като например търсене в текста за отделни думи или набори от числа. Awk поддържа стандарта ERE.
Има много начини за разработване на регулярни изрази, в зависимост както от мнението на програмиста, така и от характеристиките на двигателя, за който са създадени. Не е лесно да се напишат общи регулярни изрази, които всеки двигател може да разбере. Затова ще се съсредоточим върху най-често използваните регулярни изрази и ще разгледаме как са имплементирани за sed и awk.
POSIX BRE регулярни изрази
Може би най-простият модел BRE е регулярен израз за намиране на точното появяване на поредица от знаци в текста. Ето как изглежда sed и awk търсенето на низ:
$ echo "Това е тест" | sed -n "/ test / p" $ echo "Това е тест" | awk "/ тест / (отпечатайте $ 0)"
Търсене на текст по шаблон в sed
Намиране на текст по шаблон в awk
Можете да забележите, че търсенето на даден шаблон се извършва без да се отчита точното местоположение на текста в низа. Освен това броят на събитията няма значение. След като регулярният израз намери посочения текст навсякъде в низа, низът се счита за валиден и се предава за по-нататъшна обработка.
Когато работите с регулярни изрази, имайте предвид, че те са чувствителни към главни букви:
$ echo "Това е тест" | awk "/ Тест / (отпечатване $ 0)" $ echo "Това е тест" | awk "/ тест / (отпечатайте $ 0)"
Регулярните изрази са чувствителни към главни букви
Първият регулярен израз не съвпада, тъй като думата "тест", започваща с главна буква, не се среща в текста. Вторият, конфигуриран да търси дума с главни букви, намери съвпадащ низ в потока.
В регулярните изрази можете да използвате не само букви, но и интервали и числа:
$ echo "Това отново е тест 2" | awk "/ тест 2 / (отпечатайте $ 0)"
Намерете част от текст, съдържаща интервали и числа
Пространствата се третират като редовни знаци от механизма за регулярни изрази.
Специални символи
Има няколко неща, които трябва да имате предвид, когато използвате различни знаци в регулярни изрази. И така, има някои специални знаци или метазнаци, които изискват специален подход за използване в шаблон. Ето ги и тях:
.*^${}+?|()Ако един от тях е необходим в шаблона, той ще трябва да бъде екраниран с обратна наклонена черта (обратна наклонена черта) -.
Например, ако трябва да намерите знак за долар в текста, той трябва да бъде включен в шаблона, предшестван от escape-символ. Да приемем, че имате файл, наречен myfile със следния текст:
В джоба ми има 10 $
Знакът на долара може да бъде открит с помощта на модел като този:
$ awk "/ $ / (отпечатайте $ 0)" myfile
Използване на специален символ в шаблон
В допълнение, обратната наклонена черта също е специален знак, така че ако искате да го използвате в шаблон, ще трябва също да го избягате. Изглежда като две наклонени черти напред:
$ echo "е специален символ" | awk "/ \ / (отпечатайте $ 0)"
Обратна наклонена черта избяга
Въпреки че наклонената черта не е включена в горния списък със специални знаци, опитът да се използва в регулярен израз, написан за sed или awk, ще доведе до грешка:
Неправилно използване на наклонена черта в шаблон
Ако имате нужда от него, трябва също да го прегледате:
$ echo "3/2" | awk "/// (отпечатайте $ 0)"
Наклонена черта напред
Котва символи
Има два специални знака за закотвяне на шаблон към началото или края на текстов низ. Символът на корицата - ^ ви позволява да опишете поредици от знаци, които се появяват в началото на текстовите редове. Ако моделът, който търсите, се появи на друго място в низа, регулярният израз няма да отговори на него. Използването на този символ изглежда така:
$ echo "добре дошли в уебсайта на likegeeks" | awk "/ ^ likegeeks / (печат $ 0)" $ echo "сайт на likegeeks" | awk "/ ^ likegeeks / (отпечатайте $ 0)"
Намиране на шаблон в началото на ред
Символът ^ е предназначен за търсене на шаблон в началото на низ, като случайът също се взема предвид. Нека видим как това се отразява на обработката на текстов файл:
$ awk "/ ^ това / (отпечатайте $ 0)" myfile

Търсене на шаблон в началото на ред в текст от файл
Със sed, ако поставите капачка някъде вътре в шаблона, тя ще се третира като всеки друг редовен знак:
$ echo "Това ^ е тест" | sed -n "/ s ^ / p"
Не покривайте в началото на шаблона в sed
В awk, когато се използва същия модел, даденият символ трябва да бъде екраниран:
$ echo "Това ^ е тест" | awk "/ s ^ / (отпечатайте $ 0)"
Корица не в началото на шаблон в awk
Разбрахме търсенето на текстови фрагменти, разположени в началото на реда. Ами ако искате да намерите нещо в края на реда?
Знакът за долар - $, който е символът за котва за края на реда, ще ни помогне за това:
$ echo "Това е тест" | awk "/ тест $ / (отпечатайте $ 0)"
Намиране на текст в края на ред
И двата символа на котва могат да се използват в един и същ модел. Нека обработим файла myfile, чието съдържание е показано на фигурата по-долу, като използваме следния регулярен израз:
$ awk "/ ^ това е тест $ / (отпечатайте $ 0)" myfile

Шаблон, който използва специални знаци за началото и края на ред
Както можете да видите, шаблонът реагира само на низ, който напълно съответства на определената последователност от знаци и тяхното местоположение.
Ето как да филтрирате празни редове с помощта на котвени знаци:
$ awk "! / ^ $ / (отпечатайте $ 0)" myfile
В този шаблон използвах символа за отрицание, удивителния знак -! ... Този шаблон търси редове, които не съдържат нищо между началото и края на реда, а удивителният знак отпечатва само редове, които не съвпадат с шаблона.
Символ на точка
Точката се използва за търсене на всеки единичен знак, с изключение на символа за преместване на ред. Нека предадем файла myfile на такъв регулярен израз, чието съдържание е дадено по-долу:
$ awk "/.st/(print $ 0)" myfile

Използване на точка в регулярни изрази
Както можете да видите от показаните данни, само първите два реда от файла съответстват на шаблона, тъй като съдържат последователността от знаци "st", предшествана от още един знак, докато третият ред не съдържа подходяща последователност и в четвъртия е, но е в самото начало на реда.
Класове по персонажи
Точката съответства на всеки единичен знак, но какво ще стане, ако трябва да сте по-гъвкави в ограничаването на набора от знаци, които търсите? В подобна ситуация можете да използвате класове на знаци.
Благодарение на този подход можете да организирате търсене на всеки герой от даден набор. Квадратните скоби се използват за описване на клас символи -:
$ awk "/ th / (отпечатайте $ 0)" myfile

Описание на класа на символите с регулярни изрази
Тук търсим поредица от знаци "th", предшествани от знака "o" или знака "i".
Класовете са полезни, когато търсите думи, които могат да започват както с главни, така и с малки букви:
$ echo "това е тест" | awk "/ неговият е тест / (отпечатайте $ 0)" $ echo "Това е тест" | awk "/ негово е тест / (отпечатайте $ 0)"
Намерете думи, които могат да започват с малка или главна буква
Класовете на знаци не се ограничават до букви. Тук могат да се използват и други символи. Невъзможно е да се каже предварително в каква ситуация ще са необходими класовете - всичко зависи от проблема, който се решава.
Отрицание на класовете символи
Класовете на символи могат да се използват и за решаване на обратния проблем, описан по-горе. А именно, вместо да търсите символи, включени в класа, можете да организирате търсене на всичко, което не е включено в класа. За да се постигне това поведение на регулярен израз, ^ трябва да се постави пред списъка със знаци на класа. Изглежда така:
$ awk "/ [^ oi] th / (отпечатайте $ 0)" myfile

Намерете герои извън клас
В този случай ще бъдат намерени поредици от знаци "th", пред които няма нито "o", нито "i".
Диапазони от знаци
В класовете от знаци можете да опишете диапазони от знаци с помощта на тире:
$ awk "/ st / (отпечатайте $ 0)" myfile

Описване на набор от знаци в клас символи
В този пример регулярният израз отговаря на последователността от знаци "st", предшествана от всеки знак, разположен по азбучен ред между знаците "e" и "p".
Диапазоните могат да бъдат създадени и от числа:
$ echo "123" | awk "//" $ echo "12a" | awk "//"
Редовен израз за намиране на произволни три числа
Няколко диапазона могат да бъдат включени в клас символи:
$ awk "/ st / (отпечатайте $ 0)" myfile

Клас на многообхватни знаци
Този регулярен израз ще съответства на всички низове, предшествани от знаци в диапазоните a-f и m-z.
Класове със специални знаци
BRE има специални символни класове, които можете да използвате, когато пишете регулярни изрази:
- [[: alpha:]] - съответства на всеки алфавитен знак с главни или малки букви.
- [[: alnum:]] - съответства на всеки буквено-цифров знак, а именно знаци в диапазоните 0-9, A-Z, a-z.
- [[: blank:]] - съответства на интервал и раздел.
- [[: цифра:]] - всеки цифров знак от 0 до 9.
- [[: upper:]] - главни букви на азбуката - A-Z.
- [[: low:]] - малки букви - a-z.
- [[: print:]] - съответства на всеки символ за печат.
- [[: punct:]] - съвпада с препинателните знаци.
- [[: интервал:]] - символи за интервал, по-специално - интервал, табулация, NL, FF, VT, CR символи.
Можете да използвате специални класове в шаблони като този:
$ echo "abc" | awk "/ [[: alpha:]] / (отпечатване $ 0)" $ echo "abc" | awk "/ [[: цифра:]] / (отпечатване $ 0)" $ echo "abc123" | awk "/ [[: цифра:]] / (отпечатайте $ 0)"

Класове специални знаци в регулярни изрази
Символ на звезда
Ако поставите звездичка след символ в шаблона, това означава, че регулярният израз ще работи, ако знакът се появи в низа произволен брой пъти - включително ситуацията, когато в низа няма символ.
$ echo "тест" | awk "/ tes * t / (отпечатване $ 0)" $ echo "tessst" | awk "/ tes * t / (отпечатайте $ 0)"

Използване на знака * в регулярни изрази
Този заместващ знак обикновено се използва за работа с думи, които постоянно съдържат печатни грешки, или за думи, които могат да бъдат изписани по различен начин:
$ echo "Харесвам зелен цвят" | awk "/ colou * r / (печат $ 0)" $ echo "Харесвам зелен цвят" | awk "/ colou * r / (отпечатайте $ 0)"
Потърсете дума, която има различно изписване
В този пример едно и също редовно изражение реагира както на думата „цвят”, така и на думата „цвят”. Това се дължи на факта, че символът "u", след който има звездичка, може да отсъства или да се появи няколко пъти подред.
Друга полезна функция, която следва от особеностите на символа звездичка, е комбинирането му с точка. Тази комбинация позволява на регулярния израз да отговаря на произволен брой всякакви знаци:
$ awk "/this.*test/(print $0)" myfile

Шаблон, който отговаря на произволен брой всякакви знаци
В този случай няма значение колко и какви знаци има между думите „това“ и „тест“.
Звездичката може да се използва и с класове знаци:
$ echo "st" | awk "/ s * t / (отпечатване $ 0)" $ echo "sat" | awk "/ s * t / (отпечатване $ 0)" $ echo "set" | awk "/ s * t / (отпечатайте $ 0)"

Използване на звездичката с класове знаци
И в трите примера регулярният израз работи, защото звездичката след класа на знаците означава, че ако се намерят произволен брой символи "a" или "e" или ако не могат да бъдат намерени, низът ще съответства на посочения шаблон.
POSIX ERE регулярни изрази
Шаблоните POSIX ERE, които някои помощни програми на Linux поддържат, може да съдържат допълнителни знаци. Както вече споменахме, awk поддържа този стандарт, но sed не.
Тук ще разгледаме най-често използваните символи в ERE шаблоните, които ще ви бъдат полезни, когато създавате свои собствени регулярни изрази.
▍Въпросителен знак
Въпросителният знак показва, че предходният знак може да се появи веднъж в текста или изобщо да не се появи. Този герой е един от повтарящите се метазнаци. Ето няколко примера:
$ echo "tet" | awk "/ tes? t / (отпечатайте $ 0)" $ echo "тест" | awk "/ tes? t / (отпечатване $ 0)" $ echo "testst" | awk "/ tes? t / (отпечатайте $ 0)"

Въпросителен знак в регулярни изрази
Както можете да видите, в третия случай буквата "s" се среща два пъти, така че регулярният израз не реагира на думата "testst".
Въпросителният знак може да се използва и с класове знаци:
$ echo "tst" | awk "/ t? st / (отпечатване $ 0)" $ echo "тест" | awk "/ t? st / (отпечатване $ 0)" $ echo "tast" | awk "/ t? st / (отпечатване $ 0)" $ echo "taest" | awk "/ t? st / (печат $ 0)" $ echo "тест" | awk "/ t? st / (отпечатайте $ 0)"

Въпросителни и знаци класове
Ако в низа няма знаци от класа или един от тях се появи веднъж, регулярният израз се задейства, но веднага щом в думата се появят два знака, системата вече не намира съвпадение за шаблона в текста.
▍Символ плюс
Символът плюс в шаблона показва, че регулярният израз ще намери желания, ако предходният знак се появи един или повече пъти в текста. В същото време такава конструкция няма да реагира на липсата на символ:
$ echo "тест" | awk "/ te + st / (отпечатване $ 0)" $ echo "тест" | awk "/ te + st / (отпечатване $ 0)" $ echo "tst" | awk "/ te + st / (отпечатайте $ 0)"

Плюс влизане в регулярни изрази
В този пример, ако няма „e“ в една дума, механизмът за регулярни изрази няма да намери съвпадение за шаблона в текста. Символът плюс работи и с класове знаци, което го прави да изглежда като звездичка и въпросителен знак:
$ echo "tst" | awk "/ t + st / (отпечатване $ 0)" $ echo "тест" | awk "/ t + st / (отпечатване $ 0)" $ echo "тест" | awk "/ t + st / (отпечатване $ 0)" $ echo "teeast" | awk "/ t + st / (отпечатайте $ 0)"

Плюс класове със знаци и знаци
В този случай, ако низът съдържа символ от класа, текстът ще се счита за съответстващ на шаблона.
▍Скоби за знаци
Къдравите скоби, които можете да използвате в шаблоните на ERE, са подобни на символите, обсъдени по-горе, но ви позволяват по-точно да посочите необходимия брой поява на символа, който ги предхожда. Ограничението може да бъде определено в два формата:
- n е число, което определя точния брой събития, които да търсите
- n, m - две числа, които се тълкуват по следния начин: "най-малко n пъти, но не повече от m".
Ето примери за първия вариант:
$ echo "tst" | awk "/ te (1) st / (отпечатайте $ 0)" $ echo "тест" | awk "/ te (1) st / (отпечатайте $ 0)"
Къдрави скоби в шаблони, намерете точен брой събития
В по-старите версии на awk трябваше да използвате превключвателя на командния ред --re-interval, за да може програмата да разпознава интервали в регулярните изрази, но в по-новите версии това не е необходимо.
$ echo "tst" | awk "/ te (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ te (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ te (1,2) st / (отпечатване $ 0)" $ echo "teeest" | awk "/ te (1,2) st / (отпечатайте $ 0)"

Разстоянието, определено в къдрави скоби
В този пример символът "e" трябва да се появи на реда 1 или 2 пъти, след което регулярният израз ще реагира на текста.
Къдравите скоби могат да се използват и с класове знаци. Ето принципите, които вече са ви познати:
$ echo "tst" | awk "/ t (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ t (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ t (1,2) st / (отпечатване $ 0)" $ echo "teeast" | awk "/ t (1,2) st / (отпечатайте $ 0)"

Къдрави скоби и класове знаци
Шаблонът ще реагира на текста, ако съдържа знака "a" или знака "e" веднъж или два пъти.
▍ Булева или символ
Символ | - вертикална лента, означава логическо "или" в регулярните изрази. Когато обработва регулярен израз, съдържащ няколко фрагмента, разделени с такъв знак, машината ще счита анализирания текст за подходящ, ако съвпада с някой от фрагментите. Ето един пример:
$ echo "Това е тест" | awk "/ тест | изпит / (отпечатване $ 0)" $ echo "Това е изпит" | awk "/ тест | изпит / (отпечатване $ 0)" $ echo "Това е нещо друго" | awk "/ тест | изпит / (отпечатване $ 0)"

Булев "или" в регулярни изрази
В този пример регулярният израз е конфигуриран да търси в текста думите "тест" или "изпит". Имайте предвид, че между фрагментите на шаблона и разделящите | не трябва да има интервали.
Фрагменти на регулярна експресия могат да бъдат групирани с помощта на скоби. Ако групирате определена последователност от знаци, тя ще бъде възприета от системата като обикновен символ. Тоест, например, ще бъде възможно да се прилагат метасимволи за повторение към него. Ето как изглежда:
$ echo "Харесвам" | awk "/ Харесвам (Geeks)? / (отпечатайте $ 0)" $ echo "LikeGeeks" | awk "/ Харесвам (Гийкове)? / (отпечатайте $ 0)"

Групиране на фрагменти с регулярни изрази
В тези примери думата "Geeks" е затворена в скоби, последвана от въпросителен знак. Припомнете си, че въпросителният знак означава "0 или 1 повторение", в резултат на което регулярният израз ще отговори както на низа "Like", така и на низа "LikeGeeks".
Практически примери
След като разгледахме основите на регулярните изрази, е време да направим нещо полезно с тях.
▍Преброяване на броя на файловете
Нека напишем bash скрипт, който брои файловете в директориите, които са записани в променливата на средата PATH. За да направите това, първо ще трябва да генерирате списък с пътища към директории. Нека го направим със sed, като заменим двоеточия с интервали:
$ ехо $ ПЪТ | sed "s /: / / g"
Командата replace поддържа регулярни изрази като шаблони за търсене на текст. В случая всичко е изключително просто, търсим символ на двоеточие, но никой не си прави труда да използва нещо друго тук - всичко зависи от конкретната задача.
Сега трябва да преминете през получения списък в цикъл и да извършите действията, необходими за преброяване на броя на файловете там. Общата схема на скрипта ще бъде както следва:
Mypath = $ (echo $ PATH | sed "s /: / / g") за директория в $ mypath do done
Сега нека напишем пълния текст на скрипта, като използваме командата ls, за да получим информация за броя на файловете във всяка от директориите:
#! / bin / bash mypath = $ (echo $ PATH | sed "s /: / / g") count = 0 за директория в $ mypath do check = $ (ls $ директория) за елемент в $ check do count = $ [$ count + 1] done echo "$ директория - $ count" count = 0 готово
Когато стартирате скрипта, може да се окаже, че някои директории от PATH не съществуват, но това няма да му попречи да брои файлове в съществуващи директории.

Преброяване на файлове
Основната стойност на този пример се крие във факта, че с помощта на същия подход можете да решите много по-сложни проблеми. Кое точно зависи от вашите нужди.
▍Проверка на имейл адреси
Има уебсайтове с огромни колекции от регулярни изрази, които ви позволяват да проверявате имейл адреси, телефонни номера и т.н. Едно е обаче да вземеш готов, а съвсем друго да създадеш нещо сам. Така че нека напишем регулярен израз за валидиране на имейл адреси. Нека започнем с анализ на първоначалните данни. Ето например определен адрес:
Потребителското име, потребителското име може да бъде буквено-цифрено и някои други знаци. А именно, това е точка, тире, долна черта, знак плюс. Потребителското име е последвано от знака @.
Въоръжени с това знание, нека започнем да сглобяваме регулярния израз от лявата му страна, който служи за валидиране на потребителското име. Ето какво получихме:
^(+)@
Сега е опашката за име на хост - име на хост. Тук важат същите правила като за потребителското име, така че шаблонът за него ще изглежда така:
(+)
Името на домейн от най-високо ниво е предмет на специални правила. Може да има само азбучни знаци, от които трябва да има поне два (например такива домейни обикновено съдържат код на държавата) и не повече от пет. Всичко това означава, че шаблонът за проверка на последната част от адреса ще бъде така:
.({2,5})$
Можете да го прочетете така: "Първо трябва да има точка, след това - от 2 до 5 азбучни знака и след това редът свършва."
След като подготвихме шаблоните за отделните части на регулярния израз, нека ги съберем заедно:
^(+)@(+).({2,5})$
Сега остава само да тестваме какво се е случило:
$ ехо " [защитен с имейл]"| awk" /^(+)@(+).((2,5))$/(print $0) "$ echo" [защитен с имейл]"| awk" /^(+)@(+).((2,5))$/(печат $0) "

Проверка на имейл адрес с помощта на регулярни изрази
Фактът, че текстът, предаден на awk, се отпечатва на екрана, означава, че системата е разпознала имейл адреса в него.
Резултати
Ако регулярният израз за валидиране на имейл адреси, който срещнахте в самото начало на статията, изглеждаше напълно неразбираем тогава, надяваме се, че сега вече не изглежда като безсмислен набор от знаци. Ако това е вярно, значи този материал е изпълнил целта си. Всъщност регулярните изрази са тема, с която можете да се занимавате цял живот, но дори малкото, което обсъдихме, вече може да ви помогне при писането на скриптове, които обработват текстове доста напреднало.
В тази серия от статии обикновено показвахме много прости примери за bash скриптове, които се състоят буквално от няколко реда. Следващия път нека погледнем нещо по-голямо.
Уважаеми читатели! Използвате ли регулярни изрази, когато обработвате текст в скриптове на командния ред?
Редовен израз- текстов модел, състоящ се от комбинация от букви, цифри и специални знаци, известни като метазнаци. Близък братовчед на регулярните изрази са заместващи изрази, които обикновено се използват в управлението на файлове. Регулярните изрази се използват главно за сравнение и търсене на текст. Използва се широко за анализиране на синтаксис.
Потребителите на UNIX са запознати с регулярните изрази от grep, sed, awk (или gawk) и ed. Използвайки тези програми или техните аналози, можете да опитате и да проверите примерите по-долу. Текстови редактори като (X) Emacs и vi също използват силно регулярни изрази. Може би най-известното и най-широко използване на регулярни изрази се среща в езика Perl. За разработчика на софтуер и системния администратор е трудно да се справят без познаване на регулярните изрази.
Метазнаци
И така, низовете могат да бъдат съставени от букви, цифри и метазнаци. Метазнаците са:
\ | () { } ^ $ * + ? . < >
Метазнаците могат да играят следните роли в регулярен израз:
квантор
изявление;
групов знак;
алтернатива;
знак за последователност
Квантори
Метазнакът * (звездичка) замества 0 или повече знака. Метазнакът + (плюс) замества 1 или повече знака. Метахарактер. (точка) замества точно 1 произволен знак. Метахарактер? (въпросителен знак) замества 0 или 1 знак. Разликата в използването на * и + е такава, че заявка за намиране на низ с * ще върне всякакви низове, включително празни, а заявка с + ще върне само низове, съдържащи символа c.
Празните редове се подчиняват на следните конвенции: Празен ред съдържа един и само един празен ред; непразен ред съдържа празни редове преди всеки знак, а също и в края на реда.
Регулярните изрази също използват конструкцията (n, m), което означава, че символът, предхождащ конструкцията, се среща от n до m пъти в низа. Пропускането на числото m означава безкрайност. Тези. специални случаи на конструкцията са следните записи: (0,), (1,) и (0,1). Първият съответства на *, вторият съответства на метазнака +, а третият съвпада? ... Тези равенства са лесни за получаване от дефиницията на съответните квантори. Освен това конструкцията (n) означава, че символът се появява точно n пъти.
Във връзка с използването на някои препинателни знаци и математически символи като метасимволи, е въведен допълнителен метазнак \ (обратна наклонена черта, обратна наклонена черта), която при изписване преди метазнака превръща последния в обикновен знак. Тези. ? е квантор, а \? - въпросителен знак.
Групи
Описаните по-горе квантификатори, както вече споменахме, действат върху най-близкия до тях герой вляво (последният предхождащ). Но това ограничение ви позволява да заобиколите групите в обозначението на метасимволите (и). Тези знаци извличат подизраз от израз, групиран в група, към който след това се прилага квантор.
пример:
означава (или замества)
Хо хо хо хо хо хо хохо
Възможно е влагане на подизрази, т.е. по-кратки подизрази могат да бъдат извлечени от подизраз.
Алтернативи
Създаден с помощта на метазнака | (вертикална лента), обозначаваща логическо „или“.
Пример: регулярен израз крави (a | s | e | y | опа | oyu)? посочва всички възможни склонения на думата "крава" в единствено число за падежи.
твърдения
Разпределят се метасимволи, които обозначават специални обекти - низове с нулева дължина, които се използват за определяне на мястото на текста, предхождащ или следващ ги. Такива обекти се наричат изявления. Следните изрази съществуват в регулярни изрази:
^ начало на ред $ край на реда< начало слова >край на думатаПример: регулярният израз $ The съвпада с низа, който започва с The.
Забележка: Редовните знаци могат да се разглеждат като изрази с ненулева дължина.
Последователности
Специална конструкция, затворена в метасимволите [и] (квадратни скоби), ви позволява да изброите вариантите на знаци, които могат да се появят в регулярния израз на дадено място, и се нарича последователност. В квадратните скоби всички метасимволи се третират като прости символи, а символите - (минус) и ^ придобиват нови значения: първият ви позволява да посочите непрекъсната последователност от знаци между двата посочени, а вторият дава логическо "не" ( отрицание). Следните примери са най-лесни за разглеждане:
някоя от малките латински букви:
латински букви и цифри (от a до z, от A до Z и от 0 до 9):
нелатински буквено-цифров знак:
[^ a-zA-Z0-9]
всяка дума (без тирета, математически символи и числа):
<+>
За краткост и простота се въвеждат следните съкращения:
\ d цифра (т.е. съвпада с израз); \ D не е цифра (т.е. [^ 0-9]); \ w латинска дума (буквено-цифрова); \ W е поредица от знаци без интервали, която не е латинска буквено-цифрова дума ([^ a-zA-Z0-9]); \ s празно пространство [\ t \ n \ r \ f], т.е интервали, табулатори и др. \ S е непразен интервал ([^ \ t \ n \ r \ f]).Връзка с заместващи знаци
Всеки потребител вероятно е запознат със заместващите знаци. Пример за заместващ израз е * .jpg, който обозначава всички файлове с разширение jpg. По какво се различават регулярните изрази от заместващите символи? Разликите могат да бъдат обобщени в три правила за преобразуване на произволен заместващ израз в регулярен израз:
Заменено от.*
Замяна? на.
Заменете всички знаци, които съвпадат с метасимволи с техните варианти с обратна наклонена черта.
Всъщност в регулярен израз писането * е безполезно и дава празен низ, т.к означава, че празният низ се повтаря произволен брой пъти. И ето. * (Повторете произволен знак колкото пъти искате, включително 0) точно съвпада по значение със знака * в набора от заместващи знаци.
Регулярният израз, съответстващ на * .jpg, ще изглежда така: * \. Jpg. Например последователностите с заместващи знаци ez * .pp съвпадат с два еквивалентни регулярни израза, ez. * \. Pp и ez. * \. (Cpp | hpp).
Примери за регулярни изрази
Имейл във формата [защитен с имейл]
+(\.+)*@+(\.+)+
Имейл във формат „Иван Иванов
("? +"? [\ t] *) + \<+(\.+)*@+(\.+)+\>
Проверка на уеб протокола в URL (http: //, ftp: // или https: //)
+://
Някои C / C ++ команди и директиви:
^ # включва [\ t] + [<"][^>"] + [">] - директива за включване
//.+$ - коментар на един ред
/ \ * [^ *] * \ * / - коментар на няколко реда
-? + \. + - число с плаваща запетая
0x + е шестнадесетично число.
И ето, например, програмата за намиране на думата крава:
grep -E "крава | vache" *> / dev / null && echo "Намерена крава"Тук опцията -E се използва за активиране на разширена поддръжка на синтаксис на регулярни изрази.
Този текст е базиран на статия на Ян Борсоди от файла HOWTO-regexps.htm
За да обработвате напълно текстове в bash скриптове, използвайки sed и awk, просто трябва да разберете регулярните изрази. Реализациите на този най-полезен инструмент могат да бъдат намерени буквално навсякъде и въпреки че всички регулярни изрази са подредени по подобен начин, базирани на едни и същи идеи, работата с тях има определени особености в различни среди. Тук ще говорим за регулярни изрази, които са подходящи за използване в скриптове на командния ред на Linux.
Този материал е предназначен да бъде въведение в регулярните изрази за тези, които може би изобщо не знаят какво представляват. Така че нека започнем от самото начало.
Какво представляват регулярните изрази
При мнозина, когато за първи път видят регулярни изрази, веднага възниква мисълта, че са пред безсмислена смесица от знаци. Но това, разбира се, далеч не е така. Разгледайте този регулярен израз например
Според нас дори абсолютен начинаещ веднага ще разбере как работи и защо ви е нужен :) Ако не разбирате съвсем, просто прочетете и всичко ще си дойде на мястото.
Регулярният израз е модел, който програми като sed или awk използват за филтриране на текст. Шаблоните използват обикновени ASCII знаци, които представляват себе си, и така наречените метасимволи, които играят специална роля, например, позволявайки ви да се позовавате на определени групи знаци.
Типове регулярни изрази
Реализациите на регулярни изрази в различни среди, като езици за програмиране като Java, Perl и Python, и инструменти на Linux като sed, awk и grep, имат определени странности. Тези функции зависят от така наречените машини за регулярни изрази, които интерпретират шаблони.Има два механизма за регулярни изрази в Linux:
- Машина, която поддържа стандарта POSIX Basic Regular Expression (BRE).
- Машина, която поддържа стандарта POSIX Extended Regular Expression (ERE).
Стандартът POSIX ERE често се прилага в езици за програмиране. Позволява ви да използвате много инструменти при проектирането на регулярни изрази. Например, това могат да бъдат специални поредици от знаци за често използвани модели, като например търсене в текста за отделни думи или набори от числа. Awk поддържа стандарта ERE.
Има много начини за разработване на регулярни изрази, в зависимост както от мнението на програмиста, така и от характеристиките на двигателя, за който са създадени. Не е лесно да се напишат общи регулярни изрази, които всеки двигател може да разбере. Затова ще се съсредоточим върху най-често използваните регулярни изрази и ще разгледаме как са имплементирани за sed и awk.
POSIX BRE регулярни изрази
Може би най-простият модел BRE е регулярен израз за намиране на точното появяване на поредица от знаци в текста. Ето как изглежда sed и awk търсенето на низ:$ echo "Това е тест" | sed -n "/ test / p" $ echo "Това е тест" | awk "/ test / (отпечатайте $ 0)"
Търсене на текст по шаблон в sed
Намиране на текст по шаблон в awk
Можете да забележите, че търсенето на даден шаблон се извършва без да се отчита точното местоположение на текста в низа. Освен това броят на събитията няма значение. След като регулярният израз намери посочения текст навсякъде в низа, низът се счита за валиден и се предава за по-нататъшна обработка.
Когато работите с регулярни изрази, имайте предвид, че те са чувствителни към главни букви:
$ echo "Това е тест" | awk "/ Тест / (отпечатване $ 0)" $ echo "Това е тест" | awk "/ тест / (отпечатайте $ 0)"
Регулярните изрази са чувствителни към главни букви
Първият регулярен израз не съвпада, тъй като думата "тест", започваща с главна буква, не се среща в текста. Вторият, конфигуриран да търси дума с главни букви, намери съвпадащ низ в потока.
В регулярните изрази можете да използвате не само букви, но и интервали и числа:
$ echo "Това отново е тест 2" | awk "/ тест 2 / (отпечатайте $ 0)"
Намерете част от текст, съдържаща интервали и числа
Пространствата се третират като редовни знаци от механизма за регулярни изрази.
Специални символи
Има няколко неща, които трябва да имате предвид, когато използвате различни знаци в регулярни изрази. И така, има някои специални знаци или метазнаци, които изискват специален подход за използване в шаблон. Ето ги и тях: .*^${}\+?|()
Ако един от тях е необходим в шаблона, той ще трябва да бъде екраниран с обратна наклонена черта (обратна наклонена черта) - \.
Например, ако трябва да намерите знак за долар в текста, той трябва да бъде включен в шаблона, предшестван от escape-символ. Да приемем, че имате файл, наречен myfile със следния текст:
В джоба ми има 10 $
Знакът на долара може да бъде открит с помощта на модел като този:
$ awk "/ \ $ / (отпечатайте $ 0)" myfile
Използване на специален символ в шаблон
В допълнение, обратната наклонена черта също е специален знак, така че ако искате да го използвате в шаблон, ще трябва също да го избягате. Изглежда като две наклонени черти напред:
$ echo "\ е специален знак" | awk "/ \\ / (отпечатайте $ 0)"
Обратна наклонена черта избяга
Въпреки че наклонената черта не е включена в горния списък със специални знаци, опитът да се използва в регулярен израз, написан за sed или awk, ще доведе до грешка:
$ echo "3/2" | awk "/// (отпечатайте $ 0)"
Неправилно използване на наклонена черта в шаблон
Ако имате нужда от него, трябва също да го прегледате:
$ echo "3/2" | awk "/ \ // (отпечатване $ 0)"
Наклонена черта напред
Котва символи
Има два специални знака за закотвяне на шаблон към началото или края на текстов низ. Символът на корицата - ^ ви позволява да опишете поредици от знаци, които се появяват в началото на текстовите редове. Ако моделът, който търсите, се появи на друго място в низа, регулярният израз няма да отговори на него. Използването на този символ изглежда така:$ echo "добре дошли в уебсайта на likegeeks" | awk "/ ^ likegeeks / (печат $ 0)" $ echo "сайт на likegeeks" | awk "/ ^ likegeeks / (отпечатайте $ 0)"
Намиране на шаблон в началото на ред
Символът ^ е предназначен за търсене на шаблон в началото на низ, като случайът също се взема предвид. Нека видим как това се отразява на обработката на текстов файл:
$ awk "/ ^ това / (отпечатайте $ 0)" myfile
Търсене на шаблон в началото на ред в текст от файл
Със sed, ако поставите капачка някъде вътре в шаблона, тя ще се третира като всеки друг редовен знак:
$ echo "Това ^ е тест" | sed -n "/ s ^ / p"
Не покривайте в началото на шаблона в sed
В awk, когато се използва същия модел, даденият символ трябва да бъде екраниран:
$ echo "Това ^ е тест" | awk "/ s \ ^ / (отпечатайте $ 0)"
Корица не в началото на шаблон в awk
Разбрахме търсенето на текстови фрагменти, разположени в началото на реда. Ами ако искате да намерите нещо в края на реда?
Знакът за долар - $, който е символът за котва за края на реда, ще ни помогне за това:
$ echo "Това е тест" | awk "/ тест $ / (отпечатайте $ 0)"
Намиране на текст в края на ред
И двата символа на котва могат да се използват в един и същ модел. Нека обработим файла myfile, чието съдържание е показано на фигурата по-долу, като използваме следния регулярен израз:
$ awk "/ ^ това е тест $ / (отпечатайте $ 0)" myfile
Шаблон, който използва специални знаци за началото и края на ред
Както можете да видите, шаблонът реагира само на низ, който напълно съответства на определената последователност от знаци и тяхното местоположение.
Ето как да филтрирате празни редове с помощта на котвени знаци:
$ awk "! / ^ $ / (отпечатайте $ 0)" myfile
В този шаблон използвах символа за отрицание, удивителния знак -! ... Този шаблон търси редове, които не съдържат нищо между началото и края на реда, а удивителният знак отпечатва само редове, които не съвпадат с шаблона.
Символ на точка
Точката се използва за търсене на всеки единичен знак, с изключение на символа за преместване на ред. Нека предадем файла myfile на такъв регулярен израз, чието съдържание е дадено по-долу:$ awk "/.st/(print $ 0)" myfile
Използване на точка в регулярни изрази
Както можете да видите от показаните данни, само първите два реда от файла съответстват на шаблона, тъй като съдържат последователността от знаци "st", предшествана от още един знак, докато третият ред не съдържа подходяща последователност и в четвъртия е, но е в самото начало на реда.
Класове по персонажи
Точката съответства на всеки единичен знак, но какво ще стане, ако трябва да сте по-гъвкави в ограничаването на набора от знаци, които търсите? В подобна ситуация можете да използвате класове на знаци.Благодарение на този подход можете да организирате търсене на всеки герой от даден набор. Квадратните скоби се използват за описване на клас символи -:
$ awk "/ th / (отпечатайте $ 0)" myfile
Описание на класа на символите с регулярни изрази
Тук търсим поредица от знаци "th", предшествани от знака "o" или знака "i".
Класовете са полезни, когато търсите думи, които могат да започват както с главни, така и с малки букви:
$ echo "това е тест" | awk "/ неговият е тест / (отпечатайте $ 0)" $ echo "Това е тест" | awk "/ негово е тест / (отпечатайте $ 0)"
Намерете думи, които могат да започват с малка или главна буква
Класовете на знаци не се ограничават до букви. Тук могат да се използват и други символи. Невъзможно е да се каже предварително в каква ситуация ще са необходими класовете - всичко зависи от проблема, който се решава.
Отрицание на класовете символи
Класовете на символи могат да се използват и за решаване на обратния проблем, описан по-горе. А именно, вместо да търсите символи, включени в класа, можете да организирате търсене на всичко, което не е включено в класа. За да се постигне това поведение на регулярен израз, ^ трябва да се постави пред списъка със знаци на класа. Изглежда така:$ awk "/ [^ oi] th / (отпечатайте $ 0)" myfile
Намерете герои извън клас
В този случай ще бъдат намерени поредици от знаци "th", пред които няма нито "o", нито "i".
Диапазони от знаци
В класовете от знаци можете да опишете диапазони от знаци с помощта на тире:$ awk "/ st / (отпечатайте $ 0)" myfile
Описване на набор от знаци в клас символи
В този пример регулярният израз отговаря на последователността от знаци "st", предшествана от всеки знак, разположен по азбучен ред между знаците "e" и "p".
Диапазоните могат да бъдат създадени и от числа:
$ echo "123" | awk "//" $ echo "12a" | awk "//"
Редовен израз за намиране на произволни три числа
Няколко диапазона могат да бъдат включени в клас символи:
$ awk "/ st / (отпечатайте $ 0)" myfile
Клас на многообхватни знаци
Този регулярен израз ще съответства на всички низове, предшествани от знаци в диапазоните a-f и m-z.
Класове със специални знаци
BRE има специални символни класове, които можете да използвате, когато пишете регулярни изрази:- [[: alpha:]] - съответства на всеки алфавитен знак с главни или малки букви.
- [[: alnum:]] - съответства на всеки буквено-цифров знак, а именно знаци в диапазоните 0-9, A-Z, a-z.
- [[: blank:]] - съответства на интервал и раздел.
- [[: цифра:]] - всеки цифров знак от 0 до 9.
- [[: upper:]] - главни букви на азбуката - A-Z.
- [[: low:]] - малки букви - a-z.
- [[: print:]] - съответства на всеки символ за печат.
- [[: punct:]] - съвпада с препинателните знаци.
- [[: интервал:]] - символи за интервал, по-специално - интервал, табулация, NL, FF, VT, CR символи.
$ echo "abc" | awk "/ [[: alpha:]] / (отпечатване $ 0)" $ echo "abc" | awk "/ [[: цифра:]] / (отпечатване $ 0)" $ echo "abc123" | awk "/ [[: цифра:]] / (отпечатайте $ 0)"
Класове специални знаци в регулярни изрази
Символ на звезда
Ако поставите звездичка след символ в шаблона, това означава, че регулярният израз ще работи, ако знакът се появи в низа произволен брой пъти - включително ситуацията, когато в низа няма символ.$ echo "тест" | awk "/ tes * t / (отпечатване $ 0)" $ echo "tessst" | awk "/ tes * t / (отпечатайте $ 0)"
Използване на знака * в регулярни изрази
Този заместващ знак обикновено се използва за работа с думи, които постоянно съдържат печатни грешки, или за думи, които могат да бъдат изписани по различен начин:
$ echo "Харесвам зелен цвят" | awk "/ colou * r / (печат $ 0)" $ echo "Харесвам зелен цвят" | awk "/ colou * r / (отпечатайте $ 0)"
Потърсете дума, която има различно изписване
В този пример едно и също редовно изражение реагира както на думата „цвят”, така и на думата „цвят”. Това се дължи на факта, че символът "u", след който има звездичка, може да отсъства или да се появи няколко пъти подред.
Друга полезна функция, която следва от особеностите на символа звездичка, е комбинирането му с точка. Тази комбинация позволява на регулярния израз да отговаря на произволен брой всякакви знаци:
$ awk "/this.*test/(print $0)" myfile
Шаблон, който отговаря на произволен брой всякакви знаци
В този случай няма значение колко и какви знаци има между думите „това“ и „тест“.
Звездичката може да се използва и с класове знаци:
$ echo "st" | awk "/ s * t / (отпечатване $ 0)" $ echo "sat" | awk "/ s * t / (отпечатване $ 0)" $ echo "set" | awk "/ s * t / (отпечатайте $ 0)"
Използване на звездичката с класове знаци
И в трите примера регулярният израз работи, защото звездичката след класа на знаците означава, че ако се намерят произволен брой символи "a" или "e" или ако не могат да бъдат намерени, низът ще съответства на посочения шаблон.
POSIX ERE регулярни изрази
Шаблоните POSIX ERE, които някои помощни програми на Linux поддържат, може да съдържат допълнителни знаци. Както вече споменахме, awk поддържа този стандарт, но sed не.Тук ще разгледаме най-често използваните символи в ERE шаблоните, които ще ви бъдат полезни, когато създавате свои собствени регулярни изрази.
▍Въпросителен знак
Въпросителният знак показва, че предходният знак може да се появи веднъж в текста или изобщо да не се появи. Този герой е един от повтарящите се метазнаци. Ето няколко примера:$ echo "tet" | awk "/ tes? t / (отпечатайте $ 0)" $ echo "тест" | awk "/ tes? t / (отпечатване $ 0)" $ echo "testst" | awk "/ tes? t / (отпечатайте $ 0)"
Въпросителен знак в регулярни изрази
Както можете да видите, в третия случай буквата "s" се среща два пъти, така че регулярният израз не реагира на думата "testst".
Въпросителният знак може да се използва и с класове знаци:
$ echo "tst" | awk "/ t? st / (отпечатване $ 0)" $ echo "тест" | awk "/ t? st / (отпечатване $ 0)" $ echo "tast" | awk "/ t? st / (отпечатване $ 0)" $ echo "taest" | awk "/ t? st / (печат $ 0)" $ echo "тест" | awk "/ t? st / (отпечатайте $ 0)"
Въпросителни и знаци класове
Ако в низа няма знаци от класа или един от тях се появи веднъж, регулярният израз се задейства, но веднага щом в думата се появят два знака, системата вече не намира съвпадение за шаблона в текста.
▍Символ плюс
Символът плюс в шаблона показва, че регулярният израз ще намери желания, ако предходният знак се появи един или повече пъти в текста. В същото време такава конструкция няма да реагира на липсата на символ:$ echo "тест" | awk "/ te + st / (отпечатване $ 0)" $ echo "тест" | awk "/ te + st / (отпечатване $ 0)" $ echo "tst" | awk "/ te + st / (отпечатайте $ 0)"
Плюс влизане в регулярни изрази
В този пример, ако няма „e“ в една дума, механизмът за регулярни изрази няма да намери съвпадение за шаблона в текста. Символът плюс работи и с класове знаци, което го прави да изглежда като звездичка и въпросителен знак:
$ echo "tst" | awk "/ t + st / (отпечатване $ 0)" $ echo "тест" | awk "/ t + st / (отпечатване $ 0)" $ echo "тест" | awk "/ t + st / (отпечатване $ 0)" $ echo "teeast" | awk "/ t + st / (отпечатайте $ 0)"
Плюс класове със знаци и знаци
В този случай, ако низът съдържа символ от класа, текстът ще се счита за съответстващ на шаблона.
▍Скоби за знаци
Къдравите скоби, които можете да използвате в шаблоните на ERE, са подобни на символите, обсъдени по-горе, но ви позволяват по-точно да посочите необходимия брой поява на символа, който ги предхожда. Ограничението може да бъде определено в два формата:- n е число, което определя точния брой събития, които да търсите
- n, m - две числа, които се тълкуват по следния начин: "най-малко n пъти, но не повече от m".
$ echo "tst" | awk "/ te (1) st / (отпечатайте $ 0)" $ echo "тест" | awk "/ te (1) st / (отпечатайте $ 0)"
Къдрави скоби в шаблони, намерете точен брой събития
В по-старите версии на awk трябваше да използвате превключвателя на командния ред --re-interval, за да може програмата да разпознава интервали в регулярните изрази, но в по-новите версии това не е необходимо.
$ echo "tst" | awk "/ te (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ te (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ te (1,2) st / (отпечатване $ 0)" $ echo "teeest" | awk "/ te (1,2) st / (отпечатайте $ 0)"
Разстоянието, определено в къдрави скоби
В този пример символът "e" трябва да се появи на реда 1 или 2 пъти, след което регулярният израз ще реагира на текста.
Къдравите скоби могат да се използват и с класове знаци. Ето принципите, които вече са ви познати:
$ echo "tst" | awk "/ t (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ t (1,2) st / (отпечатване $ 0)" $ echo "тест" | awk "/ t (1,2) st / (отпечатване $ 0)" $ echo "teeast" | awk "/ t (1,2) st / (отпечатайте $ 0)"
Къдрави скоби и класове знаци
Шаблонът ще реагира на текста, ако съдържа знака "a" или знака "e" веднъж или два пъти.
▍ Булева или символ
Символ | - вертикална лента, означава логическо "или" в регулярните изрази. Когато обработва регулярен израз, съдържащ няколко фрагмента, разделени с такъв знак, машината ще счита анализирания текст за подходящ, ако съвпада с някой от фрагментите. Ето един пример:$ echo "Това е тест" | awk "/ тест | изпит / (отпечатване $ 0)" $ echo "Това е изпит" | awk "/ тест | изпит / (отпечатване $ 0)" $ echo "Това е нещо друго" | awk "/ тест | изпит / (отпечатване $ 0)"
Булев "или" в регулярни изрази
В този пример регулярният израз е конфигуриран да търси в текста думите "тест" или "изпит". Имайте предвид, че между фрагментите на шаблона и разделящите | не трябва да има интервали.
Фрагменти на регулярна експресия могат да бъдат групирани с помощта на скоби. Ако групирате определена последователност от знаци, тя ще бъде възприета от системата като обикновен символ. Тоест, например, ще бъде възможно да се прилагат метасимволи за повторение към него. Ето как изглежда:$ echo "Харесвам" | awk "/ Харесвам (Geeks)? / (отпечатайте $ 0)" $ echo "LikeGeeks" | awk "/ Харесвам (Гийкове)? / (отпечатайте $ 0)"
Групиране на фрагменти с регулярни изрази
В тези примери думата "Geeks" е затворена в скоби, последвана от въпросителен знак. Припомнете си, че въпросителният знак означава "0 или 1 повторение", в резултат на което регулярният израз ще отговори както на низа "Like", така и на низа "LikeGeeks".
Практически примери
След като разгледахме основите на регулярните изрази, е време да направим нещо полезно с тях.▍Преброяване на броя на файловете
Нека напишем bash скрипт, който брои файловете в директориите, които са записани в променливата на средата PATH. За да направите това, първо ще трябва да генерирате списък с пътища към директории. Нека го направим със sed, като заменим двоеточия с интервали:$ ехо $ ПЪТ | sed "s /: / / g"
Командата replace поддържа регулярни изрази като шаблони за търсене на текст. В случая всичко е изключително просто, търсим символ на двоеточие, но никой не си прави труда да използва нещо друго тук - всичко зависи от конкретната задача.
Сега трябва да преминете през получения списък в цикъл и да извършите действията, необходими за преброяване на броя на файловете там. Общата схема на скрипта ще бъде както следва:
Mypath = $ (echo $ PATH | sed "s /: / / g") за директория в $ mypath do done
Сега нека напишем пълния текст на скрипта, като използваме командата ls, за да получим информация за броя на файловете във всяка от директориите:
#! / bin / bash mypath = $ (echo $ PATH | sed "s /: / / g") count = 0 за директория в $ mypath do check = $ (ls $ директория) за елемент в $ check do count = $ [$ count + 1] done echo "$ директория - $ count" count = 0 готово
Когато стартирате скрипта, може да се окаже, че някои директории от PATH не съществуват, но това няма да му попречи да брои файлове в съществуващи директории.
Преброяване на файлове
Основната стойност на този пример се крие във факта, че с помощта на същия подход можете да решите много по-сложни проблеми. Кое точно зависи от вашите нужди.
▍Проверка на имейл адреси
Има уебсайтове с огромни колекции от регулярни изрази, които ви позволяват да проверявате имейл адреси, телефонни номера и т.н. Едно е обаче да вземеш готов, а съвсем друго да създадеш нещо сам. Така че нека напишем регулярен израз за валидиране на имейл адреси. Нека започнем с анализ на първоначалните данни. Ето например определен адрес:[защитен с имейл]
Потребителското име, потребителското име може да бъде буквено-цифрено и някои други знаци. А именно, това е точка, тире, долна черта, знак плюс. Потребителското име е последвано от знака @.
Въоръжени с това знание, нека започнем да сглобяваме регулярния израз от лявата му страна, който служи за валидиране на потребителското име. Ето какво получихме:
^(+)@
Този регулярен израз може да се чете по следния начин: "В началото на ред трябва да има поне един знак от тези в групата, посочена в квадратни скоби, а след това трябва да има знак @."
Сега е опашката за име на хост - име на хост. Тук важат същите правила като за потребителското име, така че шаблонът за него ще изглежда така:
(+)
Името на домейн от най-високо ниво е предмет на специални правила. Може да има само азбучни знаци, от които трябва да има поне два (например такива домейни обикновено съдържат код на държавата) и не повече от пет. Всичко това означава, че шаблонът за проверка на последната част от адреса ще бъде така:
\.({2,5})$
Можете да го прочетете така: "Първо трябва да има точка, след това - от 2 до 5 азбучни знака и след това редът свършва."
След като подготвихме шаблоните за отделните части на регулярния израз, нека ги съберем заедно:
^(+)@(+)\.({2,5})$
Сега остава само да тестваме какво се е случило:
$ ехо " [защитен с имейл]"| awk" /^(+)@(+)\.((2,5))$/(печат $0) "$ ехо" [защитен с имейл]"| awk" /^(+)@(+)\.((2,5))$/(печат $0) "
Проверка на имейл адрес с помощта на регулярни изрази
Фактът, че текстът, предаден на awk, се отпечатва на екрана, означава, че системата е разпознала имейл адреса в него.
Резултати
Ако регулярният израз за валидиране на имейл адреси, който срещнахте в самото начало на статията, изглеждаше напълно неразбираем тогава, ние се надяваме, че сега вече не изглежда като безсмислен набор от знаци. Ако това е вярно, значи този материал е изпълнил целта си. Всъщност регулярните изрази са тема, с която можете да се занимавате цял живот, но дори малкото, което обсъдихме, вече може да ви помогне при писането на скриптове, които обработват текстове доста напреднало.В тази серия от статии обикновено показвахме много прости примери за bash скриптове, които се състоят буквално от няколко реда. Следващия път нека погледнем нещо по-голямо.
Уважаеми читатели! Използвате ли регулярни изрази, когато обработвате текст в скриптове на командния ред?