Pytonormär utmärkt språk programmering att implementera av olika anledningar. För det första, Pytonorm har en tydlig syntax. För det andra, i Pytonorm Det är väldigt lätt att manipulera text. Pytonorm Används av ett stort antal människor och organisationer runt om i världen, det är utvecklande och väldokumenterat. Språket är plattformsoberoende och kan användas helt gratis.
Körbar pseudokod
Intuitiv syntax Pytonorm kallas ofta körbar pseudokod. Installation Pytonorm redan aktiverad som standard typer på hög nivå data, såsom listor, tupler, ordböcker, uppsättningar, sekvenser och så vidare, som inte längre behöver implementeras av användaren. Dessa datatyper på hög nivå gör det enkelt att implementera abstrakta koncept. Pytonorm låter dig programmera i vilken stil som helst som är bekant för dig: objektorienterad, procedurell, funktionell och så vidare.
I Pytonorm Text är lätt att bearbeta och manipulera, vilket gör den idealisk för bearbetning av icke-numeriska data. Det finns ett antal bibliotek att använda Pytonorm för att komma åt webbsidor, och intuitiv texthantering gör det enkelt att hämta data från HTML-koda.
Pytonorm populär
Programmeringsspråk Pytonorm populära och många tillgängliga exempel kod gör att lära sig det enkelt och ganska snabbt. För det andra innebär popularitet att det finns många moduler tillgängliga för olika applikationer.
Pytonormär ett populärt programmeringsspråk i såväl vetenskapliga som finansiella kretsar. Ett antal bibliotek för vetenskaplig beräkning som t.ex SciPy Och NumPy låter dig utföra operationer på vektorer och matriser. Det gör också koden ännu mer läsbar och låter dig skriva kod som ser ut som linjära algebrauttryck. Dessutom vetenskapliga bibliotek SciPy Och NumPy kompilerad med lågnivåspråk ( MED Och Fortran), vilket gör beräkningar mycket snabbare när du använder dessa verktyg.
Vetenskapliga instrument Pytonorm fungerar utmärkt tillsammans med grafiskt verktyg berättigad Matplotlib. Matplotlib kan bygga tvådimensionell och 3D-grafik och kan hantera de flesta typer av konstruktioner som vanligtvis används i det vetenskapliga samfundet.
Pytonorm Den har också ett interaktivt skal som låter dig se och kontrollera delar av programmet som utvecklas.
Ny modul Pytonorm, under namnet Pylab, strävar efter att kombinera möjligheter NumPy, SciPy, Och Matplotlib i en miljö och installation. Dagens paket Pylab Det är fortfarande under utveckling, men det har en stor framtid.
Fördelar och nackdelar Pytonorm
Människor använder olika programmeringsspråk. Men för många är ett programmeringsspråk helt enkelt ett verktyg för att lösa ett problem. Pytonormär ett språk högsta nivån, vilket gör att du kan lägga mer tid på att förstå data och mindre tid på att tänka på hur de ska presenteras för datorn.
Den enda verkliga nackdelen Pytonormär att den inte kör programkod lika snabbt som t.ex. Java eller C. Anledningen till detta är att Pytonorm- tolkat språk. Det är dock möjligt att anropa kompilerad C-program från Pytonorm. Detta gör att du kan använda det bästa av olika språk programmera och utveckla programmet steg för steg. Om du har experimenterat med en idé med hjälp av Pytonorm och bestämde att det är precis vad du vill implementera i färdigt system, då blir det lätt att implementera denna övergång från prototyp till arbetsprogram. Om programmet är byggt enligt modulär princip, då kan du först se till att det du behöver fungerar i koden som skrivits in Pytonorm, och sedan, för att förbättra hastigheten på kodexekveringen, skriv om viktiga avsnitt i språket C. Bibliotek C++ Boost gör detta enkelt att göra. Andra verktyg som t.ex Cython Och PyPy kan du öka programmets prestanda jämfört med normalt Pytonorm.
Om själva idén som implementeras av programmet är "dålig", är det bättre att förstå detta genom att spendera ett minimum av dyrbar tid på att skriva kod. Om idén fungerar kan du alltid förbättra prestandan genom att skriva om delvis kritiska delar av programkoden.
I senaste åren ett stort antal utvecklare, inklusive de med akademisk examen, arbetade för att förbättra prestandan för språket och dess individuella paket. Därför är det inte ett faktum att du kommer att skriva kod i C, som kommer att fungera snabbare än vad som redan finns tillgängligt i Pytonorm.
Vilken version av Python ska jag använda?
För närvarande används de flitigt olika versioner detta, nämligen 2.x och 3.x. Den tredje versionen är fortfarande under aktiv utveckling, de flesta av de olika biblioteken fungerar garanterat på den andra versionen, så jag använder den andra versionen, nämligen 2.7.8, vilket jag råder dig att göra. Det finns inga grundläggande ändringar i den 3:e versionen av detta programmeringsspråk, så din kod, med minimala ändringar i framtiden, om nödvändigt, kan överföras för användning med den tredje versionen.
För att installera, gå till den officiella webbplatsen: www.python.org/downloads/
välj ditt operativsystem och ladda ner installationsprogrammet. Jag kommer inte att uppehålla mig i installationsfrågan i detalj. Sökmotorer hjälper dig enkelt med detta.
Jag är på Mac OS installerade versionen för mig själv Pytonorm skiljer sig från den som installerades på systemet och paket via pakethanteraren Anakonda(det finns förresten även installationsalternativ för Windows Och Linux).
Under Windows, De säger, Pytonorm spelas med en tamburin, men jag har inte provat det själv, jag kommer inte att ljuga.
NumPy
![]()
NumPyär huvudpaketet för vetenskaplig beräkning i Pytonorm. NumPyär ett programmeringsspråkstillägg Pytonorm, som lägger till stöd för stora flerdimensionella arrayer och matriser, tillsammans med ett stort bibliotek av högnivå matematiska funktioner att arbeta med dessa arrayer. Företrädare NumPy, plastpåse Numerisk, skapades ursprungligen av Jim Haganin med bidrag från ett antal andra utvecklare. 2005 skapade Travis Oliphant NumPy genom att införliva funktioner i ett konkurrerande paket Numarray V Numerisk gör omfattande förändringar.
För installation i terminalen Linux do:
sudo apt-get uppdatering sudo apt-get installera python-numpy
sudo apt - få uppdatering sudo apt - få installera python - numpy |
En enkel kod som använder NumPy som bildar en endimensionell vektor med 12 tal från 1 till 12 och omvandlar den till en tredimensionell matris:
från numpy import * a = arange(12) a = a.reshape(3,2,2) print a
från numpy import * a = intervall (12) a = a. omforma (3 , 2 , 2 ) skriva ut a |
Resultatet på min dator ser ut så här:

Generellt sett är koden i terminalen Pytonorm Jag gör det inte så ofta, förutom att räkna ut något snabbt, som på en miniräknare. Jag gillar att jobba i IDE PyCharm. Så här ser dess gränssnitt ut när du kör ovanstående kod

SciPy
![]() SciPyär ett bibliotek med öppen källkod för vetenskaplig beräkning. För jobb SciPy måste vara förinstallerad NumPy, vilket ger bekväma och snabba operationer med flerdimensionella arrayer. Bibliotek SciPy fungerar med arrayer NumPy, och tillhandahåller många bekväma och effektiva beräkningsprocedurer, till exempel för numerisk integration och optimering. NumPy Och SciPy enkel att använda men ändå kraftfull nog att utföra en mängd olika vetenskapliga och tekniska beräkningar.
SciPyär ett bibliotek med öppen källkod för vetenskaplig beräkning. För jobb SciPy måste vara förinstallerad NumPy, vilket ger bekväma och snabba operationer med flerdimensionella arrayer. Bibliotek SciPy fungerar med arrayer NumPy, och tillhandahåller många bekväma och effektiva beräkningsprocedurer, till exempel för numerisk integration och optimering. NumPy Och SciPy enkel att använda men ändå kraftfull nog att utföra en mängd olika vetenskapliga och tekniska beräkningar.
För att installera biblioteket SciPy V Linux, kör i terminalen:
sudo apt-get uppdatering sudo apt-get installera python-scipy
sudo apt - få uppdatering sudo apt - få installera python - scipy |
Jag kommer att ge ett exempel på kod för att hitta extremumet för en funktion. Resultatet visas redan när du använder paketet matplotlib, diskuteras nedan.
importera numpy som np från scipy import special, optimera importera matplotlib.pyplot som plt f = lambda x: -special.jv(3, x) sol = optimize.minimize(f, 1.0) x = np.linspace(0, 10, 5000) plt.plot(x, special.jv(3, x), "-", sol.x, -sol.fun, "o") plt.show()
importera numpy som np från scipy import special , optimera f = lambda x: - special. jv(3, x) sol = optimera . minimera(f, 1,0) x = np. linspace(0, 10, 5000) plt. plot (x , special . jv (3 , x ) , "-" , sol . x , - sol . fun , "o") plt. show() |
Resultatet är en graf med ytterpunkten markerad:

Bara för skojs skull, försök att implementera samma sak i språket C och jämför antalet kodrader som krävs för att få resultatet. Hur många rader fick du? Ett hundra? Fem hundra? Tvåtusen?
Pandas
![]() pandorär ett paket Pytonorm, designad för att tillhandahålla snabba, flexibla och uttrycksfulla datastrukturer som gör det enkelt att arbeta med "relativ" eller "märkt" data på ett enkelt och intuitivt sätt. pandor strävar efter att bli den primära byggstenen på hög nivå för dirigering Pytonorm praktisk analys av data som erhållits från den verkliga världen. Dessutom påstår sig detta paket vara det mest kraftfulla och flexibla öppen källa ett verktyg för dataanalys/bearbetning, tillgängligt i alla programmeringsspråk.
pandorär ett paket Pytonorm, designad för att tillhandahålla snabba, flexibla och uttrycksfulla datastrukturer som gör det enkelt att arbeta med "relativ" eller "märkt" data på ett enkelt och intuitivt sätt. pandor strävar efter att bli den primära byggstenen på hög nivå för dirigering Pytonorm praktisk analys av data som erhållits från den verkliga världen. Dessutom påstår sig detta paket vara det mest kraftfulla och flexibla öppen källa ett verktyg för dataanalys/bearbetning, tillgängligt i alla programmeringsspråk.
Pandas väl lämpad för att arbeta med olika typer av data:
- Tabelldata med kolumner olika typer som i tabeller SQL eller Excel.
- Ordnade och oordnade (inte nödvändigtvis konstant frekvens) tidsseriedata.
- Godtyckliga matrisdata (homogena eller heterogena) med märkta rader och kolumner.
- Alla andra former av observations- eller statistiska datauppsättningar. Data kräver faktiskt ingen etikett för att kunna placeras i en datastruktur pandor.
För att installera paketet pandor kör i terminalen Linux:
sudo apt-get uppdatering sudo apt-get installera python-pandas
sudo apt - få uppdatering sudo apt - få installera python - pandor |
Enkel kod som omvandlar en endimensionell array till en datastruktur pandor:
importera pandor som pd importera numpy som np värden = np.array() ser = pd.Series(values) print ser
importera pandor som pd importera numpy som np värden = np. array ([ 2.0 , 1.0 , 5.0 , 0.97 , 3.0 , 10.0 , 0.0599 , 8.0 ] ) ser = pd. Serier (värden) print ser |
Resultatet blir:

matplotlib
![]()
matplotlibär ett grafiskt plottningsbibliotek för ett programmeringsspråk Pytonorm och dess tillägg till beräkningsmatematik NumPy. Biblioteket tillhandahåller ett objektorienterat API för att bädda in grafer i applikationer med hjälp av verktyg GUI allmänt ändamål som t.ex WxPython, Qt, eller GTK+. Det finns också en procedur pylab-gränssnitt påminner MATLAB. SciPy använder matplotlib.
För att installera biblioteket matpoltlib V Linux kör följande kommandon:
sudo apt-get uppdatering sudo apt-get installera python-matplotlib
sudo apt - få uppdatering sudo apt - få installera python - matplotlib |
Exempelkod som använder biblioteket matplotlib för att skapa histogram:
importera numpy som np importera matplotlib.mlab som mlab importera matplotlib.pyplot som plt # exempeldata mu = 100 # distributionsmedel sigma = 15 # standardavvikelse för distribution x = mu + sigma * np.random.randn(10000) num_bins = 50 # histogrammet för data n, bins, patches = plt.hist(x, num_bins, normed=1, facecolor="green", alpha=0.5) # lägg till en "bästa passform"-rad y = mlab.normpdf(bins , mu, sigma) plt.plot(bins, y, "r--") plt.xlabel("Smarts") plt.ylabel("Probability") plt.title(r"IQ-histogram: $\mu=100 $, $\sigma=15$") # Justera avstånd för att förhindra klippning av ylabel plt.subplots_adjust(left=0.15) plt.show()
importera numpy som np importera matplotlib. mlab som mlab importera matplotlib. pyplot som plt # exempeldata mu = 100 # distributionsmedelvärde sigma = 15 # standardavvikelse för distribution x = mu + sigma * np. slumpmässig. randn (10 000) antal_bins = 50 # histogrammet för data n, papperskorgar, lappar = plt. hist (x , num_bins , normed = 1 , facecolor = "grön" , alfa = 0,5 ) # lägg till en "bästa passform"-rad y = mlab. normpdf (bins, mu, sigma) plt. plot(bins, y, "r--") plt. xlabel("Smarts") plt. ylabel("Sannolikhet") plt. titel (r "IQ-histogram: $\mu=100$, $\sigma=15$") # Justera mellanrum för att förhindra att etiketten klipps av plt. subplots_adjust (vänster = 0,15 ) plt. show() |
Resultatet är:
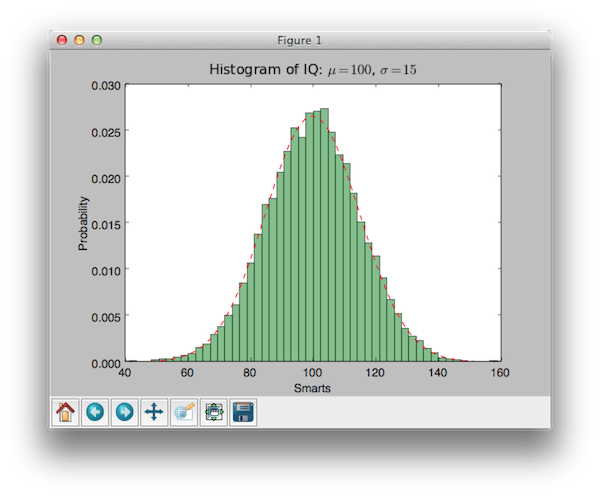
Jag tycker den är väldigt söt!
är kommandoskal för interaktiv datoranvändning i flera programmeringsspråk, ursprungligen utvecklad för ett programmeringsspråk Pytonorm. låter dig utöka presentationsmöjligheterna, lägger till skalsyntax, autokomplettering och en omfattande kommandohistorik. tillhandahåller för närvarande följande funktioner:
- Kraftfulla interaktiva skal (terminaltyp och baserad på Qt).
- Webbläsarbaserad redigerare med stöd för kod, text, matematiska uttryck, inbäddade grafer och andra presentationsmöjligheter.
- Stöder interaktiv datavisualisering och användning av GUI-verktyg.
- Flexibla, inbyggda tolkar för att arbeta i dina egna projekt.
- Lätt att använda, högpresterande parallella beräkningsverktyg.
IPython webbplats:
För att installera IPython på Linux, kör följande kommandon i terminalen:
sudo apt-get update sudo pip installera ipython
Jag kommer att ge ett exempel på kod som bygger linjär regression för någon uppsättning data som är tillgänglig i paketet scikit-lära:
importera matplotlib.pyplot som plt importera numpy som np från sklearn importera datamängder, linear_model # Ladda diabetesdatauppsättningen diabetes = datasets.load_diabetes() # Använd endast en funktion diabetes_X = diabetes.data[:, np.newaxis] diabetes_X_temp = diabetes_X[: , :, 2] # Dela upp data i tränings-/testset diabetes_X_train = diabetes_X_temp[:-20] diabetes_X_test = diabetes_X_temp[-20:] # Dela upp målen i tränings-/testset diabetes_y_train = diabetes.target[:-20] diabetes_y_test = diabetes.target[-20:] # Skapa linjärt regressionsobjekt regr = linear_model.LinearRegression() # Träna modellen med hjälp av träningsuppsättningarna regr.fit(diabetes_X_train, diabetes_y_train) # Koefficienterna print("Koefficienter: \n", regr .coef_) # Medelkvadratfelet print("Resterande summa av kvadrater: %.2f" % np.mean((regr.predict(diabetes_X_test) - diabetes_y_test) ** 2)) # Förklarad varianspoäng: 1 är perfekt prediktionsutskrift ("Varianspoäng: %.2f" % regr.score(diabetes_X_test, diabetes_y_test)) # Plotoutput plt.scatter(diabetes_X_test, diabetes_y_test, color="black") plt.plot(diabetes_X_test, regr.predict(diabetes_X_test), color ="blå", linewidth=3) plt.xticks()) plt.yticks()) plt.show()
importera matplotlib. pyplot som plt importera numpy som np från sklearn import datamängder , linear_model # Ladda diabetesdatauppsättningen diabetes=dataset. load_diabetes() # Använd endast en funktion diabetes_X = diabetes . data [: , np . nyaxel ] |
Hej alla!
I den här artikeln kommer jag att prata om ett nytt bekvämt sätt att programmera i Python.
Detta är mindre som programmering och mer som att skapa artiklar (rapporter/demonstrationer/forskning/exempel): du kan infoga vanlig förklarande text bland block av Python-kod. Resultatet av att köra koden är inte bara siffror och text (som är fallet med konsolen när standardarbete med Python), men också grafer, diagram, bilder...
Exempel på dokument du kan skapa:
Ser cool ut? Vill du skapa samma dokument? Då är den här artikeln för dig!
Först måste du installera Anaconda-paketet. Vad det är? Detta är en fullt konfigurerad Python tillsammans med en förinstallerad uppsättning av de mest populära modulerna. Anaconda inkluderar även JupyterLab-miljön, där vi kommer att skapa dokument med Python-kod.
Om du redan har Python installerat, avinstallera det först. Detta kan göras via panelen Program och funktioner i kontrollpanelen.
Ladda ner

Ladda ner Anaconda för Python 3.6 (Windows 7 och senare) eller Python 2.7 (Windows XP).
Installationsfilen väger 500+ MB, så det kan ta ganska lång tid att ladda ner.
Installation
Kör den nedladdade filen. Installationsfönstret öppnas. Klicka omedelbart på "Nästa" på de två första sidorna. Därefter kan du välja att installera Anaconda endast för nuvarande användaren dator, eller för alla.

Viktig! I nästa fönster måste du ange sökvägen där Anaconda ska installeras. Välj en sökväg som inte innehåller mappar med mellanslag i namnen (t.ex. Program filer) och innehåller inte icke-engelska Unicode-tecken (till exempel ryska bokstäver)!
Att ignorera dessa regler kan leda till problem när man arbetar med olika moduler!
Personligen skapade jag en Anaconda-mapp precis vid roten av C-enheten och angav följande sökväg:

Det kommer att finnas två bockar i det sista fönstret. Lämna allt som det är.
Slutligen kommer installationen att börja. Det kan ta ~10 minuter. Du kan lugnt dricka te :)

Anaconda Navigator
Efter att ha lyckats installera Anaconda, starta programmet Anaconda Navigator från Start-menyn. När du startar bör du se denna logotyp:
![]()
Då öppnas själva navigatorn. Detta är utgångspunkten för att arbeta med Anaconda.

I den centrala delen av fönstret finns olika program, som ingår i Anaconda-paketet. Några av dem har redan installerats.
Vi kommer främst att använda "jupyterlab": det är i det som vackra dokument skapas.
Den vänstra sidan visar navigatorsektionerna. Som standard är avsnittet "Hem" öppet. I avsnittet "Miljöer" kan du aktivera/inaktivera/ladda in ytterligare Python-moduler med ett bekvämt gränssnitt.
JupyterLab
I avsnittet "Hem" i navigatorn, starta (startknappen) programmet "jupyterlab" (det allra första i listan).
Din standardwebbläsare bör öppnas med JupyterLab-miljön på en separat flik.

Innehållet i mappen C:\Users\ visas till vänster<ИМЯ_ВАШЕЙ_УЧЕТНОЙ_ЗАПИСИ> .
Anteckningsblocksfilen "untitled.ipynb" är öppen till höger. Om det inte finns något till höger kan du skapa en ny, tom anteckningsbok genom att klicka på "+" i det övre vänstra hörnet och välja "Anteckningsbok Python 3":

Anteckningsbok
Det är dags att ta reda på vad anteckningsböcker är.
Vanligtvis skriver vi Python-kod i .py-filer, och sedan kör Python-tolken dem och matar ut data till konsolen. För bekvämt arbete Programmeringsmiljöer (IDE) används ofta med sådana filer. Dessa inkluderar PyCharm, som jag pratade om i artikeln.
Men det finns ett annat tillvägagångssätt. Det består av att skapa anteckningsböcker med tillägget ipynb. Anteckningsblock består av ett stort antal block. Det finns block med vanlig text och det finns block med Python-kod.
Försök att ange lite Python-kod i det första blocket i anteckningsblocket. Till exempel skapar jag en variabel lika med summan av siffrorna 3 och 2:
På nästa rad vi skriver helt enkelt namnet på denna variabel. För vad? Du ska se nu.
Nu måste du köra detta block. För att göra detta, klicka på triangelikonen i verktygsfältet ovanför anteckningsblocket eller tangentkombinationen Ctrl + Enter:
Under blocket med Python-kod har ett annat block dykt upp, som innehåller utdata av resultaten från föregående block. Nu innehåller utgången talet 5. Detta nummer matas ut av den andra raden i blocket vi skrev.
I konventionella programmeringsmiljöer skulle vi behöva skriva print(a) för att uppnå denna effekt, men här kan vi utelämna anropet till denna funktion och helt enkelt skriva namnet på variabeln vi vill skriva ut.
Men du kan visa värden (tal och text) för variabler (även genom en funktion) i andra programmeringsmiljöer.
Låt oss försöka göra något mer komplicerat. Visa till exempel en bild.
Skapa ett nytt block med knappen i verktygsfältet ovanför anteckningsblocket.
I det här blocket laddar vi ner Anaconda-logotypen från Wikimedias webbplats och visar den:
Från PIL-import Bildimportförfrågningar image_url = "https://upload.wikimedia.org/wikipedia/en/c/cd/Anaconda_Logo.png" im = Image.open(requests.get(image_url, stream=True).raw) jag är
Resultatet kommer att se ut så här:

Detta är något som konventionella utvecklingsmiljöer inte klarar av. Och i JupyterLab - enkelt!
Låt oss nu försöka lägga till ett block med vanlig text mellan två redan skapade block med Python-kod. För att göra detta, välj det första blocket genom att klicka och lägg till ett nytt block med knappen i verktygsfältet. Det nya blocket kommer att infogas omedelbart efter det första blocket.
Om du gjorde allt rätt kommer resultatet att se ut så här:

Som standard är block i JupyterLab för Python-kod. Att förvandla dem till textblock, måste du ändra deras typ via verktygsfältet. I slutet av panelen, öppna listan och välj "Markdown":

Det valda blocket förvandlas till ett textblock. Den inskrivna texten kan formateras kursiv eller göra det djärv. Du kan hitta mer information om Markdown (textformateringsverktyg).
Så här kan du designa textblock i ett anteckningsblock:

Exportera
I JupyterLab kan du exportera din bärbara dator till det mesta olika format. För att göra detta, välj fliken "Anteckningsbok" högst upp i miljön. I menyn som öppnas väljer du "Exportera till..." och väljer formatet (till exempel PDF) som du vill konvertera ditt anteckningsblock till.

Här är en länk till kärnan med anteckningsblocket från den här artikeln.

Hantera Python-moduler
Du kan aktivera/avaktivera/ladda ner moduler från Anaconda Navigator. För att göra detta, välj "Environments" i menyn till vänster:

Som standard visas en lista över installerade moduler (~217 stycken). Bland dem är sådana populära som numpy (att arbeta med arrayer) eller scypi (vetenskapliga och tekniska beräkningar).
För att installera nya paket, i rullgardinsmenyn ovanför tabellen (där det står "Installerad"), välj "Inte installerat":

Listan kommer att uppdateras - listan över avinstallerade moduler kommer att laddas automatiskt.
Markera rutorna bredvid de moduler du vill ladda ner och klicka sedan på knappen "Apply" i det nedre högra hörnet för att ladda ner och installera dem. När processen är klar kommer du att kunna använda dessa moduler i anteckningsböcker.
Slutsatser
Du kan koncentrera dig på att skriva algoritmen och omedelbart visualisera resultatet av exekvering av koden, istället för att pilla med komplexa programmeringsmiljöer stora program och en konsol som bara kan mata ut siffror och text.
Alexander Krot, student vid FIVT MIPT, min gode vän och, på senare tid, kollega, lanserade en serie artiklar om praktiska verktyg för intelligent analys av big data och maskininlärning (Data mining and machine learning).
3 artiklar har redan publicerats, jag hoppas att det kommer fler i framtiden:
1) Introduktion till maskininlärning med Python och Scikit-Learn
2) The Art of Feature Engineering i Machine Learning
3) När det verkligen finns mycket data: Vowpal Wabbit
De publicerade artiklarna fokuserar på de praktiska aspekterna av att arbeta med verktyg för automatisk dataanalys och med algoritmer som låter dig förbereda data för effektiv maskinanalys. I synnerhet ges exempel på kod i Python (förresten, vi började nyligen använda Python) med det specialiserade Scikit-Learn-biblioteket, som snabbt kan startas på hemdator eller personligt moln för att själv få en smak av big data.
Nyligen funderade jag på hur. Bekantskap med ovanstående verktyg gör det nu möjligt för oss att genomföra praktiska experiment i denna riktning (Python-programmet kan förresten också köras på Linux som är inbyggt i styrenheten, men här är exempel på att slipa gigabyte med data mobil processor Det är osannolikt att det fungerar). Och förresten, Scala är också respekterat bland ingenjörer som arbetar med big data att integrera sådan kod blir ännu enklare.
Traditionellt sett eliminerar inte behärskning av några verktyg behovet av att hitta ett bra problem som effektivt kan lösas med deras hjälp (såvida inte, naturligtvis, någon annan ställer in den här uppgiften åt dig). Men utrymme ytterligare egenskaperöppnas. Enligt min mening kan det se ut ungefär så här: en robot (eller en grupp robotar) samlar in information från sensorer, skickar den till en server, där den ackumuleras och bearbetas för att leta efter mönster; Därefter kommer algoritmen att jämföra de hittade mönstren med de operativa värdena för robotens sensorer och skicka den förutsägelser om det mest sannolika beteendet miljö. Eller på servern förbereds en kunskapsbas om terrängen eller en viss typ av terräng i förväg (till exempel i form av karaktäristiska fotografier av landskapet och typiska objekt), och roboten kommer att kunna använda denna kunskap att planera beteende i en operativ miljö.
Jag kommer att stjäla den första artikeln som en primer, resten från länkarna på Habré:
Importera numpy som np import urllib # url med dataset url = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"# ladda ner filen raw_data = urllib.urlopen(url) # ladda CSV-filen som en numpy matris dataset = np.loadtxt(raw_data, delimiter="," ) # separera data från målattributen X = dataset[:,0 :7 ] y = dataset[:,8 ]
Datanormalisering
Alla är väl medvetna om att de flesta gradientmetoder (på vilka nästan alla maskininlärningsalgoritmer i huvudsak är baserade) är mycket känsliga för dataskalning. Därför, innan du kör algoritmer, görs det oftast heller normalisering, eller den sk standardisering. Normalisering innebär att ersätta nominella egenskaper så att var och en av dem ligger i intervallet från 0 till 1. Standardisering innebär sådan dataförbehandling, varefter varje funktion har ett medelvärde på 0 och en varians på 1. Scikit-Learn har redan funktioner redo för detta:Från sklearn import förbearbetning # normalisera dataattributen normalized_X = preprocessing.normalize(X) # standardisera dataattributen standardized_X = preprocessing.scale(X)
Funktionsval
Det är ingen hemlighet att det viktigaste när man löser ett problem ofta är förmågan att korrekt välja och till och med skapa funktioner. I engelsk litteratur kallas detta Funktionsval Och Funktionsteknik. Även om Future Engineering är en ganska kreativ process och förlitar sig mer på intuition och expertkunskap, har Feature Selection redan ett stort antal färdiga algoritmer. "Träd"-algoritmer gör det möjligt att beräkna informationsinnehållet i funktioner:Från sklearn importmätvärden från sklearn.ensemble import ExtraTreesClassifier model = ExtraTreesClassifier() model.fit(X, y) # visa den relativa betydelsen av varje attribut print(model.feature_importances_)
Alla andra metoder är på ett eller annat sätt baserade på effektiv uppräkning av delmängder av funktioner för att hitta den bästa delmängden som den konstruerade modellen ger bäst kvalitet på. En sådan brute force-algoritm är algoritmen Rekursive Feature Elimination, som också är tillgänglig i Scikit-Learn-biblioteket:
Från sklearn.feature_selection import RFE från sklearn.linear_model import LogisticRegression model = LogisticRegression() # skapa RFE-modellen och välj 3 attribut rfe = RFE(modell, 3 ) rfe = rfe.fit(X, y) # sammanfatta urvalet av attributen print(rfe.support_) print(rfe.ranking_)
Konstruktion av algoritmen
Som redan nämnts implementerar Scikit-Learn alla de viktigaste maskininlärningsalgoritmerna. Låt oss titta på några av dem.Logistisk tillbakagång
Den används oftast för att lösa klassificeringsproblem (binär), men flerklassklassificering är också tillåten (den så kallade one-vs-all-metoden). Fördelen med denna algoritm är att vi vid utgången för varje objekt har sannolikheten att tillhöra klassenFrån sklearn importmätvärden från sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X, y) print(model) # gör förutsägelser förväntade = y förutspått = model.predict(X)
Naiv Bayes
Det är också en av de mest kända maskininlärningsalgoritmerna, vars huvuduppgift är att återställa distributionstätheterna för träningsprovdata. Ofta ger denna metod god kvalitet i klassificeringsproblem i flera klasser.Från sklearn importmätvärden från sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X, y) print(model) # gör förutsägelser förväntade = y förutspått = model.predict(X) # sammanfatta modellens passform print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
K-närmaste grannar
Metod kNN (k-Nearest Neighbors) används ofta som komponent mer komplex klassificeringsalgoritm. Till exempel kan dess bedömning användas som ett tecken för ett objekt. Och ibland ger en enkel kNN på väl valda funktioner Perfekt kvalite. På korrekt konfiguration parametrar (främst mått), ger algoritmen ofta god kvalitet i regressionsproblemFrån sklearn import mätvärden från sklearn.neighbors import KNeighborsClassifier # anpassa en k-närmaste granne-modell till data model = KNeighborsClassifier() model.fit(X, y) print(model) # gör förutsägelser förväntade = y förutspått = model.predict(X) # sammanfatta modellens passform print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Beslutsträd
Klassificerings- och regressionsträd (CART) används ofta i problem där objekt har kategoriska egenskaper och används för regressions- och klassificeringsproblem. Träd är mycket lämpliga för flerklassklassificeringFrån sklearn importera mätvärden från sklearn.tree import DecisionTreeClassifier # anpassa en CART-modell till data model = DecisionTreeClassifier() model.fit(X, y) print(model) # gör förutsägelser förväntade = y förutsagt = model.predict(X) # sammanfatta modellens passform print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Stöd Vector Machine
SVM (Support Vector Machines)är en av de mest kända maskininlärningsalgoritmerna, som främst används för klassificeringsuppgifter. Precis som logistisk regression tillåter SVM klassificering i flera klasser med en-mot-alla-metoden.Från sklearn importmätvärden från sklearn.svm import SVC # anpassa en SVM-modell till datamodellen = SVC() model.fit(X, y) print(model) # gör förutsägelser förväntade = y förutsagt = model.predict(X) # sammanfatta modellens passform print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Förutom klassificerings- och regressionsalgoritmer har Scikit-Learn ett stort antal fler komplexa algoritmer, inklusive klustring, samt implementerade tekniker för att konstruera kompositioner av algoritmer, inklusive Säckväv Och Boostning.
Optimering av algoritmparametrar
Ett av de svåraste stegen för att bygga verkligt effektiva algoritmer är att välja korrekta parametrar. Vanligtvis blir detta lättare med erfarenhet, men på ett eller annat sätt måste man gå överbord. Lyckligtvis har Scikit-Learn redan en hel del funktioner implementerade för detta ändamål.Låt oss till exempel titta på valet av en regulariseringsparameter, där vi turas om att prova flera värden:
Importera numpy som np från sklearn.linear_model import Ridge från sklearn.grid_search import GridSearchCV # förbered en rad alfavärden att testa alphas = np.array() # skapa och anpassa en åsregressionsmodell, testa varje alfa model = Ridge() grid = GridSearchCV(estimator=modell, param_grid=dict(alpha=alphas)) grid.fit(X, y) print(grid) # sammanfatta resultaten av rutnätssökningen print(grid.best_score_) print(grid.bästa_estimator_.alpha)
Ibland är det mer effektivt att slumpmässigt välja en parameter från ett visst segment många gånger, mäta kvaliteten på algoritmen för en given parameter och därigenom välja den bästa:
Importera numpy som np från scipy.stats importera uniform som sp_rand från sklearn.linear_model import Ridge från sklearn.grid_search import RandomizedSearchCV # förbered en enhetlig fördelning för att sampla för alfaparametern param_grid = ("alpha" : sp_rand()) # skapa och anpassa en åsregressionsmodell, testa slumpmässiga alfavärden model = Ridge() rsearch = RandomizedSearchCV(estimator=modell, param_distributions=param_grid, n_iter=100 ) rsearch.fit(X, y) print(rsearch) # sammanfatta resultaten av slumpmässig parametersökning print(rsearch.best_score_) print(rsearch.best_estimator_.alpha)
Vi har tittat på hela processen att arbeta med Scikit-Learn-biblioteket, med undantag för att mata ut resultaten tillbaka till en fil, som erbjuds läsaren som en övning, eftersom en av fördelarna med Python (och Scikit- Lär dig biblioteket själv) jämfört med R är dess utmärkta dokumentation. I de följande delarna kommer vi att överväga i detalj var och en av avsnitten, i synnerhet kommer vi att beröra en så viktig sak som Skönhetsteknik.
Jag hoppas verkligen att det här materialet kommer att hjälpa nybörjare att börja lösa maskininlärningsproblem i praktiken så snart som möjligt. Sammanfattningsvis vill jag önska framgång och tålamod till dem som precis har börjat delta i maskininlärningstävlingar!
Fuskblad kommer att frigöra ditt sinne för viktigare uppgifter. Vi har samlat 27 av de bästa fuskbladen som du kan och bör använda.
Ja, maskininlärning utvecklas med stormsteg, och jag tror att min samling kommer att bli föråldrad, men för juni 2017 är den mer än relevant.
Om du inte vill ladda ner alla cheat sheets separat, ladda ner det färdiga zip-arkivet.
Maskininlärning
Det finns en hel del användbara flödesscheman och tabeller som täcker maskininlärning. Nedan är de mest kompletta och nödvändiga.
Neurala nätverksarkitekturer
Med tillkomsten av nya neurala nätverksarkitekturer har de blivit svåra att spåra. Ett stort antal akronymer (BiLSTM, DCGAN, DCIGN, känner någon till alla?) kan vara skrämmande.
Så jag bestämde mig för att sätta ihop ett fuskblad som innehåller många av dessa arkitekturer. Det mesta avser neurala nätverk. Det finns bara ett problem med denna visualisering: användningsprincipen visas inte. Till exempel kan variationsautokodare (VAE) se ut som autokodare (AE), men inlärningsprocessen är annorlunda.
Microsoft Azure Algorithm Flödesschema
Microsoft Azure maskininlärning fuskblad som hjälper dig att välja rätt algoritm för en prediktiv analysmodell. Maskinstudio Microsoft utbildning Azure innehåller ett stort bibliotek med algoritmer för regression, klassificering, klustring och anomalidetektering.

SAS Algoritm Flödesschema
Fuskblad med SAS-algoritmer gör att du snabbt kan hitta en lämplig algoritm för att lösa ett specifikt problem. Algoritmerna som presenteras här är resultatet av en sammanställning av feedback och råd från flera datavetare, utvecklare och maskininlärningsexperter.

Samling av algoritmer
Regression, regularisering, klustring, beslutsträd, Bayesianska och andra algoritmer presenteras här. Alla är grupperade enligt operativa principer.

Även listan i infografiskt format:

Prognosalgoritm: "för/emot"
Dessa fuskblad har samlats in bästa algoritmerna, som används i prediktiv analys. Prognos är en process där värdet på en utdatavariabel bestäms från en uppsättning indatavariabler.

Pytonorm
Det är inte förvånande att Python-språket har samlat en stor community och många onlineresurser. För det här avsnittet valde jag ut de bästa cheat sheets jag arbetat med.
Detta är en samling av de 10 mest använda maskininlärningsalgoritmerna med koder i Python och R. Fuskbladet är lämpligt som referens för att hjälpa dig använda användbara maskininlärningsalgoritmer.

Det går inte att förneka att Python är på frammarsch idag. Fuskbladen innehöll allt du behöver, inklusive funktioner och definitionen av objektorienterad programmering med Python-språket som exempel.

Och detta fuskblad kommer att vara ett bra tillägg till den inledande delen av alla Python-handledningar:

NumPy
NumPy är ett bibliotek som gör att Python kan bearbeta data snabbt. När du först studerar kan du ha problem med att komma ihåg alla funktioner och metoder, så här har vi samlat de mest användbara fuskbladen som kan göra att lära dig biblioteket mycket enklare. Import/export, skapande av arrayer, kopiering, sortering, flytta element och mycket mer behandlas.

Och här presenteras dessutom den teoretiska delen:

En schematisk representation av några av uppgifterna finns i detta fuskblad:

Allt nödvändig information med diagram:

Pandas är ett högnivåbibliotek designat för dataanalys. Motsvarande ramar, paneler, objekt, paketfunktioner och annan nödvändig information samlas i ett bekvämt organiserat fuskark:

En schematisk representation av information om Pandas bibliotek:

Och detta fuskblad inkluderade en detaljerad presentation med exempel och tabeller:

Om du kompletterar det tidigare Pandas-biblioteket med matplotlib-paketet kommer du att kunna rita grafer för mottagna data. Matplotlib ansvarar för att rita grafer i Python. Detta är ofta det första visualiseringsrelaterade paketet som nybörjare Python-programmerare använder, och de fuskblad som presenteras hjälper dig att snabbt navigera i det här bibliotekets funktionalitet.

I det andra fuskbladet hittar du fler exempel på visuell presentation av grafer:

Scikit-Learn Python-biblioteket med maskininlärningsalgoritmer är inte det lättaste att lära sig, men med cheat sheets blir principen för dess funktion så tydlig som möjligt.

Schematisk representation:

Med teori, exempel och ytterligare material:

TensorFlow
Ytterligare ett bibliotek för maskininlärning, men med egen funktionalitet och svårigheter att förstå det. Nedan finns ett användbart fuskblad för att lära dig TensorFlow.
Varje dataanalysexpert frågar sig själv vilket programmeringsspråk man ska välja. — R eller Python, skriver de? För att hitta det bästa svaret på denna fråga används i de flesta fall den mest populära Googles sökmotor. Utan de rätta svaren blir potentiella kandidater aldrig experter på maskininlärning eller dataanalys. Den här artikeln försöker förklara detaljerna för R- och Python-språken för deras användning i utvecklingen av maskininlärningsteknik.
Maskininlärning och datavetenskap är blomstrande och ständigt växande segment av dagens avancerade teknologier som adresserar olika komplexa problem och utmaningar i utvecklingen av lösningar och applikationer. I detta avseende, på en global skala, står analytiker och dataanalysexperter inför de bredaste möjligheterna att använda sina styrkor och förmågor inom teknologier som t.ex. artificiell intelligens, IoT och big data. Att lösa nytt komplexa uppgifter Experter och proffs kräver ett kraftfullt verktyg för att bearbeta enorma mängder data, och en mängd maskininlärningsverktyg och bibliotek har utvecklats för att automatisera uppgifterna med dataanalys, igenkänning och aggregering.
I utvecklingen av maskininlärningsbibliotek intar programmeringsspråk som R och Python ledande positioner. Många experter och analytiker lägger tid på att välja önskat språk. Vilket programmeringsspråk är mer att föredra för maskininlärning?
Vilka är likheterna mellan R och Python
- Båda språken — R och Python — är programmeringsspråk med öppen källkod. Ett stort antal medlemmar av programmeringsgemenskapen har bidragit till utvecklingen av dokumentation och utvecklingen av dessa språk.
- Språken kan användas för dataanalys, analys och maskininlärningsprojekt.
- Båda har avancerade verktyg för att slutföra datavetenskapliga projekt.
- Betala för dataanalysexperter som föredrar att arbeta i R och Python är nästan densamma.
- Aktuella versioner av Python och R — x.x
R och Python – konkurrens mellan konkurrenter
Historisk utflykt:
- 1991 föreslog Guido Van Rossum, inspirerad av utvecklingen av språken C, Modula-3 och ABC, ett nytt programmeringsspråk - Python.
- 1995 skapade Ross Ihaka och Robert Gentleman R-språket, som utvecklades i analogi med programmeringsspråket S.
Mål:
- Mål Python utveckling- Skapande mjukvaruprodukter, förenkla utvecklingsprocessen och säkerställa kodläsbarhet.
- Medan R-språket utvecklades främst för användarvänlig dataanalys och för att lösa komplexa statistiska problem. Det är ett i första hand statistiskt orienterat språk.
Lätt att lära sig:
- Tack vare sin kodläsbarhet är Python lätt att lära sig. Det är ett nybörjarvänligt språk som kan läras utan tidigare erfarenhet av programmering.
- R-språket är svårt, men ju längre du använder det här språket i programmering, desto lättare är det att lära sig och desto högre är din effektivitet när det gäller att lösa komplexa statistiska formler. För erfarna programmerare är R ett alternativ gå till.
Grupper:
- Python har stöd olika samhällen, vars medlemmar utvecklar språket för lovande tillämpningar. Programmerare och utvecklare är, precis som StackOverflow-medlemmar, aktiva medlemmar i Python-communityt.
- R-språket stöds också av medlemmar i en mångsidig gemenskap genom e-postlistor, dokumentation av användarbidrag och andra De flesta statistiker, forskare och dataanalysexperter är aktivt involverade i utvecklingen av språket.
Flexibilitet:
- Python är ett språk som betonar produktivitet, så det är tillräckligt flexibelt för att utveckla en mängd olika applikationer. För att utveckla storskaliga applikationer innehåller Python olika moduler och bibliotek.
- R-språket är också flexibelt för att utveckla komplexa formler, utföra statistiska tester, datavisualisering och mer. Det innehåller en mängd färdiga paket.
Ansökan:
- Python är ledande inom applikationsutveckling. Det används för att stödja webbplatsutveckling, spelutveckling och datavetenskap.
- R-språket används främst för att utveckla dataanalysprojekt som fokuserar på statistik och visualisering.
Både R- och Python-språken har fördelar och nackdelar. I de flesta fall är dessa specifik-centrerade språk, eftersom R är fokuserat på statistik och visualisering, och Python är på enkelhet i att utveckla alla applikationer.
Utifrån detta kan R användas främst för forskning inom vetenskapliga institut, vid utförande statistiska analyser och datavisualisering. Å andra sidan används Python för att förenkla processen med att förbättra program, bearbeta data etc. R-språket kan vara mycket produktivt för statistiker som arbetar inom området dataanalys, medan Python är bättre lämpat för programmerare och utvecklare som skapar produkter för data scientists.



