Det finns tre typer av nyckelfält i MS Access: enkel nyckel, sammansatt nyckel och räknare. Vanligtvis i
Ett fält med icke-repeterande värden, en enkel nyckel eller en kombination av flera fält, en sammansatt nyckel, väljs som ett nyckelfält. Om sådana fält inte hittas eller om den sammansatta nyckeln är för komplex, används en speciell datatyp - en räknare. Räknaren innehåller radnummer och kommer att öka med 1 varje gång en ny post skapas.
Den primära nyckeln måste uppfylla kraven på unikhet och minimalitet. Det unika med nyckelfältet säkerställer ett av kraven för databasintegritet - överensstämmelse. Minimaliteten i nyckelfältet säkerställer effektiv användning av databasminnet. Dessa krav motsäger ofta varandra – eftersom komplex nyckel nyckel som består av flera fält med mer sannolikt kommer att vara unik, men för den i databasen kommer det att finnas en mer minne. I detta avseende är en rimlig kompromiss nödvändig. Dessutom beror valet eller tilldelningen av en primärnyckel avsevärt på antalet kolumner i tabellen.
dessutom
52 - 53. Databasstruktur i Access. Relationer mellan tabeller Få tillgång till verktyg för att upprätta relationer mellan tabeller.
52 En databas är en namngiven samling strukturerad data, som beskriver tillståndet för objekt för en ämnesområde och deras relationer. Till exempel biblioteks- och arkivsystem, telefon- och adresskataloger, Databas om tillgänglighet och förflyttning av varor, om organisationens anställda etc. Syftet med att skapa en databas är att organisera information från ett ämnesområde, möjligheten att söka efter nödvändig data och bearbeta den. Låt oss titta på de grundläggande begreppen i en databas:
En tabell är det huvudsakliga databasobjektet utformat för att lagra elementär data som består av radposter och kolumnfält.
En elementär data är en dataenhet som beskriver ett attribut för ett objekt i ämnesområdet. Till exempel efternamnet på en specifik läsare eller titeln på en specifik bok i en biblioteksdatabas.
Ett fält är en samling logiskt relaterade elementära data som beskriver samma attribut för alla objekt i ämnesområdet. I strukturen av en tvådimensionell tabell är dess analog en kolumn.
En post är en samling logiskt relaterade fält, vars data beskriver alla egenskaper hos ett ämnesområdesobjekt. Till exempel all data om en publikation. I strukturen av en tvådimensionell tabell är dess analog en rad. En MS Access-databas kan innehålla många objekt:
En tabell är huvudobjektet i en databas. I MS Access lagras all information i tabeller. För det första lagrar tabeller all tillgänglig data i databasen, och för det andra lagrar tabeller även strukturen fältbaser, deras typer och egenskaper.
En fråga är ett sätt att hämta information från en databas. Med hjälp av det här verktyget kan du extrahera nödvändiga data från 1 eller flera tabeller och tillhandahålla den till användaren bekväm form. Med hjälp av frågor utförs operationer som dataval, sortering och filtrering.
Ett formulär är ett verktyg för att visa och lägga in data i en databas. Syftet med formulär är att låta användaren fylla i och se endast ett visst antal fält.
Rapporten används för att visa sammanfattande data från tabeller och frågor i en lättöverskådlig form. Rapporter ger specialverktyg
för att gruppera data och ange speciella designelement som är karakteristiska för tryckta dokument: sidhuvuden och sidfötter, sidnummer, serviceinformation om tidpunkten för skapandet och konstnären.
Sidor är ett speciellt objekt gjort i HTML-kod, placerat på en webbsida och överfört till klienten tillsammans med det. Detta objekt i sig är inte en databas, utan innehåller komponenter genom vilka den överförda webbsidan är ansluten till databasen som finns kvar på servern. Genom att använda dessa komponenter kan en webbplatsbesökare se databasposter i fälten på åtkomstsidan.
Makron och moduler. Dessa objekt är designade både för att automatisera repetitiva operationer när man arbetar med en databas, och för att skapa nya funktioner genom programmering. Makron består av en sekvens interna team MS Access DBMS och moduler skapas med hjälp av ett externt programmeringsspråk. Detta är ett av sätten med vilka en utvecklare kan lägga till icke-standardiserade funktionalitet, öka systemets prestanda, såväl som nivån på dess säkerhet.
52-53 Att ställa in relationer mellan tabeller sker i Data Schema-fönstret, som öppnas med hjälp av verktygsfältsknappen eller genom att använda kommandot Data Schema i Verktyg-menyn. Ett fönster öppnas Lägger till tabeller, på fliken Tabeller där du måste välja tabellerna mellan vilka anslutningar upprättas genom att klicka på knappen Lägg till. Fönstret Dataschema öppnar listor med fält för dessa tabeller. En av tabellerna anses vara huvudtabellen och den andra är den länkade tabellen. Huvudtabellen är den tabell som deltar i relationen med sitt nyckelfält. Med knappen intryckt på det länkade fältet i huvudtabellen, flytta muspekaren till önskat fält i den länkade tabellen. När du släpper musknappen öppnas fönstret Redigera länkar automatiskt för att konfigurera länkegenskaperna. I det här fönstret kan du ändra namnen på de fält som är involverade i relationen och ställa in kontroller för att säkerställa dataintegritetsförhållanden. Om endast kryssrutan Säkerställ dataintegritet är markerad kan du inte ta bort data från nyckelfältet i huvudtabellen. Om kryssrutorna Kaskaduppdatering av relaterade fält och Kaskadborttagning av relaterade fält är aktiverade tillsammans med det, är redigeringsåtgärder och radering av data i huvudtabellens nyckelfält tillåtna, men de åtföljs av automatiska ändringar i den relaterade tabellen . Den resulterande inter-tabellrelationen visas i Data Schema-fönstret som en linje som förbinder två fält i olika tabeller. Den där. , poängen med att skapa relationskopplingar mellan tabeller är å ena sidan att skydda data, och å andra sidan att automatisera att göra ändringar i flera tabeller samtidigt när det sker ändringar i en tabell. När du organiserar en relation mellan tabeller bör du tänka på att de länkade
Fälten måste vara av samma typ och samma egenskaper, eller åtminstone konsekventa.
Tabell
Detta är en term som används väldigt ofta i FoxPro och som dessutom ofta används på ett sätt som inte alls förstås av nykomlingar. Vi kan säga att denna term har två definitioner (som termen "databas")
Tabellär en fil med filtillägget DBF och relaterade filer med samma namn men med tillägget FPT(en fil för att lagra fält som Memo och Allmänt) och med tillägget CDX(strukturell indexfil)
Formellt är detta en helt korrekt definition. Det enda problemet är att i de allra flesta fall när FoxPro använder termen "tabell", då är det inte alls vad som menas med detta. Mer exakt, inte riktigt det.
Tabell- det här är en viss filbild med förlängning DBFöppna i angivet datasessioner och i det angivna arbetsyta.
Med amerikanernas önskan att skära ner allt brydde de sig inte om att komma på en lämplig term. Därför uppstår ständigt förvirring. Det vore lämpligare att använda istället för termen "tabell" villkor "markör" eller "alias", eftersom de mer exakt återspeglar essensen. Och faktiskt, i vissa fall används dessa termer just i denna mening, vilket bara helt förvirrar allt, eftersom de också används i andra betydelser.
Alias (alias) - Det här DBF-fil "alias"öppen i någon arbetsyta. Vanligtvis matchar aliaset namnet på DBF-filen. Detta är dock inte alltid fallet. Faktum är att det i en datasession inte kan finnas två identiska alias. Därför, om tabellaliaset inte specificeras explicit när det öppnas (ALIAS-alternativet i USE-kommandot, eller på något annat sätt), kommer FoxPro automatiskt att tilldela ett unikt alias för tabellen, med början, naturligtvis, med ett alias som matchar namnet på DBF-filen om möjligt.
Tänk på det absolut i de flesta fallen under termen "tabell" exakt vad som menas "filbild", dvs. filen är redan öppnad via kommandot USE (eller någon annan metod) i FoxPro-miljön. Om det är en DBF-fil som avses så anges detta som regel specifikt.
I FoxPro 2.x-versioner, som termen används "tabell" term som används "databas"(uppenbarligen var det här förlängningen kom ifrån - de första bokstäverna i den engelska frasen Databasfil), eftersom DBC-filen ännu inte fanns i dessa versioner. Följaktligen, när programmerare byter till Visual FoxPro-versionen, kan det vara ganska svårt att förstå dem på grund av denna förvirring med termer.
Du bör alltid komma ihåg att bord öppnas i den sk "arbetsytor". Vad detta är är inte tydligt förklarat någonstans (de säger att det redan är klart). Jag ska försöka definiera det så här
Arbetsyta (Arbetsyta) är en numerisk identifierare som kan tilldelas en tabell. Om du har erfarenhet av programmering på andra språk kan du säga att arbetsytan är " hantera" eller " deskriptor"-tabeller i FoxPro-miljön
Endast en tabell kan motsvara en arbetsyta åt gången, medan flera arbetsytor kan motsvara en tabell. Med andra ord samma tabell kan öppnas samtidigt i flera arbetsytor, men bara en tabell kan vara öppen i en specifik arbetsyta.
Tills tabellen öppnas i någon arbetsyta verkar den inte existera för FoxPro. Mer exakt kan du inte utföra några operationer för att läsa/modifiera data med den med hjälp av standardkommandon och funktioner.
Förutom konceptet "workspace" introducerade FoxPro konceptet "datasession" (DataSession)
Datasession- Det här är en dynamisk kopia av FoxPro-miljön. Genom att öppna FoxPro-miljön öppnar du automatiskt en datasession, som automatiskt avslutas när du avslutar FoxPro. Men inne i själva FoxPro har du möjlighet att göra en kopia av FoxPro-miljön med hjälp av den sk "privata datasessioner"
Vad exakt ger detta? "privata datasessioner"? Och detta gör det möjligt att simulera flera användares arbete, oberoende av varandra, inom en FoxPro-applikation.
Som ett resultat är tabeller som öppnas i en datasession "inte synliga" i en annan datasession. Och följaktligen påverkar manipulationer (inte alla) som utförs med tabeller i en datasession inte andra datasessioner.
Det vanligaste användningsfallet Privat datasession- detta är den samtidiga öppningen av flera formulär som visar samma dokument med olika sidor. För detta ändamål upprättas i regel ett förhållande mellan tabellerna av SÄTT RELATION. Om du öppnar sådana formulär i en datasession blir detta ofta ett stort problem, eftersom du i ett formulär måste tillämpa vissa index och relationer till tabeller och i en annan - andra. Och att byta från en form till en annan resulterar i oförutsägbara innehållsförändringar.
Tabellnamn
En tabellfil, som alla andra filer i ett Windows-system, kan innehålla upp till 128 tecken, innehålla mellanslag, ryska tecken, siffror och vissa specialtecken. Men för att göra det enklare att arbeta i FoxPro skulle jag rekommendera följande begränsningar i namnet på tabellfilen
Bordsplats
Skälen till denna rekommendation beskrivs i avsnitt Var ska projektfilerna placeras. Kort sagt, poängen är att annars ökar risken för oavsiktlig korruption av datafiler och följaktligen dataförlust. Det gör också sökningen enklare nödvändiga filer och skapande säkerhetskopiering.
Förbi i stort sett, naturligtvis kan du behålla databasfilen i en katalog och de inkluderade DBF-filerna i en annan. Men detta komplicerar själva projektutvecklingsprocessen. Till exempel att skapa en säkerhetskopia i det enklaste fallet är enkel kopiering kataloger med arbetsfiler till en annan plats. Om arbetsfilerna är separerade från databasfilen kommer kopiering av 2 kataloger att krävas. Koden kommer därför att bli mer komplex.
Dessutom, i det här fallet kommer storleken på databasfilen att öka något ( närmare bestämt en fil DCT - memofil), eftersom den lagrar direkt relativ väg till tabellerna som ingår i den. Om tabellerna finns i samma katalog som själva databasfilen, så existerar helt enkelt inte denna relativa sökväg. För att vara rättvis bör det noteras att den relativa sökvägen till databasen också lagras i rubrikerna för de tabeller som ingår i denna databas. Men detta påverkar inte storleken på tabellerna, eftersom ett fast utrymme alltid tilldelas för denna relativa sökväg, oavsett om det finns.
Jobbar faktiskt med tabeller
Som nämnts ovan öppnas tabeller alltid i en specifik arbetsyta och för att gå till önskad arbetsyta finns det två sätt att adressera: antingen med numret på denna arbetsyta eller med namnet på aliaset för tabellen som öppnas i denna arbetsyta.
Anledningen till denna rekommendation är att en viss arbetsyta inte alls bryr sig om vilken tabell som är öppen i den. Och under vissa förutsättningar kan bordet öppnas igen, men i en annan arbetsyta. Följaktligen, när man adresserar en arbetsyta med dess nummer, är det omöjligt att vara helt säker på att exakt den önskade tabellen är öppen i den. Och i allmänhet, att åtminstone något bord är öppet i det. Å andra sidan är det mer sannolikt att åtkomst via alias pekar på den önskade tabellen (det kan också finnas alternativ här, men det här är mer exotiska fall)
Arbetsområde numrerat 0
Nollarbetsområdet förtjänar särskilt omnämnande. En referens till arbetsyta noll betyder en referens till den första lediga arbetsytan. De där. arbetsområde, dvs för närvarande inte kopplat till någon tabell
Denna adressering låter dig göra flera saker
För det första låter det dig öppna nya tabeller utan att oroa dig för om den nuvarande arbetsytan är upptagen av en annan tabell. De där. ett kommando av formen ges
| ANVÄND MyTable I 0 |
Det är nödvändigt att ange en arbetsyta på noll eftersom tabellen annars kommer att öppnas i den aktuella arbetsytan samtidigt som alla tabeller som annars kan vara öppna i den stängs. Och i den här syntaxen kommer att öppna en ny tabell inte att påverka den tidigare öppna bord
En annan användning av null-arbetsytan är i standardinställningarna.
Till exempel vet du förmodligen redan att någon Se som standard öppnas i läge optimistisk radbuffring (3), men om du behöver använda den i läge optimistisk tabellbuffring (5), sedan efter att du har öppnat den måste du göra den här omkopplaren med funktionen CursorSetProp() sådär
Det är sant att sådana globala inställningar måste användas med försiktighet, eftersom de bara är globala, dvs. gäller för alla arbetsområden utan undantag.
Jag kommer också att notera att den globala inställningen av nollarbetsytan inte kommer att påverka arbetsytor som redan har öppna tabeller. Det påverkar bara arbetsytor som ännu inte används.
Stort bord
Mycket ofta på konferenser dyker frasen upp "stort bord".
Jag skulle säga att konceptet "stort bord" väldigt subjektivt. Enligt mina observationer betyder "stor" i de flesta fall en tabell vars läs-/skrivoperationer tar en märkbar tid. Synlig för användaren.
Ett av de viktigaste kriterierna som påverkar exekveringstiden för en operation med en tabell är antalet poster i denna tabell. Men då uppstår frågan: en stor tabell är hur många poster det finns?
Det högsta tillåtna antalet poster som kan finnas i en tabell är 1 miljard poster. De där. en och nio nollor. Så, "stor" kan betraktas som en tabell som innehåller minst flera miljoner skivor.
Men återigen, termen "stor" kommer inte upp när man bara uppskattar antalet poster, utan när man uppskattar exekveringstiden för vissa operationer med sådana tabeller. Men det finns många anledningar som påverkar läs/skrivtiden. Följaktligen är tabellen som anses vara "stor" i ett fall inte så "stor" i ett annat.
Återigen minns jag amerikanernas lättja och deras önskan att minska allt (dock har ryssarna gått ännu längre här - de kan säga nästan allt med bara några få specifika ord). Termin "markör" används i flera betydelser beroende på sammanhanget.
Markör- det här är filbilden DBF öppen i ett av arbetsområdena
Markör- detta är en temporär tabell som är resultatet av kommandots körning Välj-SQL
Markör- Det här pekare Tangentbords textinmatningsindikatorposition
Tja, den sista definitionen är inte särskilt intressant. I den meningen att allt är klart här, förutom varför denna term också användes för tillfälliga tabeller, eftersom ordet "markör" faktiskt översatt som "pekare".
Markör som en DBF-filbild
Återigen detta kort definition inte helt korrekt, eftersom ett specifikt objekt i denna mening används. Introduktionen av detta objekt förklaras av behovet av visualisering tabeller vid utformning av formulär och rapporter.
Jag kommer också att notera att markören, som ett objekt, inte bara används som en bild dbf filer, men också som en bild Se. Och Visa och bord - det är inte samma sak.
Markör som en tillfällig tabell
Detta är den vanligaste användningen av denna term. Det finns faktiskt två sätt att skapa sådana markörer
Första sättetär användningen av kommandot SKAPA MARKÖR. Markören som skapas på detta sätt kommer att kunna redigeras. Och detta blir ett tillfälligt bord, d.v.s. den kommer automatiskt att förstöras vid stängningsögonblicket. Tja, det finns inte mycket att säga om denna metod. Det finns inga problem eller egenheter här
Andra sättet- detta är användningen av alternativet MARKÖR i ett lag SELECT-SQL. Något i stil med följande syntax
| VÄLJ * FRÅN MyTable TILL CURSOR TmpTable |
Det här är TmpTable markören
Beroende på olika förhållanden den här markören kan ha olika fysisk "inkarnation" och olika egenskaper
Om SQL-frågan är helt optimerad, öppnas helt enkelt samma tabell med ett filter applicerat i stället för att skapa en ny fil. Detta är ofta en mycket obehaglig överraskning. Du kan kontrollera vad den genererade markören är fysiskt med hjälp av DBF()-funktionen
| VÄLJ * FRÅN MyTable INTO CURSOR TmpTable ?DBF ("TmpTable") |
Om ett filnamn med en DBF-tillägg returneras, är den här markören samma källtabell med ett filter applicerat på den.
Om du för alla frågor vill vara säker på att markören är en tillfällig tabell och inte den ursprungliga tabellen med ett filter tillämpat, bör du lägga till alternativet INGET FILTER
| VÄLJ * FRÅN MyTable TILL CURSOR TmpTable NOFILTER |
Det här alternativet dök upp endast i version 5 av Visual FoxPro, även om det ännu inte var dokumenterat där. I tidigare versioner är det nödvändigt att lägga till dummyvillkor eller grupperingsfunktioner för att eliminera möjligheten till optimering.
Men om markören är tillfälligt bord, betyder det inte att den här temporära tabellen nödvändigtvis kommer att finnas fysiskt på disken. Det är mycket möjligt att hela det tillfälliga bordet passar helt in Bagge. De där. fungera DBF("TmpTable") kommer regelbundet att visa en viss temporär fil, men ett försök att hitta den fysiskt på disken kommer att misslyckas och funktionen FIL(DBF("TmpTable")) kommer att återvända .F.
Sant, platsen för hela den temporära tabellen i minnet kommer inte på något sätt att störa arbetet med den här temporära tabellen. I den överväldigande majoriteten av fallen borde du faktiskt inte bry dig om var det här eller det bordet är fysiskt placerat.
En annan viktig fråga är relaterad till det faktum att markörer som erhålls på detta sätt inte kan redigeras. De är skrivskyddade. Från och med version 7 av Visual FoxPro fanns det en lösning på det här problemet: specialalternativ Läsa skriva
| VÄLJ * FRÅN MyTable INTO CURSOR TmpTable NOFILTER READWITE |
Genom att använda det här alternativet kan du skapa en markör som kan redigeras. För lägre versioner av FoxPro, för att markören ska kunna redigeras, måste den öppnas igen
| VÄLJ * FRÅN MyTable TILL MARKÖR TmpReadTable NOFILTERANVÄNDNING (DBF ("TmpReadTable") I 0 IGEN alias TmpWriteTable ANVÄND I TmpReadTable |
Markören återupptäckte på detta sätt TmpWriteTable du kan nu redigera
Markörer kan indexeras precis som vanliga tabeller. Men om markören öppnas i skrivskyddat läge kan du bara skapa en indextagg för den.
Alla markörer som skapas på detta sätt raderas automatiskt från disken (om den temporära filen skapades fysiskt på disken) när de stängs. Om du har skapat en strukturell indexfil för en sådan markör, kommer denna fil också att raderas automatiskt när markören stängs.
Bildar markörnamnet i kommandot Select-SQL
Det här är inte en så enkel fråga som det kan tyckas. Problemet här är att markörnamnet faktiskt är ett alias för den temporära tabellen. Men i FoxPro kan 2 tabeller med samma alias inte öppnas i en datasession.
Markören skapas alltid på klientens dator, så det finns ingen anledning att oroa sig för konflikter med andra användare. Dessutom, även om samma projekt startas två gånger på samma maskin, kommer det fortfarande inte att finnas någon konflikt kopplad till samma markörnamn, eftersom de öppnas i olika datasessioner. En konflikt är möjlig om du skapar flera markörer med samma namn i samma datasession
Tja, till exempel, du öppnade 2 formulär med hjälp av Standarddatasession och i båda skapade de en markör med samma namn. I det här fallet kommer markören som skapades senare att skriva över markören som skapades tidigare. I det här fallet, inställningen STÄLL IN SÄKERHET spelar ingen roll. Markören kommer att återskapas tyst. Utan några ytterligare förfrågningar.
Det finns flera sätt att undvika sådana konflikter
Det sista alternativet verkar vara det mest föredragna. Du bör dock vara försiktig här. Faktum är att det i beskrivningen av FoxPro rekommenderas att använda nästa funktion
| lcCursorName=SubStr (SYS (2015),3,10) |
Problemet är att funktionen SYS(2015) kan innehålla både bokstäver och siffror i returvärdet. Detta innebär att när du använder SubStr() för att välja en sträng, kan du mycket väl sluta med ett nummer som första tecken. Och att använda en siffra som variabelnamn i FoxPro-syntaxen är oacceptabelt och du kommer oväntat att få ett meddelande om syntaxfel. För att undvika detta bör du antingen blanda bokstaven med våld
Följaktligen kommer utförandet av begäran att se ut så här:
| LOCAL lcCursorName lcCursorName=SYS (2015) VÄLJ * FRÅN MyTable INTO CURSOR &lcCursorName NOFILTER |
Denna metod för att skapa unika markörnamn kommer verkligen att säkerställa unikhet, men detta är en mycket obekväm metod på grund av behovet av att ständigt använda makroersättningar när du kommer åt en sådan markör. Därför är det lämpligt att undvika det om möjligt.
Tabellfält
Ett tabellfält är en kolumn som du ser varje gång du öppnar tabellen för visning.
Tabellfältnamn
Fältet i tabellen som ingår i (databasen) kan innehålla upp till 128 tecken, innehålla ryska tecken, siffror och några specialtecken. Men för att förenkla arbetet i FoxPro skulle jag rekommendera följande begränsningar i namnet på tabellfilen
Jo, till exempel, om du i tabellen behöver ange betalningsbeloppet och skattebeloppet, så kan du naturligtvis skapa 2 fält Platezh1 Och Platezh2. Men i det här fallet måste du varje gång komma ihåg vad siffran 1 faktiskt betyder och vad siffran 2 faktiskt betyder. Men om du lägger det här projektet åt sidan och återvände till det några månader senare, då intensiva tankar om ämnet - vad är det egentligen? - Du har det täckt. Det är mycket klokare att ge betydelsefulla namn: Platezh Och Nalog
Om din fantasi helt sviker dig och du inte vet hur du ska namnge fältet annat än till exempel "Beställa" eller "Grupp", lägg sedan till som första tecken en bokstav som anger vilken typ av data som används i det här fältet. Till exempel, "nOrder" eller "cGroup"
Jobbar faktiskt med tabellfält
Faktum är att om aliaset inte är specificerat, antar FoxPro att vi talar om ett tabellfält som finns i den aktuella arbetsytan. Och om tabellen i den aktuella arbetsytan inte har ett sådant fält, då o minnesvariabel med samma namn. Men när man skriver ett relativt komplext program är det inte alltid möjligt att med tillförsikt säga att vi är på rätt arbetsområde. Att explicit specificera ett tabellalias eliminerar detta problem.
Nyckelfält
Detta är ett av de viktigaste begreppen som används när man arbetar med tabeller och databaser
Nyckelfält- detta är ett fält (eller en uppsättning fält) vars innehåll unikt kan identifiera en tabellpost. De där. Baserat på värdet på nyckelfältet kan du alltid entydigt avgöra vilken post du talar om och det kan inte finnas 2 poster med samma värden på nyckelfältet.
Extern nyckelär ett tabellfält som innehåller värdet av ett nyckelfält i en annan tabell. De där. bara en länk till en post i en annan tabell.
Jag börjar genast med slutsatsen:
För de flesta uppgifter i FoxPro är det praktiskt att använda en surrogatnyckel av typen Integer som nyckelfält. Det är tillrådligt att ange nyckelfältet för alla databastabeller utan undantag.
Nåväl, låt oss nu titta på hur jag kom till dessa slutsatser
Naturliga eller surrogatnycklar
Det pågår fortfarande debatt om vad som är bättre att använda: surrogat eller naturliga nycklar.
Naturlig nyckelär ett fält eller en uppsättning fält som har någon fysisk betydelse. Jo till exempel personalnummer, passnummer osv.
Surrogatnyckel- detta är ett fält som inte har någon fysisk betydelse och som anges enbart i syfte att unikt identifiera posten. Informationen den innehåller är inte på något sätt logiskt relaterad till informationen från andra fält i samma tabell.
Låt oss överväga vilka fördelar och nackdelar naturliga nycklar och surrogatnycklar har
Faktum är att det viktigaste och mest avgörande kriteriet för att bedöma om ett givet fält är lämpligt för användning som ett nyckelfält eller inte är postidentifieringens unika karaktär. Vad vi menar här är, är värdet på det valda fältet unikt för varje post?
Jo, med en surrogatnyckel är allt klart - vi själva bildar dess värde utan användarmedverkan, så vi kan övervaka dess unika, men hur är det med den naturliga nyckeln?
Vid första anblicken verkar det som att allt är i sin ordning också. Hur kan ett passnummer inte vara unikt? Eller personalnummer? Det visar sig att det fortfarande kan!
För det första kan all information som användaren anger innehålla fel. Tja, folk kan inte låta bli att göra misstag. Vissa människor gör misstag oftare, andra mindre ofta, men alla gör misstag. Vissa fel kan säkert fångas upp programmatiskt, men inte alla.
Till exempel, om vi pratar om ett visst alfanumeriskt nummer (passnummer) och användaren skrev in "123 ABC", men det borde ha varit "423 ABC", så är det syntaktiskt korrekt, men innehållsmässigt är det ett fel . Om det senare visar sig att du nu behöver gå in nytt nummer pass, men redan "123 ABC", så kommer programmet att vägra att göra detta, eftersom ett sådant nummer redan finns. Och det är okänt vad man ska korrigera det för, eftersom dokumenten från vilket det skrevs inte längre finns.
För det andra (och kanske ännu viktigare) tenderar informationen att förändras. Till exempel, för inte så länge sedan byttes pass in Ryska Federationen och om programmet förlitade sig på sitt nummer som en identifierare, så har nu allt hamnat i stor oordning i samband med denna ersättning
Återigen, för inte så länge sedan introducerades de så kallade "Taxpayer Identification Numbers" i Ryska federationen. Det så kallade "TIN". Tja, det verkar, ja, detta är den unika identifieraren för motparten. Men vår inhemska byråkrati lyckades förstöra allt även här. Det visade sig att TIN bryter mot alla unika kriterier på grund av vissa funktioner i dess bildande
På en av konferenserna uttryckte sig en av besökarna ganska känslomässigt om detta
Jag ger företräde åt SK helt enkelt för att SK ger användaren möjlighet att bestämma, Ivanov I.I. och Petrov I.I. - samma person eller olika. Kanske bytte han sitt efternamn, kanske till och med sitt kön, kanske ändrade han både typ av pass och dess nummer. Kanske bytte han medborgarskap, återvände från kriget utan armar, ben och huvud, födde barn, genomgick plastikoperationer för att ändra sin vikt... Men detta hindrade honom inte från att vara sig själv.
Således, i det allmänna fallet, ger en naturlig nyckel inte det viktigaste - entydig identifiering av en post genom nyckelfältets värde. Och om det ger det, så slutar det att vara naturligt i ordets ursprungliga bemärkelse, eftersom det tvingar användaren att anpassa sig och undvika.
Så varför, trots så uppenbara argument emot, finns det fortfarande tillräckligt Ett stort antal anhängare av att använda en naturlig nyckel?
Enligt min mening finns här ett tydligt missförstånd att en surrogatnyckel är information som inte ges till användaren någonstans, på något sätt. En surrogatnyckel är några dolda "interna" mekaniker som är osynliga för användaren.
Faktum är att huvudargumentet för anhängare av den naturliga nyckeln är dess "förståelighet" för användaren. De där. det antas att användaren letar efter något baserat på nyckelfältets värde. Med andra ord, användaren själv anger, korrigerar och ser värdet på nyckelfältet.
Men i förhållande till surrogatnyckeln är sådan användning helt enkelt oacceptabel! Tja, användaren borde inte veta hur allt "tickar" inuti programmet. Användaren är intresserad av klockavläsningarna och inte alla "växlar". Om du vill ge användaren en viss förkortning (kort namn, "smeknamn"), bör det inte i något fall vara en surrogatnyckel. Ange ytterligare ett fält för detta ändamål.
Det finns ett annat, mer listigt argument till förmån för åtminstone delvis användning av naturliga nycklar. Faktum är att det väldigt ofta finns ett behov av några intern klassificering. Tja, till exempel, om vi pratar om dokument, kan de vara i vissa ömsesidigt uteslutande tillstånd:
Det finns en mycket stor frestelse att inte skapa en extra tabell med dessa 3 poster, utan helt enkelt använda koderna 1,2,3 Ja, egentligen kan användaren inte ändra antalet och namnet på stater. Det är här anhängare av den naturliga nyckeln höjer sina röster - de säger att vissa siffror säger till programmeraren, låt honom skriva orden direkt
I det här fallet skulle jag personligen rekommendera att inte ge efter för frestelsen att "förenkla" databasen och införa en extra serviceskylt med 3 statusposter. Även om användaren inte har möjlighet att redigera den. Du kommer själv att se hur relevant det blir, och i vissa fall helt enkelt oersättligt när du skriver ditt program.
Slutsatsen är tydlig - surrogatnycklar är att föredra enligt alla kriterier framför naturliga nycklar
Vilken datatyp ska användas: Karaktär eller Heltal
Tidigare när FoxPro bara hade fält som Numeriskövervikten av argumentet lutade åt att använda fält som Karaktär, men med tillkomsten av fält som Heltal allt är inte så klart
När man jämför hur man lagrar ett nyckelfält i tecken- eller numeriskt format, läggs 3 argument fram
Numeriska fält är lättare att skapa
Här har numeriska fält ingen konkurrens, eftersom standardsättet att skapa numeriska nyckelfält är "maximalt värde plus ett." När det gäller teckenfält används som regel någon slags pseudo-slumptalsgenerator. Det här är inte platsen att diskutera hur symboliska nycklar genereras, men de procedurer som används är vanligtvis ganska komplexa på grund av svårigheten att säkerställa ett verkligt unikt värde.
Jag noterar också att du inte bör använda definitionen för att generera ett nytt nyckelvärde maximalt värde i den aktuella tabellen. Detta är bra i enanvändarläge, men i fleranvändarläge riskerar du att få 2 identiska nyckelvärden när du lägger till samtidigt ny ingång två användare samtidigt. Vanligtvis används en speciell servicetabell som lagrar värdet för det senast använda (eller första oanvända) nyckelvärdet. Exempel på användning av en sådan tabell ges i vanliga FoxPro-exempelprojekt: Solution.pjx(form Nytt ID.scx) Och TasTrade.pjx. Och i version 8 dök FoxPro upp automatiskt ökande fält, vilket helt förenklade denna uppgift.
Karaktärsfält är "mer ekonomiska", d.v.s. kan passa fler värden i samma storlek
Låt oss börja med frågan: hur många värden behövs för att identifiera alla poster i en tabell?
Det är känt från systembegränsningar att det maximalt tillåtna antalet poster i en DBF-tabell är 1 miljard poster. De där. detta är en och nio nollor
Ett heltalsfält kan acceptera värden i intervallet från -2,147,483,647 till 2,147,483,647. Tja, negativa värden används i allmänhet inte, men positiva värden är 2 gånger större än det maximalt möjliga antalet poster. Med hänsyn till eventuell radering av poster - helt rätt.
Eftersom fältet är typ Heltal fysiskt tar 4 byte (4 tecken), låt oss sedan se hur många värden som kan tilldelas med samma storlek för ett teckenfält
En byte kan innehålla 256 värden, dvs. detta blir 256**4=4,294,967,296. Men eftersom vissa värden inte kan användas av ett antal skäl (till exempel radmatning, Esc, etc.), visar det sig att när det gäller antalet fälttypvärden Heltalär inte på något sätt sämre än ett fält som Karaktär(4), kanske till och med något överlägsen
Kommentar
Det bör noteras att i FoxPro-fält som Numerisk lagras som teckenfält, dvs. Varje siffra behöver en byte att lagra. Detta betyder att om det förväntade antalet värden i en given tabell inte överstiger tusen (mindre än 4 tecken), så finns det en frestelse att "spara" och istället för att skriva Heltal ange, säg, ett fält av typen N(2)
Så jag skulle inte rekommendera att du gör detta av följande skäl:
Teckenfält är "mer universella" för så kallade replikeringsuppgifter
Replikering- detta är kombinationen av information från två orelaterade databaser, till exempel från två grenar av en organisation geografiskt avlägsen vän från vän
Ja, faktiskt, i sådana uppgifter är det mer bekvämt att använda symboliska fält, även om även i en sådan till synes uppenbart förlorande situation har numeriska fält något att "invända"
Det här är inte platsen att diskutera detta problem på grund av dess omfattande, så jag kommer bara att notera att för ett mycket stort antal problem är replikeringsproblemet i sig inte relevant. Antingen använd filserverteknik, eller konsolidering är endast nödvändig i en riktning för att få certifikat och rapporter
Slutsatsen är inte lika kategorisk som i fallet med surrogatnycklar:
Men eftersom de flesta programmerare inte kommer att behöva ta itu med replikeringsuppgifter, kan du säkert använda typen Heltal.
Är det nödvändigt att använda ett nyckelfält i alla tabeller utan undantag?
Vid första anblicken kan frågan tyckas märklig. Är det möjligt utan ett nyckelfält? Det visar sig att det i vissa fall är möjligt.
Till exempel, för att organisera en många-till-många-relation, är standardsättet att skapa en proxytabell. Vad menas?
Låt oss säga att du har en lista över motparter och en lista över banker. Självklart kan samma motpart ha ett konto i flera banker. Men det är också tvärtom – en bank samarbetar med flera motparter. I det här fallet kan du inte skapa en utländsk banknyckel i motpartstabellen eller en motpartsutländsk nyckel i banktabellen. Du måste ange en mellanhandstabell som lagrar bankens främmande nyckel och motpartens främmande nyckel.
Med denna organisation identifieras varje post i denna mellanliggande tabell unikt av ett par värden: motpartskod - bankkod. Därför är det frestande att inte införa ytterligare ett fält för surrogatnyckeln till denna proxytabell.
Om vi återgår till exemplet med motparter och banker är det lätt att märka att jag struntade i att en motpart kan ha flera konton i samma bank. Just denna detalj (motpartens bankkonto) kan inte kopplas till vare sig banken eller motparten. Men han passar detta mellanbord väldigt bra. Om du, för att identifiera en post i den här tabellen, litade på paret: bankkod - motpartskod, måste du seriöst göra om en betydande del av programmet. Och har du en egen inspelningskod är det inga problem. Tja, de lade till ytterligare ett fält, så vad?
I det här fallet tittade jag på ett ganska uppenbart fall, men det verkar ofta som att det inte kan vara annorlunda, och det är här som din egen postidentifierare inte behövs. Smickra inte dig själv. Om det verkar för dig att något inte kan hända betyder det bara att du inte vet något.
Slutsats - använd ditt eget nyckelfält i alla tabeller utan undantag. Även om det verkar som att du klarar dig utan det.
Namn på nyckelfält
Eftersom den nyckelfält är ett normalt tabellfält, då gäller alla rekommendationer som ges i avsnittet "Tabellfält". Men eftersom detta fortfarande är ett mycket specifikt område, skulle jag lägga till följande rekommendationer för det:
Arbetar faktiskt med tabellens nyckelfält
Denna strategi gör det mycket lättare att fånga användarfel, för i de flesta fall, om användaren gör ett misstag i ett dokument, korrigerar han inte det felaktiga dokumentet, utan tar bort det och skapar det igen! Bevisa då att detta inte är ett dåligt program!
Dessutom gör denna strategi det möjligt att integrera flera databaser i ett komplex med mindre problem om behov uppstår.
Faktum är att all information som användaren anger är per definition opålitlig och oavsett hur du skyddar informationen, användaren hittar hur man kommer runt det eller bara tvingar dig att göra det! Och vad han inte misstänker och inte kan förstöra.
Till exempel är det i vissa fall frestande att använda nyckelfält också som serienummer för ett element i en lista. Så du behöver inte göra detta. Ange ett ytterligare fält för att implementera den här funktionen. Du bör inte heller använda nyckelfältet som ett kort namn på elementet
Om du lägger till någon annan funktionalitet i nyckelfältet än unik identifiering av poster, kommer du helt enkelt skapa en massa problem för dig själv (programkoden kommer att bli mycket mer komplicerad). Och den enda fördelen är några besparingar disk utrymme. Jag tycker inte att det är värt det.
Publicerad av: Vladimir Maksimov
Tabellläge - mata in data direkt i en tom tabell i
tabellläge. När du sparar en ny tabell i Microsoft Access, data
analyseras och varje fält tilldelas den nödvändiga datatypen och
Designläge - definiera alla tabelllayoutparametrar i
designläge Oavsett vilken metod som används för att skapa
tabeller är det alltid möjligt att använda designläge till
ytterligare ändringar av tabelllayouten, till exempel för att lägga till nya
fält, ställa in standardvärden eller skapa inmatningsmasker.
Tabellguiden - låter dig välja fält för en given tabell från en mängd olika
tidigare definierade tabeller, såsom affärskontakter, en lista över personliga
egendom eller recept.

Importera tabeller - Microsoft Access stöder import av data från tabeller
FoxPro eller Paradox. Microsoft Access tillhandahåller också import
språktabeller och listor (skrivskyddad), som kan placeras på
persondator, på nätverksserver eller på en internetserver.
Vid import av data skapas en kopia av den i en ny tabell i den aktuella databasen
Microsoft Access-data. Den ursprungliga tabellen eller filen är det inte
förändra. Importerad data kan inte läggas till omedelbart
befintliga tabeller (exklusive import av tabeller eller text
filer). Men efter att ha importerat en tabell kan du lägga till data till en annan
tabell med hjälp av en tilläggsfråga.
Det är möjligt att importera inte bara tabeller utan även andra databasobjekt,
till exempel formulär eller rapporter från en annan Microsoft Access-databas.
Förhållande till tabeller - stöder länkning av data från tabeller
andra Microsoft Access-databaser, såväl som data från andra applikationer
och filer i andra format, till exempel Microsoft Excel, dBASE, Microsoft
FoxPro eller Paradox. Databindning tillåter läsning och de flesta
fall av uppdatering av data i en extern datakälla utan att importera den.
Formatet för externa datakällor ändras inte, så filen kan vara det
fortsätta att användas i applikationen där den skapades, men
detta gör det möjligt att lägga till, ta bort eller ändra data i
Microsoft Access.
I Microsoft Access, för att referera till relaterade tabeller och lagrade tabeller
i den aktuella databasen används olika ikoner. Om du tar bort ikonen
länkad tabell raderas länken till tabellen, men inte själva den externa tabellen.
Nyckelfält
Kraften i relationsdatabaser som t.ex Microsoft Access, är att de snabbt kan hitta och koppla data från olika tabeller med hjälp av frågor, formulär och rapporter. För att göra detta måste varje tabell innehålla ett eller flera fält som unikt identifierar varje post i tabellen. Detta kallas tabellnyckelfältet. Om du har nyckelfält avsedda för en tabell, förhindrar Microsoft Access att dubbletter eller tomma värden anges i nyckelfältet.
I Microsoft Access kan du välja tre typer av nyckelfält: räknare, enkel nyckel och sammansatt nyckel.
sidfot i word 2007, 0000001111
Definiera nyckelfält
Begreppet nyckelfält nämndes upprepade gånger ovan. Nyckelfält - Dessa är ett eller flera fält vars kombination av värden unikt identifierar varje post i tabellen. Om en tabell har definierade nyckelfält, förhindrar Microsoft Access att dubbletter eller tomma värden anges i nyckelfältet. Nyckelfält används för snabbsökning och länka data från olika tabeller med hjälp av frågor, formulär och rapporter.
Det finns tre typer av nyckelfält i Microsoft Access: räknare, enkel nyckel och sammansatt nyckel. Låt oss titta på var och en av dessa typer.
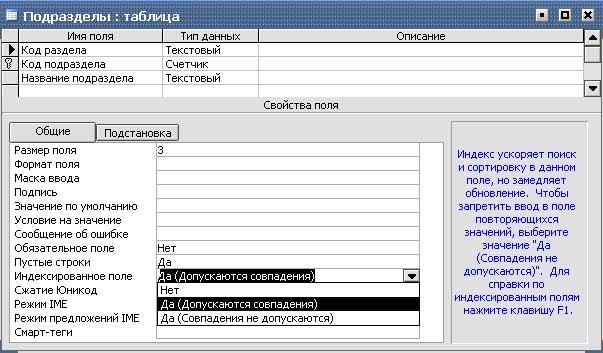
För att skapa ett nyckelfält av typen Räknare måste du använda läget Tabelldesigner:
- Inkludera ett räknarfält i tabellen.
- Ställ in den så att den automatiskt ökar med 1.
- Ange detta fält som ett nyckelfält genom att klicka på knappen Nyckelfält Bordsbyggare(Bordsdesign).
Om nyckelfälten inte definierades innan du sparade den skapade tabellen, kommer ett meddelande att visas när du sparar ett meddelande som indikerar att nyckelfältet har skapats. När knappen trycks ned Ja(Ja) ett räknarnyckelfält med namnet Koda(ID) och datatyp Disken(AutoNumber).
För att skapa enkel nyckel Det räcker med ett fält som innehåller unika värden (till exempel koder eller siffror). Om det valda fältet innehåller dubbletter eller tomma värden kan det inte anges som ett nyckelfält. För att identifiera poster som innehåller dubbletter av data kan du köra en sökfråga för dubbletter av poster. Om du inte kan eliminera dubbletter genom att ändra värden, bör du antingen lägga till ett räknarfält i tabellen och göra det till ett nyckelfält, eller definiera en sammansatt nyckel.
En sammansatt nyckel krävs när en posts unika karaktär inte kan garanteras med ett enda fält. Det är en kombination av flera områden. För att bestämma sammansatt nyckel nödvändig:
- Öppna tabellen i designläge.
- Välj de fält som måste definieras som nyckel.
- tryck på knappen Nyckelfält(Primär nyckel) i verktygsfältet Bordsbyggare(Bordsdesign).
Kommentar För en sammansatt nyckel kan ordningen på fälten som utgör nyckeln vara viktig. Posterna sorteras efter nyckelfältens ordning i fönstret Tabelldesign. Om du behöver ange en annan sorteringsordning utan att ändra ordningen på nyckelfälten måste du först definiera nyckeln och sedan klicka på knappen Index(Index) i verktygsfältet Bordsbyggare(Bordsdesign). Sedan i fönstret som dyker upp Index(Index) måste du ange en annan fältordning för det namngivna indexet Nyckelfält(Primärnyckel).
Som ett exempel på att använda en sammansatt nyckel, betrakta tabellen " Beordrade"(Orderdetaljer) Databas(Nordvind) (Fig. 2.23).
I det här fallet, fälten " Beställningskod" (OrderlD) och " Produktkod" (Produkt-ID), eftersom inget av dessa fält individuellt garanterar postens unika karaktär. I det här fallet visar tabellen inte produktkoden, utan produktnamnet, eftersom fältet " Produktkod" (Produkt-ID) för den här tabellen innehåller en uppslagning från tabellen" Varor"(Produkter) och fältvärden" Produktkod" (Produkt-ID) för dessa tabeller är relaterade av en en-till-många-relation (en tabellpost " Varor"(Produkter) kan matcha flera tabellposter" Beordrade" (OrderDetails). Båda fälten kan innehålla dubbletter av värden. Således kan en beställning innehålla flera produkter, och olika beställningar kan innehålla samma produkter. Samtidigt kan en kombination av fält " Beställningskod" (OrderlD) och " Produktkod"(Produkt-ID) identifierar varje tabellpost unikt" Order"(Orderdetaljer).
1. Vad kan du använda för att skapa tabeller?
Huvudläget är att skapa tabeller med hjälp av Designer. I detta läge kan användaren ställa in parametrarna för alla element i tabellstrukturen.
Tabellguiden genererar automatiskt en tabell med hjälp av en av mallarna. Användaren erbjuds mer än 40 bordsprover att välja mellan. Varje malltabell innehåller en motsvarande uppsättning fält från vilka du kan välja de fält du vill inkludera i tabellen du skapar.
Läge Importera tabeller låter dig överföra tabeller skapade i andra Windows-program till Access-databaser. När du importerar tabeller, tänk på att tabellerna du importerar, t.ex. kalkylblad skapade i Excel, måste ha standardformat databaser, när varje rad är en separat spela in, och kolumnerna är fält.
I Tabellläge användaren kan skapa nytt bord utan att först definiera dess struktur. När du väljer detta läge öppnas en tom tabell där du kan mata in data. Alla fält i den här tabellen kan döpas om enligt användarkrav. Denna metod är användbar för att skapa små tabeller, vars struktur kommer att konfigureras senare. Möjligheterna att skapa tabeller i detta läge är begränsade, och de kräver vanligtvis modifiering i designläge.
2. Vad är ett nyckelfält?Nyckelfält - Dessa är ett eller flera fält vars kombination av värden unikt identifierar varje post i tabellen.
3. Hur ställer jag in flera nyckelfält?
1. Öppna bordet i designläge. 2. markera Obligatoriska fält, klicka på den grå rutan framför fältnamnet samtidigt som du håller ner tangenten. Ctrl 3. Klicka på knappen "Nyckelfält" (gul tangent) i verktygsfältet.
4. Hur upprättar man relationer mellan tabeller?
Logiska samband ställs mellan fält med samma namn tabeller Access 2007-databaser Kopplingen av data i en tabell med data i andra tabeller görs genom unika identifierare (nycklar) eller nyckelfält
5. Vilka relationer finns mellan tabeller?
Många-till-många relationer
När man upprättar en många-till-många-relation kan varje rad i tabell A motsvara många rader i tabell B och vice versa. En sådan relation skapas med hjälp av en tredje tabell, kallad en junction-tabell, vars primärnyckel består av främmande nycklar associerade med tabellerna A och B. Till exempel upprättas en många-till-många-relation mellan tabellerna "Authors" och "Books". ”, definierad med relationstyp "en till många" mellan var och en av dessa tabeller och tabellen "Authors of Books". Den primära nyckeln i tabellen BookAuthors är en kombination av kolumnerna "Author_ID" (primärnyckeln i författartabellen) och "Book_ID" (primärnyckeln i titeltabellen).
En-till-en-anslutningar
När man upprättar en en-till-en relation kan varje rad i tabell A endast motsvara en rad i tabell B och vice versa. En en-till-en-relation skapas när båda relaterade kolumnerna är primärnycklar eller har unika begränsningar.
Denna typ av relation används sällan eftersom den data som länkas vanligtvis kan lagras i en enda tabell i denna situation. Du kan använda en en-till-en-relation i följande fall: För att dela en tabell som innehåller för många kolumner. Att isolera en del av en tabell av säkerhetsskäl. För att lagra korttidsanvändningsdata som enklast kan raderas genom att rensa tabellen. För att lagra data som endast är relevant för en delmängd av huvudtabellen. I Microsoft Access representeras sidan av en en-till-en-relation som en primärnyckel motsvarar av en nyckelsymbol. Den part som den främmande nyckeln motsvarar indikeras också med en nyckelsymbol.
Skapa relationer mellan tabeller
När du upprättar en relation mellan tabeller behöver de relaterade fälten inte ha samma namn. De måste dock ha samma datatyp, såvida inte fältet som är primärnyckeln är av typen Counter. Ett Count-fält kan bara associeras med ett numeriskt fält om egenskapen FieldSize för varje är inställd på samma värde. Du kan till exempel länka kolumner av typen Räknare och Numerisk om egenskapen FieldSize för var och en är inställd på Långt heltal. Även om båda kolumnerna som länkas är av typen Numeric, måste egenskapsvärdet FieldSize för båda fälten vara detsamma.
Skapa en-till-många eller en-till-en relationer
För att skapa en en-till-många- eller en-till-en-relation använder du följande steg:
1. Stäng alla öppna bord. Du kan inte skapa eller ändra relationer mellan öppna tabeller.
2. Följ dessa steg i Access 2002 eller 2003:
a. Tryck på F11 för att gå till databasfönstret. b. Välj kommandot Länkar på Verktyg-menyn.
I Access 2007 klickar du på knappen Länkar på flikarna Visa eller dölj databasverktyg.
3. Om det inte finns några relationer i databasen visas dialogrutan Lägg till tabell automatiskt. Om fönstret Lägg till tabell inte visas, men du fortfarande behöver lägga till tabeller i listan över länkade, väljer du kommandot Lägg till tabell från menyn Länkar.
4. Dubbelklicka på namnen på de tabeller som du vill länka och stäng sedan dialogrutan Lägg till tabell. För att länka en tabell till sig själv, lägg till den två gånger.
5. Dra länkfältet från en tabell till länkfältet i den andra. För att dra flera fält, klicka CTRL-tangenten, klicka på varje ruta och dra dem sedan.
I de flesta fall måste du dra ett primärnyckelfält (visat i fet stil) från en tabell till ett liknande fält (ofta med samma namn), som kallas en främmande nyckel, i en annan tabell.
6. Fönstret Redigera länkar visas. Se till att varje kolumn visar namnen på de obligatoriska fälten. Vid behov kan de ändras.
Ställ in kommunikationsparametrar vid behov. Om du vill ha information om ett specifikt objekt i fönstret Redigera länkar, klicka på frågetecknet och klicka sedan på lämpligt objekt. Dessa alternativ kommer att beskrivas i detalj nedan.
7. För att upprätta en anslutning, klicka på knappen Skapa.
8. Upprepa steg 5 till 8 för varje par av tabeller som länkas.
När du stänger dialogrutan Redigera länkar frågar Microsoft Access om du vill spara layouten. Oavsett svaret på denna fråga sparas de skapade anslutningarna i databasen.
Notera. Du kan skapa relationer inte bara i tabeller utan även i frågor. Detta säkerställer dock inte dataintegriteten.
Skapa många-till-många-relationer
Följ dessa steg för att skapa en många-till-många-relation:
1. Skapa två tabeller som måste vara relaterade i en många-till-många-relation.
2. Skapa en tredje tabell, kallad en sammanfogningstabell, och lägg till fält till den med samma definitioner som primärnyckelfälten i var och en av de andra två tabellerna. De primära nyckelfälten i en kopplingstabell fungerar som främmande nycklar. Du kan lägga till andra fält i en sammanfogningstabell, precis som vilken annan tabell som helst.
3. Ställ in den här tabellens primärnyckel så att den inkluderar primärnyckelfälten för båda primära tabellerna. Till exempel kommer den primära nyckeln för BookAuthors join-tabellen att bestå av fälten "Order_ID" och "Product_ID".
Notera. Följ stegen nedan för att skapa en primärnyckel.
a. Öppna tabellen i designvy. b. Välj ett eller flera fält som du vill definiera som primärnyckel. För att välja ett enstaka fält, klicka på radvalstecknet för det önskade fältet.
För att välja flera fält, håll ned CTRL-tangenten och klicka på radvalstecknet för varje fält.
c. Klicka på i Access-versionerna 2002 eller 2003 Primärnyckel på verktygsfältet.
I Access 2007 klickar du på knappen Primärnyckel i gruppen Verktyg på fliken Struktur.
Notera. För att ställa in ordningen på fälten i en primärnyckel med flera fält så att den skiljer sig från ordningen i tabellen, klicka på knappen Index i verktygsfältet, vilket öppnar dialogrutan Index där du kan ändra ordningen på indexfälten, som kallas Nyckelfält.
4. Upprätta en en-till-många-relation mellan var och en av de två huvudtabellerna och kopplingstabellen.
6. Vad betyder "1" och "∞" i datadiagrammet? Förhållandet är hur många gånger ett fält på ena sidan är relaterat till ett fält på den andra.
7. Varför behöver du en ersättningsguide? Substitutionsoperationen låter dig göra det enklare att ange värden i ett fält. Med den här operationen kan du välja fältvärden från en lista. Listan med värden kan antingen vara fast eller ingå i en tabell eller fråga. Uppslagsguiden hjälper dig att skapa en uppslagskolumn för ett fält. Låt oss skapa en uppslagskolumn för fältet Kund-ID i tabellen Varningsdistributionslista. Detta kommer att ge oss möjligheten att, när vi matar in data i denna tabell, inte ange klientkoder som vi inte känner till, utan att välja namnet på den organisation där denna person arbetar från listan.





