Одной из наиболее скрытых функций, в недавнем обновлении Windows 10, является возможность проверить, какие приложения используют ваш графический процессор (GPU). Если вы когда-либо открывали диспетчер задач, то наверняка смотрели на использование вашего ЦП, чтобы узнать, какие приложения наиболее грузят ЦП. В последних обновлениях добавлена аналогичная функция, но для графических процессоров GPU. Это помогает понять, насколько интенсивным является ваше программное обеспечение и игры на вашем графическом процессоре, не загружая программное обеспечение сторонних разработчиков. Есть и еще одна интересная функция, которая помогает разгрузить ваш ЦП на GPU. Рекомендую почитать, как выбрать .
Почему у меня нет GPU в диспетчере задач?
К сожалению, не все видеокарты смогут предоставить системе Windows статистику, необходимую для чтения графического процессора. Чтобы убедиться, вы можете быстро использовать инструмент диагностики DirectX для проверки этой технологии.
- Нажмите "Пуск " и в поиске напишите dxdiag для запуска средства диагностики DirectX.
- Перейдите во вкладку "Экран", справа в графе "драйверы " у вас должна быть модель WDDM больше 2.0 версии для использования GPU графы в диспетчере задач.
Включить графу GPU в диспетчере задач
Чтобы увидеть использование графического процессора для каждого приложения, вам нужно открыть диспетчер задач.
- Нажмите сочетание кнопок Ctrl + Shift + Esc , чтобы открыть диспетчер задач.
- Нажмите правой кнопкой мыши в диспетчере задач на поле пустое "Имя" и отметьте из выпадающего меню GPU. Вы также можете отметить Ядро графического процессора , чтобы видеть, какие программы используют его.
- Теперь в диспетчере задач, справа видна графа GPU и ядро графического процессора.

Просмотр общей производительности графического процессора
Вы можете отслеживать общее использование GPU, чтобы следить за ним при больших нагрузках и анализировать. В этом случае вы можете увидеть все, что вам нужно, на вкладке "Производительность ", выбрав графический процессор.

Каждый элемент графического процессора разбивается на отдельные графики, чтобы дать вам еще больше информации о том, как используется ваш GPU. Если вы хотите изменить отображаемые графики, вы можете щелкнуть маленькую стрелку рядом с названием каждой задачи. На этом экране также отображается версия вашего драйвера и дата, что является хорошей альтернативой использованию DXDiag или диспетчера устройств.

Часто стал появляться вопрос: почему нет GPU ускорения в программе Adobe Media Encoder CC? А то что Adobe Media Encoder использует GPU ускорение, мы выяснили , а также отметили нюансы его использования . Также встречается утверждение: что в программе Adobe Media Encoder CC убрали поддержку GPU ускорения. Это ошибочное мнение и вытекает из того, что основная программа Adobe Premiere Pro CC теперь может работать без прописанной и рекомендованной видеокарты, а для включения GPU движка в Adobe Media Encoder CC, видеокарта должна быть обязательно прописана в документах: cuda_supported_cards или opencl_supported_cards. Если с чипсетами nVidia все понятно, просто берем имя чипсета и вписываем его в документ cuda_supported_cards. То при использовании видеокарт AMD прописывать надо не имя чипсета, а кодовое название ядра. Итак, давайте на практике проверим, как на ноутбуке ASUS N71JQ с дискретной графикой ATI Mobility Radeon HD 5730 включить GPU движок в Adobe Media Encoder CC. Технические данные графического адаптера ATI Mobility Radeon HD 5730 показываемые утилитой GPU-Z:
Запускаем программу Adobe Premiere Pro CC и включаем движок: Mercury Playback Engine GPU Acceleration (OpenCL).
Три DSLR видео на таймлайне, друг над другом, два из них, создают эффект картинка в картинке.

Ctrl+M, выбираем пресет Mpeg2-DVD, убираем черные полосы по бокам с помощью опции Scale To Fill. Включаем также повышеное качество для тестов без GPU: MRQ (Use Maximum Render Quality). Нажимаем на кнопку: Export. Загрузка процессора до 20% и оперативной памяти 2.56 Гбайт.

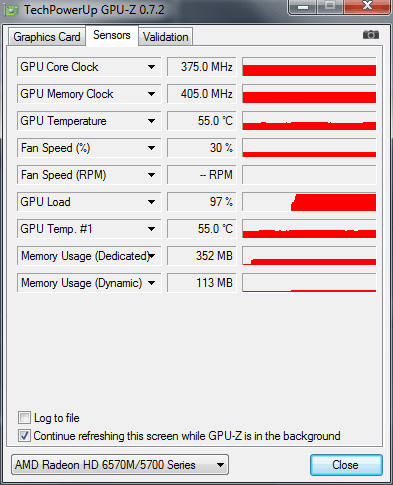
Загрузка GPU чипсета ATI Mobility Radeon HD 5730 составляет 97% и 352Мб бортовой видеопамяти. Ноутбук тестировался при работе от аккумулятора, поэтому графическое ядро / память работают на пониженных частотах: 375 / 810 МГц.
Итоговое время просчета: 1 минута и 55 секунд
(вкл/откл. MRQ при использовании GPU движка, не влияет на итогове время просчета).
При установленной галке Use Maximum Render Quality теперь нажимаем на кнопку: Queue.

Тактовые частоты процессора при работе от аккумулятора: 930МГц.


Запускаем AMEEncodingLog и смотрим итоговое время просчета: 5 минут и 14 секунд .

Повторяем тест, но уже при снятой галке Use Maximum Render Quality, нажимаем на кнопку: Queue.

Итоговое время просчета: 1 минута и 17 секунд .

Теперь включим GPU движок в Adobe Media Encoder CC, запускаем программу Adobe Premiere Pro CC, нажимаем комбинацию клавиш: Ctrl + F12, выполняем Console > Console View и в поле Command вбиваем GPUSniffer, нажимаем Enter.

Выделяем и копируем имя в GPU Computation Info.
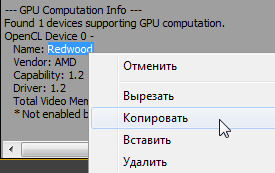
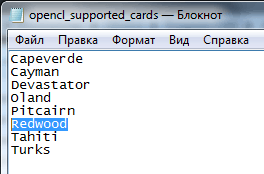
В директории программы Adobe Premiere Pro CC открываем документ opencl_supported_cards, и в алфавитном порядке вбиваем кодовое имя чипсета, Ctrl+S.
Нажимаем на кнопку: Queue, и получаем GPU ускорение просчета проекта Adobe Premiere Pro CC в Adobe Media Encoder CC.

Итоговое время: 1 минута и 55 секунд .

Подключаем ноутбук к розетке, и повторяем результаты просчетов. Queue, галка MRQ снята, без включения движка, загрузка оперативной памяти немного подросла:

Тактовые частоты процессора: 1.6ГГц при работе от розетки и включении режима: Высокая производительность.

Итоговое время: 46 секунд .

Включаем движок: Mercury Playback Engine GPU Acceleration (OpenCL), как видно от сети ноутбучная видеокарта работает на своих базовых частотах, загрузка GPU в Adobe Media Encoder CC достигает 95%.
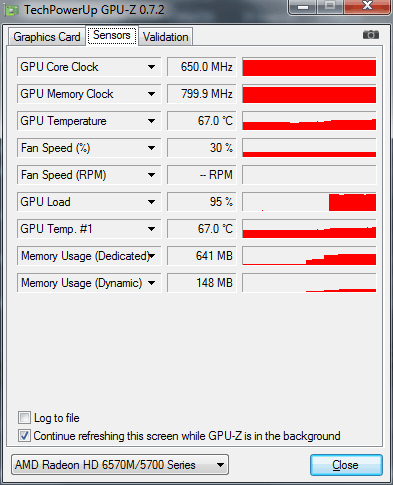
Итоговое время просчета, снизилось с 1 минуты 55 секунд , до 1 минуты и 5 секунд .

*Для визуализации в Adobe Media Encoder CC теперь используется графический процессор (GPU). Поддерживаются стандарты CUDA и
OpenCL. В Adobe Media Encoder CC, движок GPU используется для следующих процессов визуализации:
- Изменение четкости (от высокой к стандартной и наоборот).
- Фильтр временного кода.
- Преобразования формата пикселей.
- Расперемежение.
Если визуализируется проект Premiere Pro, в AME используются установки визуализации с GPU, заданные для этого проекта. При этом будут использованы все возможности визуализации с GPU, реализованные в Premiere Pro. Для визуализации проектов AME используется ограниченный набор возможностей визуализации с GPU.
Если последовательность визуализируется с использованием оригинальной поддержки, применяется настройка GPU из AME, настройка проекта игнорируется. В этом случае все возможности визуализации с GPU Premiere Pro используются напрямую в AME.
Если проект содержит VST сторонних производителей, используется настройка GPU проекта. Последовательность кодируется с помощью PProHeadless, как и в более ранних версиях AME. Если флажок Enable Native Premiere Pro Sequence Import (Разрешить импорт исходной последовательности Premiere Pro) снят, всегда используется PProHeadless и настройка GPU.
Читаем про скрытый раздел на системном диске ноутбука ASUS N71JQ.
Разработчику следует научиться эффективно использовать графический процессор устройства (GPU), чтобы приложение не тормозило и не выполняло лишнюю работу.
Настроить параметры GPU визуализации
Если ваше приложение тормозит, значит часть или все кадры обновления экрана обновляются больше чем 16 миллисекунд. Чтобы визуально увидеть обновления кадров на экране, можно на устройстве включить специальную опцию (Profile GPU Rendering).
У вас появится возможность быстро увидеть, сколько времени занимает отрисовка кадров. Напомню, что нужно укладываться в 16 миллисекунд.
Опция доступна на устройствах, начиная с Android 4.1. На устройстве следует активировать режим разработчика. На устройствах с версией 4.2 и выше режим по умолчанию скрыт. Для активации идёт в Настройки | О телефоне и семь раз щёлкаем по строке Номер сборки .
После активации заходим в Опции разработчика и находим пункт Настроить параметры GPU визуализации (Profile GPU rendering), который следует включить. В всплывающим окне выберите опцию На экране в виде столбиков (On screen as bars). В этом случае график будет выводиться поверх запущенного приложения.
Вы можете протестировать не только своё приложение, но и другие. Запустите любое приложение и начинайте работать с ним. Во время работы в нижней части экрана вы увидите обновляемый график. Горизонтальная ось отвечает за прошедшее время. Вертикальная ось показывает время для каждого кадра в миллисекундах. При взаимодействии с приложением, вертикальные полосы рисуются на экране, появляясь слева направо, показывая производительность кадров в течение какого-то времени. Каждый такой столбец представляет собой один кадр для отрисовки экрана. Чем выше высота столбика, тем больше времени уходит на отрисовку. Тонкая зелёная линия является ориентиром и соответствует 16 миллисекундам за кадр. Таким образом, вам нужно стремиться к тому, чтобы при изучении вашего приложения график не выбивался за эту линию.
Рассмотрим увеличенную версию графика.
Зелёная линия отвечает за 16 миллисекунд. Чтобы уложиться в 60 кадров в секунду, каждый столбец графика должен рисоваться ниже этой линии. В каких-то моментах столбец окажется слишком большим и будет гораздо выше зелёной линии. Это означает торможение программы. Каждый столбец имеет голубой, фиолетовый (Lollipop и выше), красный и оранжевый цвета.
Голубой цвет отвечает за время, используемое на создание и обновление View .
Фиолетовая часть представляет собой время, затраченное на передачу ресурсов рендеринга потока.
Красный цвет представляет собой время для отрисовки.
Оранжевый цвет показывает, сколько времени понадобилось процессору для ожидания, когда GPU завершит свою работу. Он и является источником проблем при больших величинах.
Существуют специальные методики для уменьшения нагрузки на графический процессор.
Отладить показатель GPU overdraw
Другая настройка позволяет узнать, как часто перерисовывается один и тот же участок экрана (т.е. выполняется лишняя работа). Опять идём в Опции разработчика и находим пункт Отладить показатель GPU overdraw (Debug GPU Overdraw), который следует включить. В всплывающим окне выберите опцию Показывать зоны наложения (Show overdraw areas). Не пугайтесь! Нкоторые элементы на экране изменят свой цвет.
Вернитесь в любое приложение и понаблюдайте за его работой. Цвет подскажет проблемные участки вашего приложения.

Если цвет в приложении не изменился, значит всё отлично. Нет наложения одного цвета поверх другого.
Голубой цвет показывает, что один слой рисуется поверх нижнего слоя. Хорошо.
Зелёный цвет - перерисовывается дважды. Нужно задуматься об оптимизации.
Розовый цвет - перерисовывается трижды. Всё очень плохо.
Красный цвет - перерисовывается много раз. Что-то пошло не так.
Вы можете самостоятельно проверить своё приложение для поиска проблемных мест. Создайте активность и поместите на неё компонент TextView . Присвойте корневому элементу и текстовой метке какой-нибудь фон в атрибуте android:background . У вас получится следующее: сначала вы закрасили одним цветом самый нижний слой активности. Затем поверх неё рисуется новый слой от TextView . Кстати, на самом TextView рисуется ещё и текст.
В каких-то моментах наложения цветов не избежать. Но представьте себе, что вы таким же образом установили фон для списка ListView , который занимает все площадь активности. Система будет выполнять двойную работу, хотя нижний слой активности пользователь никогда не увидит. А если вдобавок вы создадите ещё и собственную разметку для каждого элемента списка со своим фоном, то вообще получите перебор.
Маленький совет. Поместите после метода setContentView() вызов метода, который уберёт перирисовку экрана цветом темы. Это поможет убрать одно лишнее наложение цвета:
GetWindow().setBackgroundDrawable(null);
Вычисления на графических процессорах
Технология CUDA (англ. Compute Unified Device Architecture) - программно-аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU (произвольных вычислений на видеокартах). Архитектура CUDA впервые появились на рынке с выходом чипа NVIDIA восьмого поколения - G80 и присутствует во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, ION, Quadro и Tesla.
CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах NVIDIA и включать специальные функции в текст программы на Cи. CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью, организовывать на нём сложные параллельные вычисления.
История
В 2003 г. Intel и AMD участвовали в совместной гонке за самый мощный процессор. За несколько лет в результате этой гонки тактовые частоты существенно выросли, особенно после выхода Intel Pentium 4.
После прироста тактовых частот (между 2001 и 2003 гг. тактовая частота Pentium 4 удвоилась с 1,5 до 3 ГГц), а пользователям пришлось довольствоваться десятыми долями гигагерц, которые вывели на рынок производители (с 2003 до 2005 гг.тактовые частоты увеличились 3 до 3,8 ГГц).
Архитектуры, оптимизированные под высокие тактовые частоты, та же Prescott, так же стали испытывать трудности, и не только производственные. Производители чипов столкнулись с проблемами преодоления законов физики. Некоторые аналитики даже предрекали, что закон Мура перестанет действовать. Но этого не произошло. Оригинальный смысл закона часто искажают, однако он касается числа транзисторов на поверхности кремниевого ядра. Долгое время повышение числа транзисторов в CPU сопровождалось соответствующим ростом производительности - что и привело к искажению смысла. Но затем ситуация усложнилась. Разработчики архитектуры CPU подошли к закону сокращения прироста: число транзисторов, которое требовалось добавить для нужного увеличения производительности, становилось всё большим, заводя в тупик.
Причина, по которой производителям GPU не столкнулись с этой проблемой очень простая: центральные процессоры разрабатываются для получения максимальной производительности на потоке инструкций, которые обрабатывают разные данные (как целые числа, так и числа с плавающей запятой), производят случайный доступ к памяти и т.д. До сих пор разработчики пытаются обеспечить больший параллелизм инструкций - то есть выполнять как можно большее число инструкций параллельно. Так, например, с Pentium появилось суперскалярное выполнение, когда при некоторых условиях можно было выполнять две инструкции за такт. Pentium Pro получил внеочередное выполнение инструкций, позволившее оптимизировать работу вычислительных блоков. Проблема заключается в том, что у параллельного выполнения последовательного потока инструкций есть очевидные ограничения, поэтому слепое повышение числа вычислительных блоков не даёт выигрыша, поскольку большую часть времени они всё равно будут простаивать.
Работа GPU относительно простая. Она заключается в принятии группы полигонов с одной стороны и генерации группы пикселей с другой. Полигоны и пиксели независимы друг от друга, поэтому их можно обрабатывать параллельно. Таким образом, в GPU можно выделить крупную часть кристалла на вычислительные блоки, которые, в отличие от CPU, будут реально использоваться.

GPU отличается от CPU не только этим. Доступ к памяти в GPU очень связанный - если считывается тексель, то через несколько тактов будет считываться соседний тексель; когда записывается пиксель, то через несколько тактов будет записываться соседний. Разумно организуя память, можно получить производительность, близкую к теоретической пропускной способности. Это означает, что GPU, в отличие от CPU, не требуется огромного кэша, поскольку его роль заключается в ускорении операций текстурирования. Всё, что нужно, это несколько килобайт, содержащих несколько текселей, используемых в билинейных и трилинейных фильтрах.
Первые расчёты на GPU
Самые первые попытки такого применения ограничивались использованием некоторых аппаратных функций, таких, как растеризация и Z-буферизация. Но в нынешнем веке, с появлением шейдеров, начали ускорять вычисления матриц. В 2003 г. на SIGGRAPH отдельная секция была выделена под вычисления на GPU, и она получила название GPGPU (General-Purpose computation on GPU) - универсальные вычисления на GPU).
Наиболее известен BrookGPU - компилятор потокового языка программирования Brook, созданный для выполнения неграфических вычислений на GPU. До его появления разработчики, использующие возможности видеочипов для вычислений, выбирали один из двух распространённых API: Direct3D или OpenGL. Это серьёзно ограничивало применение GPU, ведь в 3D графике используются шейдеры и текстуры, о которых специалисты по параллельному программированию знать не обязаны, они используют потоки и ядра. Brook смог помочь в облегчении их задачи. Эти потоковые расширения к языку C, разработанные в Стэндфордском университете, скрывали от программистов трёхмерный API, и представляли видеочип в виде параллельного сопроцессора. Компилятор обрабатывал файл.br с кодом C++ и расширениями, производя код, привязанный к библиотеке с поддержкой DirectX, OpenGL или x86.
Появление Brook вызвал интерес у NVIDIA и ATI и в дальнейшем, открыл целый новый его сектор - параллельные вычислители на основе видеочипов.
В дальнейшем, некоторые исследователи из проекта Brook перешли в команду разработчиков NVIDIA, чтобы представить программно-аппаратную стратегию параллельных вычислений, открыв новую долю рынка. И главным преимуществом этой инициативы NVIDIA стало то, что разработчики отлично знают все возможности своих GPU до мелочей, и в использовании графического API нет необходимости, а работать с аппаратным обеспечением можно напрямую при помощи драйвера. Результатом усилий этой команды стала NVIDIA CUDA.
Области применения параллельных расчётов на GPU
При переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз, по сравнению с быстрыми универсальными процессорами. Самые большие цифры (порядка 100-кратного ускорения и даже более!) достигаются на коде, который не очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для GPU.
Это лишь некоторые примеры ускорений синтетического кода на GPU против SSE-векторизованного кода на CPU (по данным NVIDIA):
Флуоресцентная микроскопия: 12x.
Молекулярная динамика (non-bonded force calc): 8-16x;
Электростатика (прямое и многоуровневое суммирование Кулона): 40-120x и 7x.
Таблица, которую NVIDIA, показывает на всех презентациях, в которой показывается скорость графических процессоров относительно центральных.

Перечень основных приложений, в которых применяются вычисления на GPU: анализ и обработка изображений и сигналов, симуляция физики, вычислительная математика, вычислительная биология, финансовые расчёты, базы данных, динамика газов и жидкостей, криптография, адаптивная лучевая терапия, астрономия, обработка звука, биоинформатика, биологические симуляции, компьютерное зрение, анализ данных (data mining), цифровое кино и телевидение, электромагнитные симуляции, геоинформационные системы, военные применения, горное планирование, молекулярная динамика, магнитно-резонансная томография (MRI), нейросети, океанографические исследования, физика частиц, симуляция свёртывания молекул белка, квантовая химия, трассировка лучей, визуализация, радары, гидродинамическое моделирование (reservoir simulation), искусственный интеллект, анализ спутниковых данных, сейсмическая разведка, хирургия, ультразвук, видеоконференции.
Преимущества и ограничения CUDA
С точки зрения программиста, графический конвейер является набором стадий обработки. Блок геометрии генерирует треугольники, а блок растеризации - пиксели, отображаемые на мониторе. Традиционная модель программирования GPGPU выглядит следующим образом:

Чтобы перенести вычисления на GPU в рамках такой модели, нужен специальный подход. Даже поэлементное сложение двух векторов потребует отрисовки фигуры на экране или во внеэкранный буфер. Фигура растеризуется, цвет каждого пикселя вычисляется по заданной программе (пиксельному шейдеру). Программа считывает входные данные из текстур для каждого пикселя, складывает их и записывает в выходной буфер. И все эти многочисленные операции нужны для того, что в обычном языке программирования записывается одним оператором!
Поэтому, применение GPGPU для вычислений общего назначения имеет ограничение в виде слишком большой сложности обучения разработчиков. Да и других ограничений достаточно, ведь пиксельный шейдер - это всего лишь формула зависимости итогового цвета пикселя от его координаты, а язык пиксельных шейдеров - язык записи этих формул с Си-подобным синтаксисом. Ранние методы GPGPU являются хитрым трюком, позволяющим использовать мощность GPU, но без всякого удобства. Данные там представлены изображениями (текстурами), а алгоритм - процессом растеризации. Нужно особо отметить и весьма специфичную модель памяти и исполнения.
Программно-аппаратная архитектура для вычислений на GPU компании NVIDIA отличается от предыдущих моделей GPGPU тем, что позволяет писать программы для GPU на настоящем языке Си со стандартным синтаксисом, указателями и необходимостью в минимуме расширений для доступа к вычислительным ресурсам видеочипов. CUDA не зависит от графических API, и обладает некоторыми особенностями, предназначенными специально для вычислений общего назначения.
Преимущества CUDA перед традиционным подходом к GPGPU вычислениям
CUDA обеспечивает доступ к разделяемой между потоками памяти размером в 16 Кб на мультипроцессор, которая может быть использована для организации кэша с широкой полосой пропускания, по сравнению с текстурными выборками;
Более эффективная передача данных между системной и видеопамятью;
Отсутствие необходимости в графических API с избыточностью и накладными расходами;
Линейная адресация памяти, и gather и scatter, возможность записи по произвольным адресам;
Аппаратная поддержка целочисленных и битовых операций.
Основные ограничения CUDA:
Отсутствие поддержки рекурсии для выполняемых функций;
Минимальная ширина блока в 32 потока;
Закрытая архитектура CUDA, принадлежащая NVIDIA.
Слабыми местами программирования при помощи предыдущих методов GPGPU является то, что эти методы не используют блоки исполнения вершинных шейдеров в предыдущих неунифицированных архитектурах, данные хранятся в текстурах, а выводятся во внеэкранный буфер, а многопроходные алгоритмы используют пиксельные шейдерные блоки. В ограничения GPGPU можно включить: недостаточно эффективное использование аппаратных возможностей, ограничения полосой пропускания памяти, отсутствие операции scatter (только gather), обязательное использование графического API.
Основные преимущества CUDA по сравнению с предыдущими методами GPGPU вытекают из того, что эта архитектура спроектирована для эффективного использования неграфических вычислений на GPU и использует язык программирования C, не требуя переноса алгоритмов в удобный для концепции графического конвейера вид. CUDA предлагает новый путь вычислений на GPU, не использующий графические API, предлагающий произвольный доступ к памяти (scatter или gather). Такая архитектура лишена недостатков GPGPU и использует все исполнительные блоки, а также расширяет возможности за счёт целочисленной математики и операций битового сдвига.
CUDA открывает некоторые аппаратные возможности, недоступные из графических API, такие как разделяемая память. Это память небольшого объёма (16 килобайт на мультипроцессор), к которой имеют доступ блоки потоков. Она позволяет кэшировать наиболее часто используемые данные и может обеспечить более высокую скорость, по сравнению с использованием текстурных выборок для этой задачи. Что, в свою очередь, снижает чувствительность к пропускной способности параллельных алгоритмов во многих приложениях. Например, это полезно для линейной алгебры, быстрого преобразования Фурье и фильтров обработки изображений.
Удобнее в CUDA и доступ к памяти. Программный код в графических API выводит данные в виде 32-х значений с плавающей точкой одинарной точности (RGBA значения одновременно в восемь render target) в заранее предопределённые области, а CUDA поддерживает scatter запись - неограниченное число записей по любому адресу. Такие преимущества делают возможным выполнение на GPU некоторых алгоритмов, которые невозможно эффективно реализовать при помощи методов GPGPU, основанных на графических API.
Также, графические API в обязательном порядке хранят данные в текстурах, что требует предварительной упаковки больших массивов в текстуры, что усложняет алгоритм и заставляет использовать специальную адресацию. А CUDA позволяет читать данные по любому адресу. Ещё одним преимуществом CUDA является оптимизированный обмен данными между CPU и GPU. А для разработчиков, желающих получить доступ к низкому уровню (например, при написании другого языка программирования), CUDA предлагает возможность низкоуровневого программирования на ассемблере.
Недостатки CUDA
Один из немногочисленных недостатков CUDA - слабая переносимость. Эта архитектура работает только на видеочипах этой компании, да ещё и не на всех, а начиная с серии GeForce 8 и 9 и соответствующих Quadro, ION и Tesla. NVIDIA приводит цифру в 90 миллионов CUDA-совместимых видеочипов.
Альтернативы CUDA
Фреймворк для написания компьютерных программ, связанных с параллельными вычислениями на различных графических и центральных процессорах. В фреймворк OpenCL входят язык программирования, который базируется на стандарте C99, и интерфейс программирования приложений (API). OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. OpenCL является полностью открытым стандартом, его использование не облагается лицензионными отчислениями.
Цель OpenCL состоит в том, чтобы дополнить OpenGL и OpenAL, которые являются открытыми отраслевыми стандартами для трёхмерной компьютерной графики и звука, пользуясь возможностями GPU. OpenCL разрабатывается и поддерживается некоммерческим консорциумом Khronos Group, в который входят много крупных компаний, включая Apple, AMD, Intel, nVidia, Sun Microsystems, Sony Computer Entertainment и другие.
CAL/IL(Compute Abstraction Layer/Intermediate Language)
ATI Stream Technology - это набор аппаратных и программных технологий, которые позволяют использовать графические процессоры AMD, совместно с центральным процессором, для ускорения многих приложений (не только графических).
Областями применения ATI Stream являются приложения, требовательные к вычислительному ресурсу, такие, как финансовый анализ или обработка сейсмических данных. Использование потокового процессора позволило увеличить скорость некоторых финансовых расчётов в 55 раз по сравнению с решением той же задачи силами только центрального процессора.
Технологию ATI Stream в NVIDIA не считают очень сильным конкурентом. CUDA и Stream - это две разные технологии, которые стоят на различных уровнях развития. Программирование для продуктов ATI намного сложнее - их язык скорее напоминает ассемблер. CUDA C, в свою очередь, гораздо более высокоуровневый язык. Писать на нём удобнее и проще. Для крупных компаний-разработчиков это очень важно. Если говорить о производительности, то можно заметить, что её пиковое значение в продуктах ATI выше, чем в решениях NVIDIA. Но опять всё сводится к тому, как эту мощность получить.
DirectX11 (DirectCompute)
Интерфейс программирования приложений, который входит в состав DirectX - набора API от Microsoft, который предназначен для работы на IBM PC-совместимых компьютерах под управлением операционных систем семейства Microsoft Windows. DirectCompute предназначен для выполнения вычислений общего назначения на графических процессорах, являясь реализацией концепции GPGPU. Изначально DirectCompute был опубликован в составе DirectX 11, однако позже стал доступен и для DirectX 10 и DirectX 10.1.
NVDIA CUDA в российской научной среде.
По состоянию на декабрь 2009 г., программная модель CUDA преподается в 269 университетах мира. В России обучающие курсы по CUDA читаются в Московском, Санкт-Петербургском, Казанском, Новосибирском и Пермском государственных университетах, Международном университете природы общества и человека "Дубна", Объединённом институте ядерных исследований, Московском институте электронной техники, Ивановском государственном энергетическом университете, БГТУ им. В. Г. Шухова, МГТУ им. Баумана, РХТУ им. Менделеева, Российском научном центре "Курчатовский институт", Межрегиональном суперкомпьютерном центре РАН, Таганрогском технологическом институте (ТТИ ЮФУ).
Ядер много не бывает…
Современные GPU – это монструозные шустрые бестии, способные пережевывать гигабайты данных. Однако человек хитер и, как бы не росли вычислительные мощности, придумывает задачи все сложнее и сложнее, так что приходит момент когда с грустью приходиться констатировать – нужна оптимизацию 🙁
В данной статье описаны основные понятия, для того чтобы было легче ориентироваться в теории gpu-оптимизации и базовые правила, для того чтобы к этим понятиям, приходилось обращаться по-реже.
Причины по которой GPU эффективны для работы с большими объемами данных, требующих обработки:
- у них большие возможности по параллельному исполнению задач (много-много процессоров)
- высокая пропускная способность у памяти
Пропускная способность памяти (memory bandwidth) – это сколько информации – бит или гигабайт – может может быть передано за единицу времени секунду или процессорный такт.
Одна из задач оптимизации – задействовать по максимуму пропускную способность – увеличить показатели throughput (в идеале она должна быть равна memory bandwidth).
Для улучшения использования пропускной способности:
- увеличить объем информации – использовать пропускной канал на полную (например каждый поток работает с флоат4)
- уменьшать латентность – задержку между операциями
Задержка (latency) – промежуток времени между моментами, когда контролер запросил конкретную ячейку памяти и тем моментом, когда данные стали доступны процессору для выполнения инструкций. На саму задержку мы никак повлиять не можем – эти ограничения присутствуют на аппаратном уровне. Именно за счет этой задержки процессор может одновременно обслуживать несколько потоков – пока поток А запросил выделить ему памяти, поток Б может что-то посчитать, а поток С ждать пока к нему придут запрошенные данные.
Как снизить задержку (latency) если используется синхронизация:
- уменьшить число потоков в блоке
- увеличить число групп-блоков
Использование ресурсов GPU на полную – GPU Occupancy
В высоколобых разговорах об оптимизации часто мелькает термин – gpu occupancy или kernel occupancy – он отражает эффективность использования ресурсов-мощностей видеокарты. Отдельно отмечу – если вы даже и используете все ресурсы – это отнюдь не значит что вы используете их правильно.
Вычислительные мощности GPU – это сотни процессоров жадных до вычислений, при создании программы – ядра (kernel) – на плечи программиста ложиться бремя распределения нагрузки на них. Ошибка может привести к тому, что большая часть этих драгоценных ресурсов может бесцельно простаивать. Сейчас я объясню почему. Начать придется издалека.
Напомню, что варп (warp в терминологии NVidia, wavefront – в терминологии AMD) – набор потоков которые одновременно выполняют одну и туже функцию-кернел на процессоре. Потоки, объединенные программистом в блоки разбиваются на варпы планировщиком потоков (отдельно для каждого мультипроцессора) – пока один варп работает, второй ждет обработки запросов к памяти и т.д. Если какие-то из потоков варпа все еще выполняют вычисления, а другие уже сделали все что могли – имеет место быть неэффективное использование вычислительного ресурса – в народе именуемое простаивание мощностей.
Каждая точка синхронизации, каждое ветвление логики может породить такую ситуацию простоя. Максимальная дивергенция (ветвление логики исполнения) зависит от размера варпа. Для GPU от NVidia – это 32, для AMD – 64.
Для того чтобы снизить простой мультипроцессора во время выполнения варпа:
- минимизировать время ожидания барьеров
- минимизировать расхождение логики выполнения в функции-кернеле
Для эффективного решения данной задачи имеет смысл разобраться – как же происходит формирование варпов (для случая с несколькими размерностями). На самом деле порядок простой – в первую очередь по X, потом по Y и, в последнюю очередь, Z.
ядро запускается с блоками размерностью 64×16, потоки разбиваются по варпам в порядке X, Y, Z – т.е. первые 64 элемента разбиваются на два варпа, потом вторые и т.д.

Ядро запускается с блоками размерностью 16×64. В первый варп добавляются первые и вторые 16 элементов, во второй варп – третьи и четвертые и т.д.
Как снижать дивергенцию (помните – ветвление – не всегда причина критичной потери производительности)
- когда у смежных потоков разные пути исполнения – много условий и переходов по ним – искать пути ре-структуризации
- искать не сбалансированную загрузку потоков и решительно ее удалять (это когда у нас мало того что есть условия, дак еще из-за этих условиях первый поток всегда что-то вычисляет, а пятый в это условие не попадает и простаивает)
Как использовать ресурсы GPU по максимуму
Ресурсы GPU, к сожалению, тоже имеют свои ограничения. И, строго говоря, перед запуском функции-кернела имеет смысл определить лимиты и при распределении нагрузки эти лимиты учесть. Почему это важно?
У видеокарт есть ограничения на общее число потоков, которое может выполнять один мультипроцессор, максимальное число потоков в одном блоке, максимальное число варпов на одном процессоре, ограничения на различные виды памяти и т.п. Всю эту информацию можно запросить как программно, через соответствующее API так и предварительно с помощью утилит из SDK. (Модули deviceQuery для устройств NVidia, CLInfo – для видеокарт AMD).
Общая практика:
- число блоков/рабочих групп потоков должно быть кратно количеству потоковых процессоров
- размер блока/рабочей группы должен быть кратен размеру варпа
При этом следует учитывать что абсолютный минимум – 3-4 варпа/вейфронта крутятся одновременно на каждом процессоре, мудрые гайды советуют исходить из соображения – не меньше семи вейфронатов. При этом – не забывать ограничения по железу!
В голове все эти детали держать быстро надоедает, потому для расчет gpu-occupancy NVidia предложила неожиданный инструмент – эксельный(!) калькулятор набитый макросами. Туда можно ввести информацию по максимальному числу потоков для SM, число регистров и размер общей (shared) памяти доступных на потоковом процессоре, и используемые параметры запуска функций – а он выдает в процентах эффективность использования ресурсов (и вы рвете на голове волосы осознавая что чтобы задействовать все ядра вам не хватает регистров).
информация по использованию:
http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/#calculating-occupancy
GPU и операции с памятью
Видеокарты оптимизированы для 128-битных операций с памятью. Т.е. в идеале – каждая манипуляция с памятью, в идеале, должна изменять за раз 4 четырех-байтных значения. Основная неприятность для программиста заключается в том, что современные компиляторы для GPU не умеют оптимизировать такие вещи. Это приходится делать прямо в коде функции и, в среднем, приносит доли-процента по приросту производительности. Гораздо большее влияние на производительность имеет частота запросов к памяти.
Проблема обстоит в следующем – каждый запрос возвращает в ответ кусочек данных размером кратный 128 битам. А каждый поток использует лишь четверть его (в случае обычной четырех-байтовой переменной). Когда смежные потоки одновременно работают с данными расположенными последовательно в ячейках памяти – это снижает общее число обращений к памяти. Называется это явление – объединенные операции чтения и записи (coalesced access – good! both read and write ) – и при верной организации кода (strided access to contiguous chunk of memory – bad! ) может ощутимо улучшить производительность. При организации своего ядра – помните – смежный доступ – в пределах элементов одной строки памяти, работа с элементами столбца – это уже не так эффективно. Хотите больше деталей? мне понравилась вот эта pdf – или гуглите на предмет “memory coalescing techniques “.
Лидирующие позиции в номинации “узкое место” занимает другая операция с памятью – копирование данных из памяти хоста в гпу . Копирование происходит не абы как, а из специально выделенной драйвером и системой области памяти: при запросе на копирование данных – система сначала копирует туда эти данные, а уже потом заливает их в GPU. Скорость транспортировки данных ограничена пропускной способностью шины PCI Express xN (где N число линий передачи данных) через которые современные видеокарты общаются с хостом.
Однако, лишнее копирование медленной памяти на хосте – это порою неоправданные издержки. Выход – использовать так называемую pinned memory – специальным образом помеченную область памяти, так что операционная система не имеет возможности выполнять с ней какие либо операции (например – выгрузить в свап/переместить по своему усмотрению и т.п.). Передача данных с хоста на видеокарту осуществляется без участия операционной системы – асинхронно, через DMA (direct memory access).
И, на последок, еще немного про память. Разделяемая память на мультипроцессоре обычно организована в виде банков памяти содержащих 32 битные слова – данные. Число банков по доброй традиции варьируется от одного поколения GPU к другому – 16/32 Если каждый поток обращается за данными в отдельный банк – все хорошо. Иначе получается несколько запросов на чтение/запись к одному банку и мы получаем – конфликт (shared memory bank conflict ). Такие конфликтные обращения сериализуются и соответственно выполняются последовательно, а не параллельно. Если к одному банку обращаются все потоки – используется “широковещательный” ответ (broadcast ) и конфликта нет. Существует несколько способов эффективно бороться с конфликтами доступа, мне понравилось описание основных методик по избавлению от конфликтов доступа к банкам памяти – .
Как сделать математические операции еще быстрее? Помнить что:
- вычисления двойной точности – это высокая нагрузка операции с fp64 >> fp32
- константы вида 3.13 в коде, по умолчанию, интерпретируется как fp64 если явно не указывать 3.14f
- для оптимизации математики не лишним будет справиться в гайдах – а нет ли каких флажков у компилятора
- производители включают в свои SDK функции, которые используют особенности устройств для достижения производительности (часто – в ущерб переносимости)
Для разработчиков CUDA имеет смысл обратить пристальное внимание на концепцию cuda stream, позволяющих запускать сразу несколько функций-ядер на одному устройстве или совмещать асинхронное копирование данных с хоста на устройство во время выполнения функций. OpenCL, пока, такого функционала не предоставляет 🙁
Утиль для профилирования:
NVifia Visual Profiler – интересная утилитка, анализирует ядра как CUDA так и OpenCL.
P. S. В качестве более пространного руководства по оптимизации, могу порекомендовать гуглить всевозможные best practices guide для OpenCL и CUDA.
- ,



