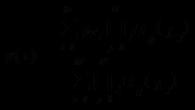В тази статия ще ви разкажа за функцията за бързо търсене 1C Enterprise 8. Какво е бързо търсене?Много просто. Бързото търсене е един от начините за навигация в големи списъци с 1С записи. Това могат да бъдат списъци с документи, директории, регистри - всичко, което е представено от таблици.
Какво е бързо търсене?
Функцията за бързо търсене в документи 1C Enterprise е изключително удобна и ви позволява да не превъртате през огромни количества данни (например с помощта на лента за превъртане), а да отидете директно до желаното място в списъка. За съжаление, начинаещите потребители на 1C Enterprise 8 (включително 1C Accounting 8) отначало не използват възможностите за бързо търсене, предпочитайки да превъртат ръчно списъците с документи (и те могат да бъдат многоголям). Тази статия ще ви помогне да разберете как да използвате бързо търсене в 1С.
На първо място, трябва да се отбележи, че в конфигурациите на 1С Enterprise 8, изградени върху управлявани форми, бързото търсене работи по различен начин, отколкото в предишните версии на 1С. Ето защо ще анализираме отделно използването на бързо търсене в управлявани форми и в обикновени формуляри.
Бързо търсене в 1С Счетоводство 8.2
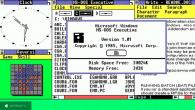
Във версиите на 1С Счетоводство от 8.0 до 8.2функцията е предназначена специално за преходдо желаната част от списъка. Например погледнете прозореца на сметкоплана, показан на фигурата.
Определен ред е маркиран в прозореца. Забележете финия триъгълник от ивици, обозначен с червената стрелка. Както при други програми на Windows, където има списъци (например в Explorer), позицията на този маркер (триъгълник) определя сортирането на списъка като цяло - в коя колона е зададен маркерът, целият списък ще бъде сортиран по тази колона.На фигурата маркерът е в колоната Код, поради което сметките в сметкоплана ще бъдат сортирани по код.
Маркерът може да бъде преместен от една колона в друга, като щракнете върху желаната колона ( на ГЛАВАТА на колоната!) с мишката. Ако маркерът вече е в текущата колона, щракването ще промени посоката на сортиране в противоположната (т.е. от по-голяма на по-малка или обратно). Това е стандартното поведение за всяка програма на Windows. Каква е особеността на този маркер в 1С Enterprise и как е свързан с бързото търсене?
Бързо търсене в списъците на 1С Enterprise 8 се извършва от колоната, в която се намира маркерът.В този случай бързото търсене в сметкоплана ще се извърши от колоната Код.
Това беше важна част от статията, но без JavaScript не се вижда!
Как да използвам бързо търсене в 1С?Лесно! Просто започнете да пишете това, което искате да намерите в ТАЗИ колона, т.е. където е маркерът. В примера на снимката по-горе трябва да се въведе номерът на сметката. Например искате да намерите акаунт 50 Касиер. В този случай въведете ( не е нужно да щраквате никъде!) числото 50 от клавиатурата и ако в тази колона има акаунт с този номер (и разбира се има такъв), тогава списъкът ще премине към този ред и самият ред ще бъде маркиран. Резултатът е показан на екранната снимка на сметкоплана по-долу.

Текстът, посочен със стрелката, е няма нужда да се мие- той самият ще изчезне.
Ако в дадения пример започнете да въвеждате думата „Касиер“, тогава текстът в долната част на прозореца ще бъде въведен и след това изтрит. Това се случва, защото веднага щом Започнетеот въведения низ за бързо търсене престава да съвпада с началото на поне един ред в тази колона, 1C Enterprise заключава, че низът за търсене не е намерен и автоматично го изтрива. Поради това има две правила, които трябва да запомните.
В 1С Enterprise 8 се извършва бързо търсене в началото на реда, т.е. колоната търси съвпадение на въведения текст с началото на един от редовете на тази колона.
Това води до важна препоръка: когато въвеждате данни в директории, именувайте елементите, така че да е удобно да ги търсите с помощта на бързо търсене. Например името на контрагента е по-добре написано като „NameFirm LLC“, отколкото „LLC NameFirmy“. Освен това не трябва да използвате кавички и други ненужни символи в името (говорим за попълване на полето Име във формуляри).
Ако започнете да пишете и той се изтрие, това, което търсите, не е в тази колона!В този случай проверете езика за въвеждане, както и колоната, в която се извършва бързото търсене. Често срещана грешка е, че е избрана грешната колона. Например маркерът е зададен в колоната Код и търсенето се извършва по името на акаунта.
Бързо търсене в 1С Счетоводство 8.3
Сега да видим колко бързо се различава търсенето в 1C Enterprise 8.3. Употребата е много подобна на 8.2, но има една съществена разлика, която трябва да запомните.
В 1C Accounting 8.3, както и във всякакви други конфигурации на управлявани формуляри (същия нов интерфейс), той работи като филтър. Просто казано, в резултат на функцията за бързо търсене, част от списъка укриване.
Как да използваме това, сега ще разберем с вас. Първо, погледнете екранната снимка на прозореца на сметката 1C Accounting 8.3 по-долу.

Както можете да видите, същият маркер е в една от колоните. Търсенето се извършва и от колоната, в която е зададен маркерът. Всичко това остана непроменено. Ако обаче започнете да въвеждате текст (в примера номерът на акаунта), ще се случи следното.

Както можете да видите, полето за търсене просто се отвори автоматично. Същият прозорец ще се отвори, ако щракнете върху бутона за търсене в лентата с инструменти на прозореца (подчертано на фигурата). В резултат на това, когато щракнете върху бутона Намери в прозореца за търсене (скрит зад падащото меню на снимката) или просто Enter, получавате следния резултат.

От това става ясно, че бързото търсене в 1С Счетоводство 8.3 просто оставя видима част от списъка, която отговаря на условията за търсене.В този случай бутонът „Търсене“ изчезва и вместо това се появява обектив с кръст (подчертан на фигурата), когато щракнете върху него, списъкът се връща в първоначалното си състояние (редът, намерен в резултат на бързо търсене, остава маркиран ).
Друга важна характеристика на бързото търсене в 1С Счетоводство 8.3- съвпадение не се търси в началото на ред, както във версия 8.2, но се извършва търсене на съвпадение с която и да е част от редовете в колоната. По този начин, ако контрагентът се нарича „NameFirm LLC“ и при търсене започнете да въвеждате „NameFirm LLC“, тогава редът все пак ще бъде намерен!
Изводи
По този начин, бързото търсене в 1C Accounting 8.2 и по-ранните цели е да превъртите списъка до желания ред, а в 1C Accounting 8.3, бързото търсене работи като обикновен филтър, скривайки частта от списъка, която не ви е необходима.
Има малко механизми за работа със низове в 1C заявки. Първо могат да се добавят редовете. На второ място, можете да вземете подниз от низ. Трето, низовете могат да се сравняват, включително по модел. Това е може би всичко, което можете да направите със струни.
Обединяване на низове
За добавяне на низове в заявка се използва операцията "+". Могат да се сгъват само струни с ограничена дължина.
ИЗБЕРЕТЕ „Име:" + Контрагенти. Име КАТО Колона 1 ОТ Директория. Контрагенти КАТО Контрагенти КЪДЕ Контрагенти. Link = & Link
Функция подниз
СУБСТРАТ (<Строка>, <НачальнаяПозиция>, <Длина>)
Аналог на функцията Environment () от обектния модел. Функцията Substring () може да се приложи към данни от тип низ и ви позволява да изберете фрагмент <Строки> като се започне с номера на знака <НачальнаяПозиция> (символите в низа са номерирани от 1) и дължина <Длина> знаци. Резултатът от оценката на функцията има тип низ с променлива дължина и дължината ще се счита за неограничена, ако <Строка> има неограничена дължина и параметър <Длина> не е постоянна или надвишава 1024.
Ако дължината на низа е по-малка от посочената във втория параметър, функцията ще върне празен низ.
Внимание!Използването на функцията SUBSTRING () за преобразуване на низове с неограничена дължина в низове с ограничена дължина не се препоръчва. По-добре е вместо това да използвате операция за глас като EXPRESS ().
Функция като
Ако трябва да се уверим, че атрибутът на низа отговаря на определени критерии, ние го сравняваме:
ИЗБЕРЕТЕ Контрагенти. Наименование КАТО Колона1 ОТ Директория. Контрагенти КАТО контрагенти КЪДЕ Контрагенти. Име = "Газпром"
Но какво, ако искате по-сложно сравнение? Не просто равенство или неравенство, но като определен модел? Точно за това е създадена функцията LIKE.
LIKE - Оператор за проверка на низ като шаблон. Аналог на LIKE в SQL.
Операторът LIKE ви позволява да сравните стойността на израза, посочен вляво от него, с низа на шаблон, посочен вдясно. Стойността на израза трябва да бъде от тип низ. Ако стойността на израза съвпада с модела, операторът ще доведе до TRUE, в противен случай - FALSE.
Следните символи в низа на шаблона са сервизни символи и имат различно значение от символа на низа:
- % (процента): последователност, съдържаща произволен брой произволни знаци;
- _ (долна черта): един произволен знак;
- […] (Един или повече знака в квадратни скоби): всеки един знак, изброен в квадратни скоби. Изброяването може да съдържа диапазони, например a-z, което означава произволен знак, включен в диапазона, включително краищата на диапазона;
- [^ ...] (В квадратни скоби знак за отрицание, последван от един или повече знака): всеки един символ, различен от изброените след знака за отрицание.
Всеки друг символ означава себе си и не носи никакво допълнително значение. Ако е необходимо да напишете един от изброените знаци като себе си, тогава той трябва да бъде предшестван от<Спецсимвол>... Себе си<Спецсимвол>(всеки подходящ символ) е дефиниран в същия израз след ключовата дума SPECIAL CHARACTER.
Низът е един от примитивните типове данни в системите 1С: Предприятие 8. Променливи с типа линиясъдържат текст.
Стойности на променливи от тип линияса затворени в двойни кавички. Могат да се добавят няколко променливи от този тип.
Per1 = "Word 1";
Per2 = "Word 2";
Per3 = Per1 + "" + Per2;
В крайна сметка На3ще означава „ Word 1 Word 2 ″.
Освен това системите 1С: Предприятие 8 предоставят функции за работа със струни. Нека разгледаме основните от тях:
Въведете низ (<Строка>, <Подсказка>, <Длина>, <Многострочность>) — функцията е предназначена за показване на диалогов прозорец, в който потребителят може да посочи стойността на променлива от типа Линия... Параметър <Строка> е задължително и съдържа името на променливата, към която ще бъде записан въведеният низ. Параметър <Подсказка> по избор е заглавието на диалоговия прозорец. Параметър <Длина> по избор, указва максималната дължина на входния низ. По подразбиране е нула, което означава неограничена дължина. Параметър <Многострочность> по избор. Определя режима на въвеждане за многоредов текст: True - въвеждане на многоредов текст с разделители на редове; False - въвеждане на прост низ.
Низът може да се въведе и да му се даде Unicode символен код:
Символ (<КодСимвола>) — кодът се въвежда като число.
Писмо = символ (1103); // аз
Има и обратна функция, която ви позволява да разберете кода на даден знак.
SymbolCode (<Строка>, <НомерСимвола>) — връща посочения номер на Unicode знак като число.
Функции за преобразуване на букви:
BReg (<Строка>) - преобразува всички символи в низа в главни букви.
HPreg (<Строка>) - преобразува всички символи в низа в малки букви.
Трег (<Строка>) - преобразува всички символи в низ в главни букви. Тоест, първите букви във всички думи се преобразуват в главни букви, а останалите букви се преобразуват в малки букви.
Функции за търсене и замяна на символи в низ:
Да намеря(<Строка>, <ПодстрокаПоиска>) - намира номера на знака на появата на подниза за търсене. Например:
Намери („String“, „Oka“); // 4
Намирам (<Строка>, <ПодстрокаПоиска>, <НаправлениеПоиска>, <НачальнаяПозиция>, <НомерВхождения>) - намира номера на символа на появата на подниза за търсене, номерът на появата е посочен в съответния параметър. В този случай търсенето започва с символ, чийто номер е посочен в параметъра Начална позиция.Търсене е възможно от началото или от края на низа. Например:
Number4 Появи = StrFind ( "Способност за отбрана", "o", посока на търсене. От началото, 1, 4); // 7
PReplace (<Строка>, <ПодстрокаПоиска>, <ПодстрокаЗамены>) - намира всички появявания на подниза за търсене в оригиналния низ и го заменя със заместващия подниз.
StrReplace ("String", "Oka", ""); // Страница
Празен ред (<Строка>) - проверява низа за значими знаци. Ако няма значими знаци или изобщо няма знаци, стойността се връща Вярно... В противен случай - Лъжа.
StrNumber на събитията (<Строка>, <ПодстрокаПоиска>) - изчислява броя на повторенията на подниза за търсене в оригиналния низ.
StrNumber на събитията ( „Учи, учи и учи отново“, "да уча" , "" ) ; // 3
PageTemplate (<Строка>, <ЗначениеПодстановки1>…<ЗначениеПодстановкиN> — замества параметрите в низа по число. Редът трябва да съдържа заместващи маркери от формата: "% 1 ..% N". Маркерите се номерират, започвайки от 1. Ако стойността на параметъра Неопределено, замества се празен низ.
PageTemplate ( „Параметър 1 =% 1, параметър 2 =% 2“, "1" , "2" ) ; // Параметър 1 = 1, Параметър 2 = 2
Функции за преобразуване на низове:
Лъв(<Строка>, <ЧислоСимволов>) - връща първо първите символи от низа.
Отдясно (<Строка>, <ЧислоСимволов>) - връща последните знаци от низа.
Сряда (<Строка>, <НачальныйНомер>, <ЧислоСимволов>) - връща низ с дължина<ЧислоСимволов>като се започне с героя<НачальныйНомер>.
AbbrL (<Строка>) —съкращава незначителни знаци отляво на първия значителен символ в низа.
Съкращение (<Строка>) - отрязва незначителни знаци вдясно от последния значителен знак в низа.
SocrLP (<Строка>) - отрязва незначителни знаци вляво от първия значителен знак в реда и вдясно от последния значителен знак в реда.
StrGetString (<Строка>, <НомерСтроки>) - получава низ от многоредов низ по номер.
Други функции:
StrLength (<Строка>) - връща броя символи в низ.
StrNumber of Lines (<Строка>) - връща броя на редовете в многоредов низ. Редът се счита за нов, ако е отделен от предишния ред с нов ред.
Сравнете (<Строка1>, <Строка2> ) - сравнява два струни, без значение на малки и малки букви. Функцията работи по същия начин като обект Сравнение на ценностите... Се завръща:
- 1 - ако първият ред е по-голям от втория
- -1 - ако вторият ред е по-голям от първия
- 0 - ако низовете са равни
StrCompare ("Първи ред", "Втори ред"); // един
Казвам се Павел Баркетов, работя в Softpoint. Решаваме проблеми за оптимизиране на производителността повече от 10 години. И въпреки големия брой решени проблеми, броят им не намалява, а нараства експоненциално. Обемите на данните се увеличават и задачите за оптимизиране на работата с тези данни стават по-трудни. Този процес е неизбежен.
Тема на статията - нетривиални подходи за оптимизация... Ще бъде взето под внимание два аспекта:
- Първо - търсене на поднизове... Потребителите често го използват и много от тях вероятно вече са изправени пред значително очакване, че търсенето на поднизове не е достатъчно бързо.
- Второ - притежаващи големи документи, като затваряне на месеца, изчисляване на себестойността. Със сигурност мнозина са се сблъсквали с факта, че счетоводителите прекарват тези документи за 5-9 часа, през нощта и след работно време. Най-интересното е, че класическите методи за оптимизация не винаги помагат тук. Ако стартирате измерване на производителността в дебъгера, докато провеждате такива документи, ще видите, че най-много време се изразходва за писане във временни или реални структури - таблици, регистри и т.н. И е невъзможно да се реши този проблем по класически методи.
Търсене по подниз
Първата тема е търсене на поднизове. През тази година срещнах няколко проблема с тази операция. Вие идвате в застрахователната компания, за да подновите полицата, те предлагат да ви намерят по телефонен номер. Ясно е, че това не е класическо търсене по пълния телефонен номер, тъй като потребителят може да въведе номера през осемте, през седемте или нещо друго, следователно те търсят фрагменти от номера. В този случай се използват дългосрочни операции за търсене - в някои ситуации закъснението може да бъде няколко секунди или може да достигне до минути.
Търсене чрез стартиране на знаци

Ще започна с първия пример, когато търсенето се извършва чрез стартиране на знаци. Това е специален случай на търсене на поднизове, когато потребителят със сигурност знае, че стойността на търсенето започва с определени символи.

Търсенето по начални знаци се осъществява в 1С с помощта на командата LIKE(или на английски, LIKE) със стойност със „%“ в края („%“ означава последователност от други знаци). Например, ние търсим:
Име ЛАЙК "ivano%"
Моля, обърнете внимание, че ако имате индекс на това поле във вашата система, тогава в SQL заявката за това търсене ще се използва Index Seekе търсене в индекс.

Условието "LIKE низ за търсене" е еквивалентно на търсене в диапазон от стойности... В специалния случай, когато търсим "ivano%" - това е еквивалентно на търсене в набор от фамилни имена, които започват с "ivano" и завършват с "ivanp" (тъй като символът "p" идва след символа "o" ).

Съвременните оптимизатори независимо преобразуват LIKE заявка в заявка за търсене в диапазон... Следователно, ако имате индекс на това поле във вашата система, ще получите абсолютно същия резултат, когато интерпретирате заявката в SQL термини - оптимизаторът ще представи заявката с LIKE като търсене на диапазон.
По този начин е възможно да се извърши класическо бързо търсене с помощта на Index (Търсене на индекс). С това няма проблеми или можете да ги разрешите по прост начин.
Търсене по запис

Сега нека вземем по-сложен пример, когато не се знае къде точно в низа е желаната ни стойност и се извършва търсене чрез появата на низа. В този случай в заявката „ПОДОБНО“ „%“ стои от двете страни.

Когато преобразуваме такава заявка в SQL, виждаме, че се променя само командата (стойността вече съдържа два "%").

Нека разгледаме отблизо плана за изпълнение. Тук виждаме същия Index Seek, но в този случай той не работи ефективно.
Факт е, че индексът с името на справочника, който разглеждаме, се състои от няколко полета.
- Първият е счетоводният разделител.
- Следващото директно е полето за търсене.
И следователно, когато в плана за изпълнение се показва „Търсене на индекс“, това означава, че търсенето се извършва в първото поле на сепаратора- на слайда по-горе можете да видите това търсенето на желаната от нас стойност Desc абсолютно не се използва.
Какво да правя в тази ситуация? В моята практика много често беше забранено на потребителите да използват заявки за влизане. И в някои случаи самите потребители не са използвали тази функционалност, тъй като времето за изпълнение е много важно, но те трябва да продължат да работят. Следователно те трябваше да излязат по други начини - те избираха в списъците, опитваха се да намерят по първите знаци и т.н.
Но това води до недоволство от функционалността и погрешно възприемане на системата. Потребителят разбира, че системата не може да се справи с нещо и не работи както се очаква. Не е правилно.
Нетривиален подход за решаване на проблема с търсенето на поднизове

Нека сега разгледаме нетривиален подход към решаването на този проблем.
Нека определим редица допустими отклонения:
- Първо, тъй като модерна дисковете са неограничени, да кажем, че имате много дисково пространство, което можете да използвате.
- Второ - потребителят търси не по един или два знака, а по някакъв фрагмент... Например, никой от нас не търси „al“ - това е твърде малко селективност. Търси някаква смислена последователност от знаци. Тук избрахме да потърсим шест знака като пример.

Във формуляра беше записан пример за необходимия низ "alexe" и ние ще го тестваме с негова помощ.

- Да предположим, че имаме поле с фамилията, собственото име и бащиното име на клиент. Първата стъпка е автоматично да се разложи тази стойност на фрагменти от шест знака с изместване на "1"и получаваме масив от фрагменти (виж по-горе), които в същото време винаги принадлежат към желаната стойност. Имаме фрагменти, които потребителят може теоретично да въведе. А именно на последния слайд беше установено, че търсим шест знака. Може да са пет или четири от тях, просто размерът на конструкцията ще бъде по-голям.

- Във втората стъпка ние ние записваме тези набори в отделна структура(това може да е таблица, информационен регистър и т.н.) и получаваме селекция, в която определен фрагмент принадлежи на различни стойности.

- И на третата стъпка, когато търсим по подниз, добавяме допълнително условие И към конструкцията на заявката 1С „ЛАЙК“, което филтрира броя на възможните комбинации и изважда от тази допълнителна структура (може да бъде регистър на информация) всички елементи, към които принадлежат необходимите фрагменти, са линии.
Например потребителят търси клиент с фамилното име "Войници". Това са осем знака, което означава, че ще има три фрагмента с дължина от шест знака, които търсим в структурата на услугата. След това комбинираме всичко това в заявка. По този начин се получава допълнително филтриране.

В резултат на това се отърваваме от знака „%“ (тоест тези фрагменти винаги ще имат знака, от който се нуждаем пред себе си) и при изпълнение на вътрешна заявка ще отиде търсенето на индекса, за което се борихме.

На практика се оказва много интересна история - ускорение с десетки, стотици пъти... Освен това всичко това може да се направи с помощта на 1С, което е много приятно. Няма нужда да пренаписвате логиката, потребителят ще се радва, че заявката му за търсене се е ускорила. В примера ускорението от 4 секунди до 0,05 секунди и ако първоначално изпълнихме заявка за две минути, тя щеше да започне да се изпълнява за по-малко от секунда.
Механизмът, който ви показах, не е някакъв експериментален пример, той вече работи с реални клиенти.
Подготвителни дейности за изпълнение
Сега ще говоря накратко за подготвителните дейности.
- Първо необходимо е регистърът да се попълни с начални стойности... За това трябва да насрочим планиран прозорец.
- След това трябва да наблюдаваме последователността на данните - това означава, трябва да има абонамент за промяна на стойносттатака че тези фрагменти да бъдат автоматично възстановени.
- И последният - добавете стандартен формуляр за търсене.

Попълването на регистрите може да се извърши както с помощта на 1С, така и с помощта на SQL.
Мога да кажа, че попълването на такава структура за 17 милиона стойности отнема около 20-25 минути. Естествено, потребителите в този момент не трябва да променят стойностите на търсенето.



Ако изчислим за един милион стойности някъде около 100 знака по 6 във фрагмент, получаваме някъде 4.7 GB. Трябва да планирате така, че да имате това място. Ако имате например 100 милиона стойности в директорията, тогава трябва да планирате пространството, което ще бъде достъпно на диска.
Необходимостта да се вземат предвид статистическите данни за популярността на фрагменти
Дали този метод винаги ще работи бързо?

Това се влияе от статистика за популярността на фрагменти.
- Например имате фрагмент "алекс", който може да бъде включен в името Алексей, в средното име Алексеевич, в фамилията Алексеенко и т.н. Този фрагмент може да бъде включен в 50-100 хиляди записа.
- И има рядко използвани фрагменти.
Така се появява статистиката за популярността по фрагменти.

отбележи, че ако популярността на фрагментите е ниска (100 елемента), тогава получаваме ускорение от 0,1 секунди.
Ако поднизът е достатъчно популярен (50 хиляди елемента), тогава получаваме деградация, и много повече, отколкото ако нямаше оптимизация.

По този начин, необходимо е да се направи подобрена схема за изпълнение на заявката, в която първо бихме получили стойността на популярността на подзаявката. Това се прави в три до пет реда в 1С. В същото време със сигурност знаем, че ако дадена линия е непопулярна, тогава тя следва първия клон, а ако е популярна, следва втория.

Как работи ускорението? Има заявка за търсене от формуляра, след това се обръщаме към регистъра на информацията със статистика, получаваме елемента и след това избираме какво да използваме - класическа или ускорена заявка.

Сега нека да разгледаме как се изпълнява SQL заявка на SQL сървър.
Слайдът показва опростена диаграма:
- има заявка към оптимизатора;
- разглеждаме статистически данни за полетата, които се използват в заявката;
- ние избираме кой план за изпълнение да използваме, тоест избираме стратегия за изпълнение на заявка (например вложен цикъл).
Как изглежда схемата, която сме внедрили?
- Направихме си индекс... Не стандартен SQL индекс, не 1C индекс, а ваш собствен индекс, който е необходим за решаване на този проблем;
- Освен това те бяха изправени пред факта, че се нуждаят от свои статистика;
- И ти трябва своя оптимизатор, който въз основа на тази статистика решава кой клон да избере.
Въз основа на тази логика можем да кажем, че този процес разкрива значението на целите на индексите, статистиката и оптимизатора.
Кой не е знаел защо трябва да обслужвате статистически данни в SQL, погледнете тази логика и ще разберете, че ако тя е неправилна или ирелевантна, тогава ще преминем към грешния клон. Искането ще се забави. Разбираме защо трябва да обслужваме статистически данни ефективно и правилно - това влияе върху ефективността, индекса.
Ако няма индекс, ще сканираме всички стойности.
По този начин създадохме поне примитивен, но наш собствен оптимизатор. Можем да кажем, че те са усетили „на пръсти“ как MS SQL и други СУБД го правят и са създали свои собствени структури.
Ускоряване на "големи" документи
Преминавайки към втората тема - ускоряване на големи документи.
При производствените задачи често се сблъскваме с някакъв вид рутинни процедури, като затваряне на месеца, докладване на агента, изчисляване на разходите. Тези тежки масивни документи отнемат значително време за попълване и попълване. И когато разгледаме дебъгера и проследим тези операции, виждаме това 1C вмъква стойности ред по ред в някаква таблица и отнема по-голямата част от времето... И нищо не може да се направи по въпроса. Единствената препоръка, която може да се предложи, е да се ускори диска (ефективността на това решение е много съмнителна и изисква предварителен анализ).

Предлагам да се върна към историята и да помисля как е направено в 1С, от 8,0 до 8,3 - това се правеше ред по ред... SQL сървърът анализира заявката всеки път, обработва я, създава план за изпълнение, добавя я, изпраща команда към 1С за успех и получава следващата заявка. И такива заявки стъпка по стъпка бяха изпратени от сървъра за приложения 1С до MS SQL.
Ясно е, че ако имате 40 записа в документа, тогава не би трябвало да има проблеми. Ако имате 10 хиляди или повече записи (има организации, в които има милион записи в нормативни документи), тогава този процес отнема много дълго време. Един запис се обработва много бързо, но в документа има твърде много от тях. Какви са режийните разходи? Към мрежата, за да изпълни заявката, към обратния сигнал, да обработи този сигнал в системата 1С - общо, сумата от четири етапа. Всички етапи са обобщени, умножени по милион линии и получаваме дългите си очаквания. Ясно е, че това не е ужасно.

В 1С, започвайки от 8.3, са направени подобрения. Сега на SQL сървъра се подготвя заявка за вмъкване във временни таблици и информационни регистри и по-нататъшното му изпълнение се извършва с помощта на класически RPC извиквания, самият доставчик на достъп 1C (Native или OLE DB) групира записите и ги вмъква по N реда (обикновено 100 реда).
По този начин се постига ускорение от 30% до 300%. Но това все още не е достатъчно, защото днес имате 10 хиляди реда, утре 20 хиляди реда. Това не е основно решение на проблема, все пак ще се сблъскате с него, но само след шест месеца / година.

Който най-бърза вложкакъм SQL сървър и наистина към която и да е СУБД?
Това е НАПЪЛНО ВЪВЕЖДАНЕ... В 1C се използва BULK INSERT, но за други задачи. Също така бих искал да ускоря работата с "големи" документи чрез консолидиране на INSERT вложки и добавяне на записи в един масив към базата данни на SQL сървъра.

Да видим какъв ефект се постига. В разглеждания пример получихме ускорението е около 5 пъти, но можете да ускорите 10 пъти... На теория основният проблем за това да се ускори значително повече е скоростта на диска. Дискът може да е пречка.
Същото важно е да се помни за такъв критерий като индексите... Ако трябваше да вмъкнем BULK INSERT в таблица, без да актуализираме индексите, тогава бихме получили значително ускорение (води до по-малко от секунда). Тук получаваме 69 секунди поради факта, че всяко вмъкване в таблицата изисква индекс REFRESH.
Във всеки случай този метод ви позволява да постигнете ефект от 5-10 пъти.
Освен това тук не се разглеждат функции като разделяне, разделяне. Ситуацията би могла да се подобри, ако знаехме, че BULK INSERT се вмъква в текущия период и бихме преместили неподходящия в друг дял. Би било още по-ефективно. Оказва се, че ускорението е много добро.
Възможностите за оптимизация са безкрайни
По този начин, възможностите за оптимизация са безкрайни... Единственото нещо е да не се увличате. Преди оптимизацията винаги има смисъл да се изчисли дали предвиденият ефект ще бъде или не. Също така бих посъветвал в някои ситуации да се "издигна" над проблема, да използва не класически методи за оптимизация на заявките, а някои напълно различни, които могат да донесат по-значими резултати.
****************
Тази статия е написана въз основа на резултатите от доклада (), прочетен на конференцията INFOSTART EVENT 2017 COMMUNITY.